Amazon Aurora: On Avoiding Distributed Consensus for I/Os, Commits, and Membership Changes
0x00 引言
这篇Paper是Amazon发表的第二篇关于Aurora的文章,这篇文章讨论的是一些一致性的问题。看这篇文章之前,最好看过了[2],包含了:
We describe the following contributions:
(1) How Aurora performs writes using asynchronous flows, establishes local consistency points, uses consistency points for commit processing, and re-establishes them upon crash recovery. (Section 2)
(2) How Aurora avoids quorum reads and how reads are scaled across replicas. (Section 3)
(3) How Aurora uses quorum sets and epochs to make non-blocking reversible membership changes to process failures, grow storage, and reduce costs. (Section 4)
0x02 高效写
下面的这幅图大概表示了写入的流程,这幅图就是论文[2]的同样的一幅:
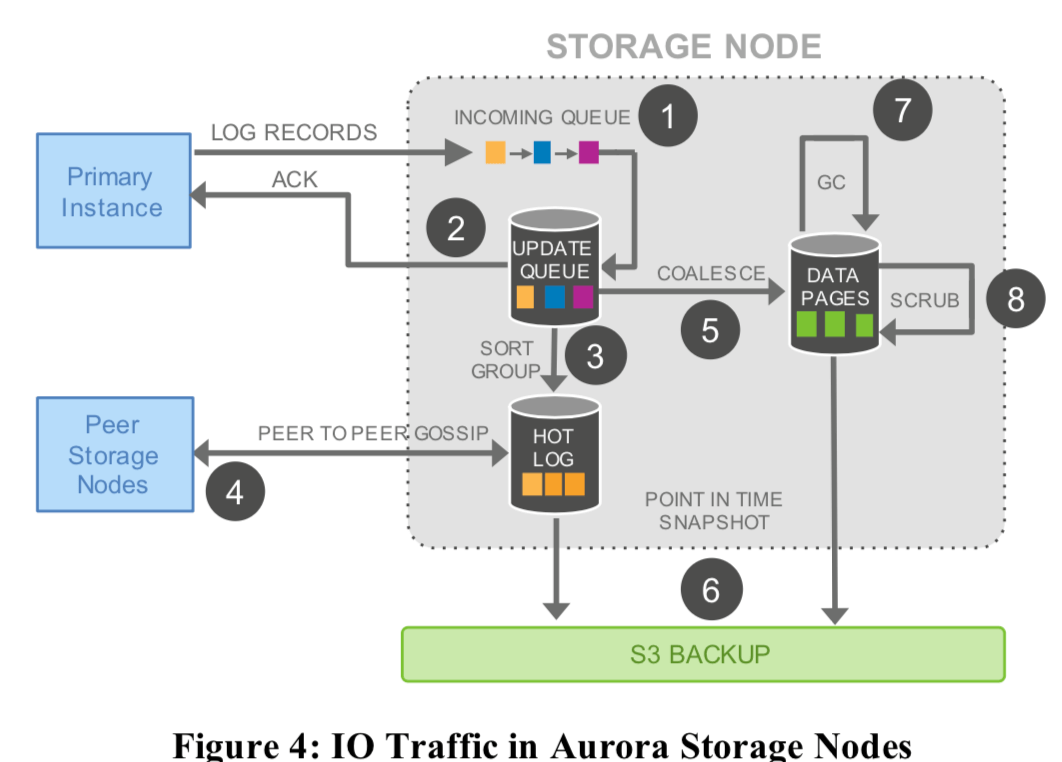
存储结点在接受到一个新的log记录的时候,它可能向前推进它的SCL(Segment Complete LSN,代表了这个结点知道的前面所有的log记录都已经收到的最大的LSN,也就是说在这个SCL记录之前的日志在这个结点上是完整的,不存在gap,这里习相关的一个概念就是Volume Complete LSN(VCL),指的是存储层可以保证可以提供的redo log的最大的LSN,它之前的日志可能存在gap)。SCL会被当作ack的一部分发送给数据库实例,在这个实例收到了超过4个存储结点这个ACK之后,它自己也会将这个PGCL向前推进。