Hybrid Garbage Collection for Multi-Version Concurrency Control in SAP HANA
0x00 引言
MVCC是数据库中最常用的并发控制的方式,没有之一。这篇Paper讨论的是MVCC中的GC的问题。由于MVCC的每次的更新操作,包含添加、更新和删除等都会产生一个新版本的数据(一个完整版本的新纪录,或者是纪录新旧版本之间的差异),这些都要处理的一个问题就如果在合适的时候及时的回收这些数据,以便释放其占用的空间,还能提高性能。一个版本的数据如果多所有的运行中的时候都不可见的时候,这个版本的数据就可以回收。所以最常见的GC方式就是以目前还存在的事务的最小的事务ID作为GC的参数。不过这中方式的一个缺点就是如果存在长事务的话,会阻塞这个事务执行期间的垃圾回收。而这篇Paper处理的一个核心的问题,提出几种GC混合使用的策略,
... we present an efficient and effective garbage collector called HybridGC in SAP HANA. HybridGC integrates three novel concepts of garbage collection: timestamp-based group garbage collection, table garbage collection, and interval garbage collection. Through experiments using mixed OLTP and OLAP workloads, we show that HybridGC effectively and efficiently collects garbage versions with negligible overhead.
0x01 基本思路
这里提出的一个Interval Garbage Collector的垃圾回收器,这个垃圾回收器基于visible interval的概念。这里用一个时间戳区间[s,e),代表了一个纪录在这个区间内的snapshot timestamp可以“看见”这条记录。如果在一个区间内,没有了任何运行中的操作,这个区间内的记录就可以回收了。这样的设计就使得垃圾回收不依赖与数据库整体最小的snapshot timestamp。即使存在长事务,后面产生的一些数据在合适的时也可以回收。此外,垃圾回收也会带来不小的开销,未来缓解这个问题,这里引入了group garbage version回收器的设计。Group回收器的基本思路就是将一组的可以回收的版本一起回收,以此来平摊的GC的开销。Group回收器和timestamp-based和interval-based可以结合使用,这样就形成了4中GC的策略,

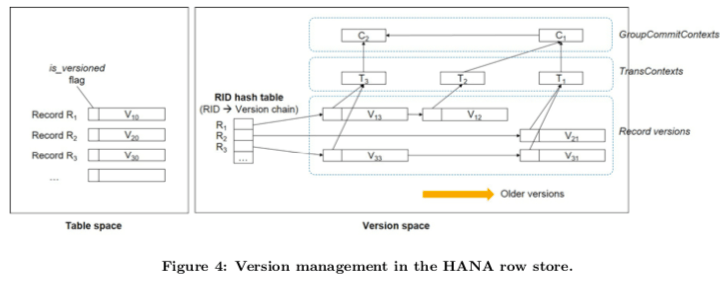
在SNAP HAHA中,更新操作( INSERT/UPDATE/DELETE)都会产生一个记录新的版本。每个记录包含了一个version header和其payload。这个version header包含了其创立操作的操作类型,这个记录的id即RID,所属的table的ID,和其它的几个维持版本链的指针。同一条记录的不同版本以新到旧的方式组织为链表。最新版本保存在最前面的方式基于新版本访问频率更高的假设,这样就可以减少遍历这个版本链表的开销。指向这个一条记录最新版本的指针保存在一个RID hash table中,这个hash table支持用于使用RID找到对应的version chain。另外,一条记录还包含了一个is versioned的标记为,只有在这条记录存在其它版本的时候才会设计,这样的话就可以在这个标记没有设置的时候才可以查这个RID hash table。另外,
- 被同一个事物生产的记录会包含指向同一个名为TransContext结构。这个结果在一个事物开始第一个写操作的时候创建。后面这个事物创建的记录都会有一个指针指向这个TransContext。
- 在这个事物提交之前,这个存在一个指针,一直为NULL。在这个事物提交的时候,这个指针被设置为指向一个GroupCommitContext的结果,这个是一组事物组提交相关的数据结构。在提交的时候,会在这个GroupCommitContext结构中写入Commnit ID即CID,这样操作之后就会使得这个结构对相关的TransContext可见,即这组提交的事物拥有同一个CID。这样设置提交方式会比设置所有记录的“CID”更加有效率。
- 这样做法的缺点就是在访问CID需要通过一些指针访问,这个问题可以通过异步地将这个CID同步到记录中缓解。
为了在多版本中辨识出可以回收的版本,这里引入了Consecutive interval intersection的概念。在这里,定义least greater number (LGN)为一个已经排序的整数序列中,大于一个整数t的最小的树,比如,
... denote the least greater number by LGN(t,S). Suppose that t=10, and S = [1, 4, 6, 8, 12, 14]. Then, LGN(t,S) = min{12, 14} = 12. If t =15, LGN(t,S) = ∞.
在两个排序的整数序列S、T中,定义T∩ 为 \(\\ T∩ = {t|t∈ T, LGN(t+1,T) \le LGN(t, S)} \\ \text{Consider S = [90, 92, 95, 96, 99] and T = [91, 93, 94, 95, 98].} \\ \text{Computing LGN(t + 1, T ) and LGN(t,S) for each t. Finally, computing T∩ = {93, 94}. }\) 如果这里S为排序的snapshot的时间戳,T为排序的一个记录的不同版本号,这样就可以得出T∩为可以回收的版本号。对于一个版本t来说,它的visible interval就是[t, LGN(t+1, T))。Paper中提出计算这个的基本算法如下,复杂度为O(|T | + |S|)
Algorithm 1 MergeBasedGC(S, T):
Input: Two ordered sequence of integers S, T.
