Contention-Aware Lock Scheduling for Transactional Databases
0x00 引言
这篇Paper是一篇比较有意思的Paper,这个算法已经被MySQL 8.0采用了。文章一步一步的说明思路,从简单的想法开始,最终得出来 Largest-Dependency-Set-First 和batched Largest-Dependency- Set-First 两种算法。
0x01 背景与动机
简而言之就是:Our goal is to find a lock scheduling algorithm under which the expected transaction latency is minimized.很不幸的是,这个问题是个NP问题,找到最优的解是不现实的。所以这里只能使用近似的方法。Paper中给出了一些概念,这里就不仔细去说这些概念了. 这里只说一下Dependency Graph,这对理解算法很重要:
Dependency Graph

这里定义了这么多的东西,就是为了描述txn之间通过lock而形成的依赖关系。这个依赖图是理解后面算法的核心。这个本身比不复杂。 下面是两个例子,
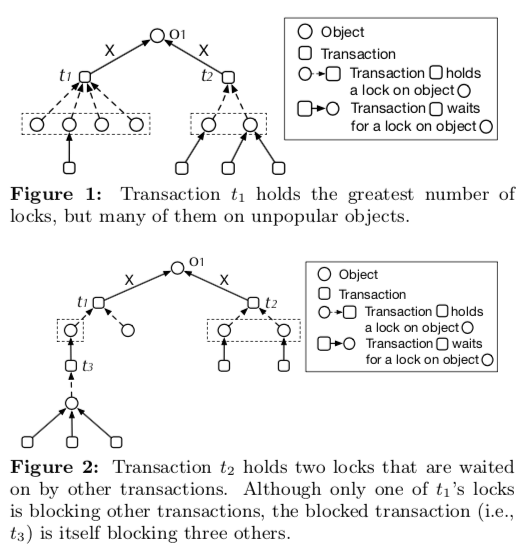
0x02 算法
接下来就是讨论了几类算法,并分析了优缺点。
Most Locks First (MLF)
The intuition is that a transaction with more locks is more likely to block other transactions in the system. However, this approach does not account for the popularity of objects in the system. In other words, a transaction might be holding many locks but on unpopular objects, which are unlikely to be requested by other transactions.
简而言之就是一个通过最多的locks决定那个transaction最先,缺点是这个txn locks不一定是热点数据。
Most Blocking Locks First (MBLF)
An improvement over the previous criterion is to only count those locks that have at least one transaction waiting on them.
...
The issue with this criterion is that it treats all blocked transactions as the same, even if they contribute unequally to the overall contention.
通过使用最多等待作为判断标准,解决前一种算法存在的问题。缺点是没有区分block的txn,而txn造成的contention不是相同的。
Deepest Dependency First (DDF)
A more sophisticated criterion is the depth of a transaction’s dependency subgraph. For a transaction t, this is defined as the subgraph of the dependency graph comprised of all vertices that can reach t (and all edges between such vertices). The depth of t’s dependency subgraph is characterized by the number of transactions on the longest path in the subgraph that ends in t.
DDF使用了dependency graph的深度来决定那个txn最先运行,就有可能让更对的dependency graph的“深度”更加浅的尽快得到运行,减少contention。但是缺点是没有考虑到深度很深的,但是之间contention很少的情况,比如就是一条比较长的链结构的case。
0x03 Largest-Dependency-Set-First
算法描述,这里涉及到太多的数学符号,直接使用Paper中的一张图,
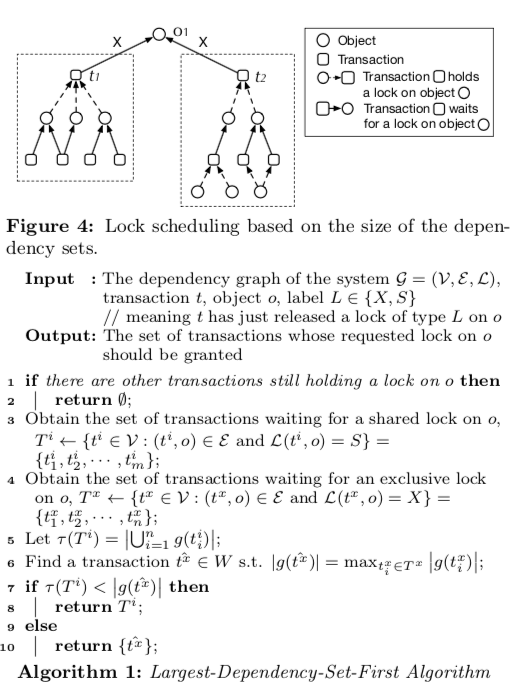
思路如下:
Consider two transactions t1 and t2 in the system. If there is a path from t1 to t2 in the dependency graph, we say that t1 is dependent on t2 (i.e., t1 depends on t2’s completion/abortion for at least one of its required locks). We define the dependency set of t, denoted by g(t), as the set of all transactions that are dependent on t (i.e., the set of transactions in t’s dependency subgraph). Our LDSF algorithm uses the size of the dependency sets of different transactions to decide which one(s) to schedule first. For example, in Figure 4, there are five transactions in the dependency set of transaction t1 (including t1 itself) while there are four transactions in t2’s dependency set. Thus, in a situation where both t1 and t2 have requested an exclusive lock on object o1, LDSF grants the lock to t1 (instead of t2) as soon as o1 becomes available.