在这里要引入Protection Group Complete LSN (PGCL)的概念,代表了一个数据段组(也就是在Aurora中数据分片保存,每个保存6份,这6份叫做一个组)。以下面的图举一个例子,在这些log记录中,级数LSN被保存在PG1钟,偶数的被保存在PG2中,在PG1中,可知它最大的PGCL是103,因为105还没有达到4个的标准,即使107已经达到的也不行。同理在PG2中这个值就是104。
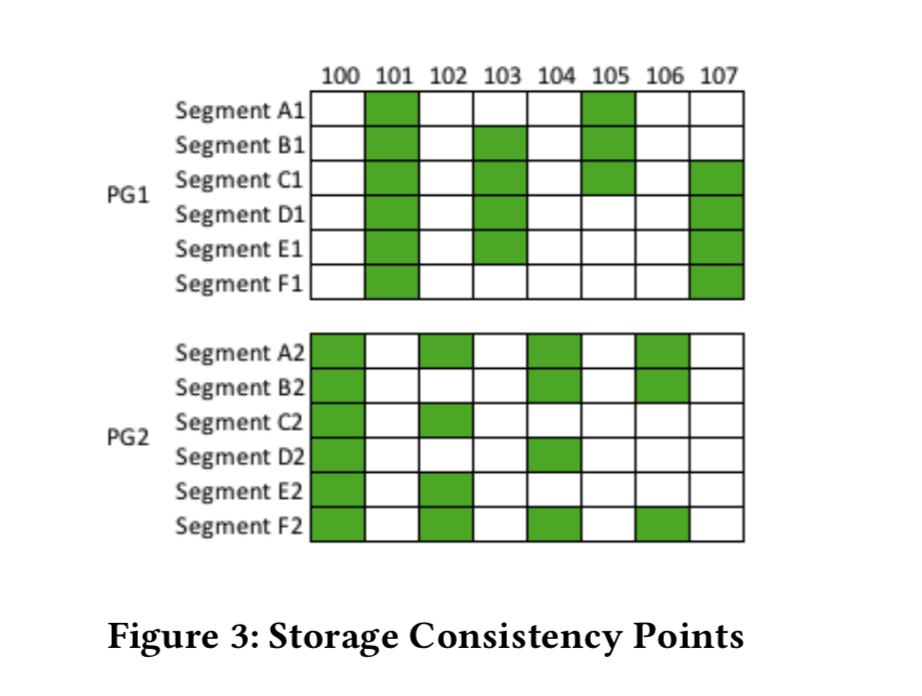
VCL为了保证数据的持久化,只有SCL这些还是不够的,因为这里的SCL应用的对象是segment,并不能代表全局的所有的数据。存储层保证不大于这个VCL的日志已经提交的。一个事务可能不止产生一条的log,这一组的log中产生一条记录的操作就叫做min transaction(MTR),而System Commit Number(SCN)指的就是这些log中LSN最大的,当这条记录都持久化之后,就能保证这个事务所有的日志都已经持久化了,这个的大小不会超过VCL。这里说的东西和在论文[2]中的没有多大的差别。下面的提交的时候异步的方法也就是去年的论文上面的东西,
When a commit is received, the worker thread writes the commit record, puts the transaction on a commit queue, and returns to a common task queue to find the next request to be processed. When a driver thread advances VCL, it wakes up a dedicated commit thread that scans the commit queue for SCNs below the new VCL and sends acknowledgements to the clients waiting for commit. There is no induced latency from group commits and no idle time for worker threads.
Crash Recovery in Aurora
这里要处理的第一个问题:数据中保存的一些数据是没有持久化的,比如之前说的PGCL和VCL。这个时候就要求从存储结点的SCL信息中将这些信息恢复出来,
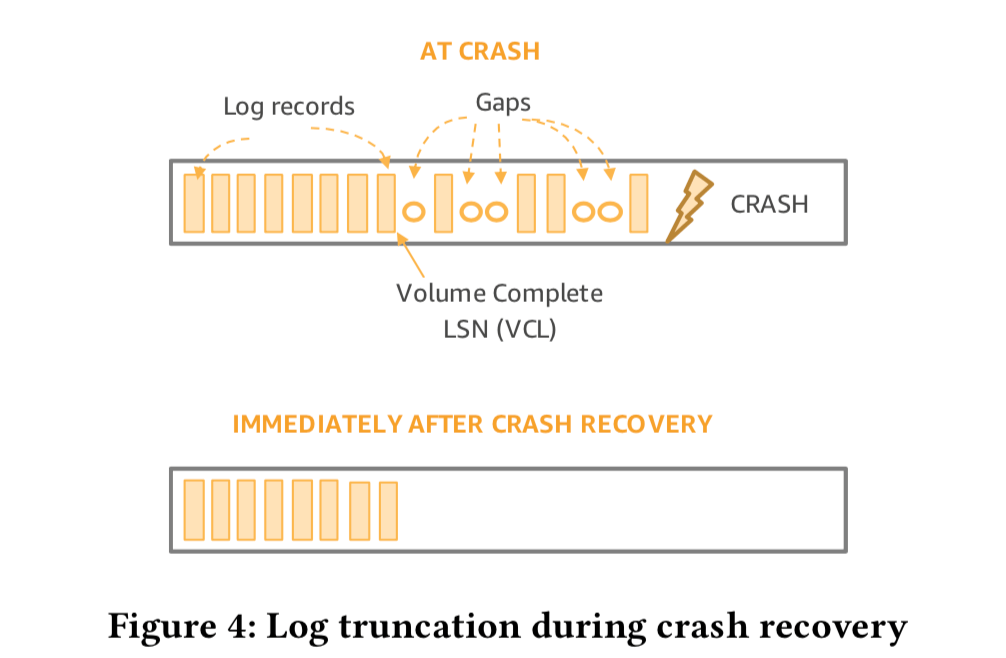
在重建这些信息的时候,如果从一个read quorum中也无法重建出来,就表示这些写入的不完整的,当然这些不完整的日志对于的事务肯定也没有回复客户端为已经完成的。这些不不完整的日志会被截断,
The database snips off the ragged edge of the log by recording a truncation range that annuls any log records beyond the newly computed VCL (Figure 4). This ensures that, even if in-flight asynchronous operations complete during the process of crash recovery, they are ignored. New redo records after crash recovery are allocated LSNs above the truncation range.
此外,在恢复操作的时候也会使用epoch的机制,用来解决旧的实例访问的问题。
0x03 高效读
这里主要讲的是Aurora如何避免quorum reads的方式的。这里的机制就是使用VDL(Volume Durable LSN),表示是已经持久化的COLs中LSN最大的,这里很显然满足VDL <= VCL(Consistency Point LSNs(CPLs),在MySQL之类的数据中,一个事务可能会产生多条的redo log,也就是说一个完整的事务log可能是一组的日志)。在去年的Aurora的论文中有提到Master会同步log给Slave结点,同样的,这里也会同步VCL、VDL之类的信息,这样的话slave结点就可以知道哪些段的数据是完整的,读的话直接取这些结点就可以了,不同使用quorum reads的方式来保证读取到最新的数据,减少了读的放大。
Aurora does not do quorum reads. Through its bookkeeping of writes and consistency points, the database instance knows which segments have the last durable version of a data block and can request it directly from any of those segments.
感觉这里和去年的论文没有上面新的东西,这里就是讨论下面提交的概念的作用了,
The use of monotonically increasing consistency points – SCLs, PGCLs, PGMRPLs, VCLs, and VDLs – ensures the representation of consistency points is compact and comparable. These may seem like complex concepts but are just the extension of familiar database notions of LSNs and SCNs. The key invariant is that the log only ever marches forward. This also simplifies the process of coordinating multiple request processors, as shown here for replicas operating against common storage.