就是使用dependency作为判断依据,让依赖性它最多的txn最先执行,这个就好比出租车和大客车同时通过一个只能经过一辆车的路口,显然让大客车先过能让平均等待时间最少。
0x04 The bLDSF Algorithm
bLDSF Algorithm来源于这样一个动机:LDSF algorithm中当一个shared lock被准许是,是给了所有的等待这个lock的txn,在一些情况下不是一个很好的策略。比如:在一个有很多shared lock的object上,只有当最后一个txn释放这个lock时,需要这个object上X lock的txn才能运行(和rwlock存在的一些问题很相似)。 bLDSF Algorithm解决这个问题的方式是:首先,找到一个等待一个X lock的txn,这个txn有最大的dependency set,记这个度量的值为p(具体的定义可以参考下面论文片段or直接看原论文) 。然后,找到在等待一些shared lock的事务,这些事务使得综合的等待最长,记这个度量为q。根据p q的大小关系决定那个先运行。简单的一个理解就是区分X 和 S锁,当要准许一个lock是,X只能给一个txn,计算一个度量值,S可以给一些txn,计算一个度量值,谁有利于事务平均等待时间更加少就准许那个lock。这个度量的值具体可以参考下面的论文片段,这里有是很多的符号,不好写到Markdown里面:
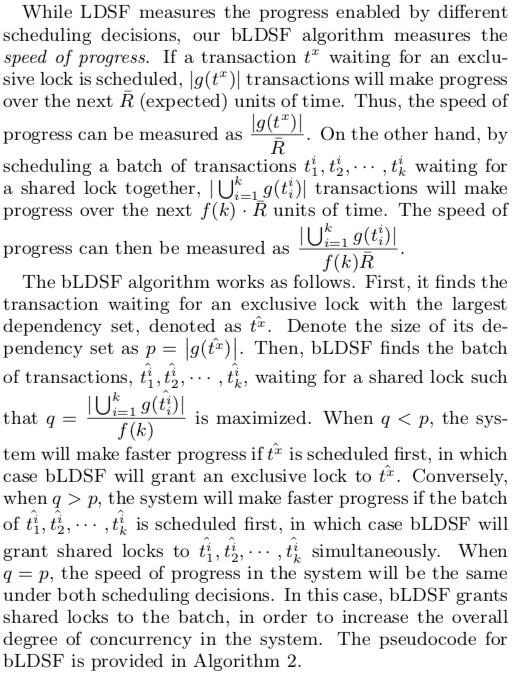
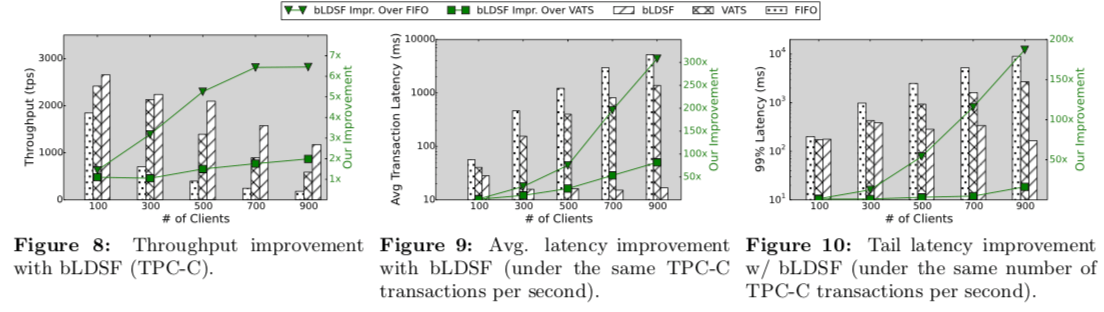
0x05 评估
这里的具体信息可以参看[1],
参考
- Contention-Aware Lock Scheduling for Transactional Databases ,VLDB 2018.