0x04 故障 和 Quorum成员
这里说的是Aurora中的成员变更的机制。这里使用了基于epoch的方法。在一个数据库治理和一个对等的存储结点请求一个存储结点的时候,都会带上这个epoch的值(Aurora这里有两个epoch概念,一个是数据卷的epoch,一个是Quorum成员的epoch,这里说的后者)。
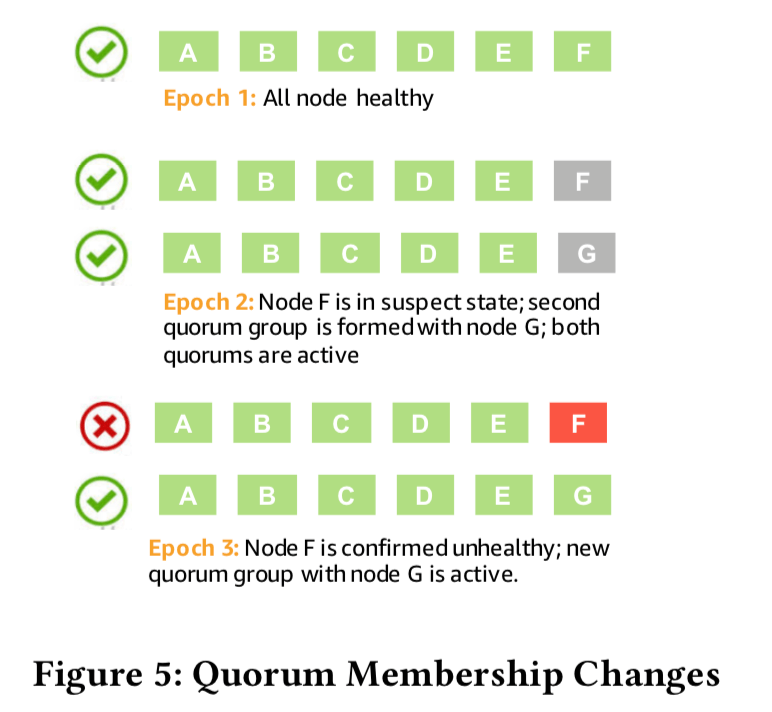
以上面的图中使用G替代F说明为例:这里不是直接一步地将F替代,而是分为2步。1. 先将G加入这个Quorum中,变为2个write set:4/6 of ABCDEF 和 4/6 of ABCDEG,读则是3/6 of ABCDEF OR 3/6 of ABCDEG。如果F在这个过程中重新正常工作,就可以变为原来的状态,如何G获取了需要的数据之后F还是不能工作的状态,这个时候就变为ABCDEG的状态。在这个过程中,write quorum都是可以满足的,不会影响正常工作,
Let us now consider what happens if E also fails while we are replacing F with G, and we wish to replace it with H. In this case, we would move from a write quorum set of ((4/6 of ABCDEF AND 4/6 of ABCDEG) AND (4/6 of ABCDFH AND 4/6 of ABCDGH)). As with a single failure, I/Os can proceed, the operation is reversible, and the membership change can occur with an epoch increment. Note that, both with a single failure and with multiple failures, simply writing to the four members ABCD meets quorum.
这篇文章和去年的文章相比感觉没有多少新的东西,就是描述的重点不一样而已。在这两篇Paper中出现了这些概念:
- LSN,这里不是来自于Aurora,
- Segment Complete LSN (SCL),
- Protection Group Complete LSN (PGCL),
- Volume Complete LSN (VCL) ,
- System Commit Number(SCN),
- Volume Durable LSN (VDL),
- mini-transactions (MTRs),
- Protection Group Minimum Read Point LSN (PGMRPL),
- Consistency Point LSNs,
参考
- Alexandre Verbitski, Anurag Gupta, Debanjan Saha, James Corey, Kamal Gupta, Murali Brahmadesam, Raman Mittal, Sailesh Krishnamurthy, Sandor Maurice, and Tengiz Kharatishvilli, Xiaofeng Bao. 2018. Amazon Aurora: On Avoiding Distributed Consensus for I/Os, Commits, and Membership Changes. In SIGMOD’18: 2018 International Conference on Management of Data, June 10–15, 2018, Houston, TX, USA. ACM, New York, NY, USA, 8 pages. https://doi.org/10.1145/3183713.3196937 .
- Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases, SIGMOD 2017.