Output: T∩ .
i←0
j←0
while i < |T|-1 do
if S[j] < T[i] then
j←j+1
else if T[i+1]≤S[j] then
/∗T [i + 1] represents LGN(T [i] + 1, T ).∗/
T∩ ←T∩ ∪T[i]
i←i+1
else
i←i+1
end if
end while
return T∩
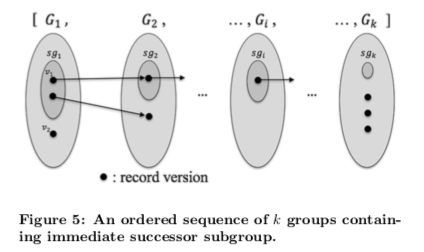
属于同一个GroupCommitContext的版本的记录的版本号都相同。将一些版本根据它们的timestamp合并进行GC是一种提高GC效率的方式。在timestamp-based的回收器上,实现single verison回收和group version回收比较直观。Paper中还简单讨论了将这个思路应用到interval-based的回收器上面。这里先提出了immediate successor subgroup的概念,这个immediate successor subgroup表示了在一个组Gi中在其后续的一个组Gi+1中拥有immediate successor的版本的集合。然后将这个基于interval的垃圾回收器应用到一个排序的的immediate successor subgroups序列上面,这里还有一个问题Paper中没有去说明,
Then, we can apply the interval garbage collector to an ordered sequence of immediate successor subgroups. In this scheme, we need an efficient, systematic mechanism to move a record version in Gi to form its immediate successor subgroup, which is beyond of the scope of our paper and would be an interesting future topic of research.
0x02 实现
Paper这里说明了在SAP HANA中GT,SI和Table Garbage Collector三个回收器的设计,
-
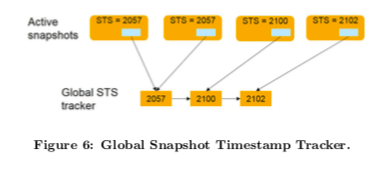
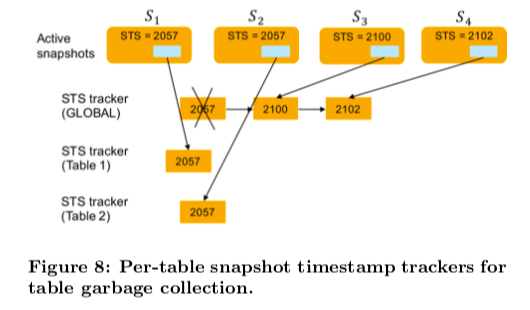
Global Group Garbage Collector, 即GT。这个回收器常见类型的回收器。这里主要考虑优化两个方面,1. 如何高效率选择最小的全局的snapshot的时间戳,2. 如何高效率探明一组可以回收的版本。为了解决第一个问题,这里引入了 global snapshot timestamp tracker (global STS tracker)。这个就是一个一个已经排序的snapshot时间戳的带引用计数的列表。在请求snapshot时间戳的时候,如果发现这个时间戳已经存在这个tracker里面,则增加器引用计数,否则则添加一个snapshot时间戳对象,并设置器引用计数。相关的操作完成之后,递减这个引用计数,在这个引用计数变为0之后,将这个对象从链表中删除。每个活动的snapshot会保存一个指向对应snapshot时间戳对象的指针,如下图所示,这样找最小的时间戳就是一个比较容易的事情了,
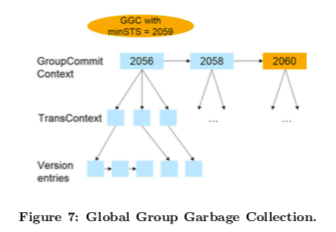
对于第二个问题的优化,这里利用了GroupCommitContext和TransContext对象。根据这里的工作逻辑,可以比较容易利用GroupCommitContext找到有相同CID记录的版本。这里的GroupCommitContext也会保存到一个排序的链表中。这样寻找可以回收版本的时候就不需要遍历每个记录的版本了。如果这个global garbage collector发现一个GroupCommitContext的CID大于了最小的全局snapshot时间戳,就可以停止便利这个链表,然后利用前面的GroupCommitContext结构找到可以回收的数据。如下图,
-
在SAP HANA中,为了简化系统的设计,group garbage collector只有基于timestamp的方式,而single garbage collector只会使用基于interval的方式。interval的垃圾回收器工作一般分为这样的四步,1. 从 global STS tracker中获取所有的活跃中的snapshot时间戳,作为一个排序号的序列用S表示,2. 遍历存在GroupCommitContext的对象,获取小于S最大值和大于其最小值的CIDs,这个CID的集合使用P表示,3. 根据CID从大到小便利这个链表P,对于每个GroupCommitContext对象,获取从其可达的记录,4. 遍历记录的version chain,根据前面的算法1回收可以回收的版本。
-
Table GC,这部分就是HANA中另外的一个叫做table garbage collection (TG)的垃圾回收器。一般而言,一个snapshot时间戳被分配之后,会被用于访问哪些table是不能确定的。而在SAP HANA中,存在Stmt-SI和Tran-SI两种SI的隔离级别,分为以语句为单位和事务为单位。在默认的Stmt-SI中,是可以从其的查询计划中获取其要访问的table。这里的思路利用这个特点来将长事务对整个数据库的影响限制在它只会访问的tables范围内。这个垃圾回收器工作流程分为三步,1. 探明长事务和器影响的范围,从snapshot时间戳从global STS tracke移动带per-table的STS trackers,相关的table都需要”移动到“。3. 根据单个table的snapshot最小时间戳来进行垃圾回收。
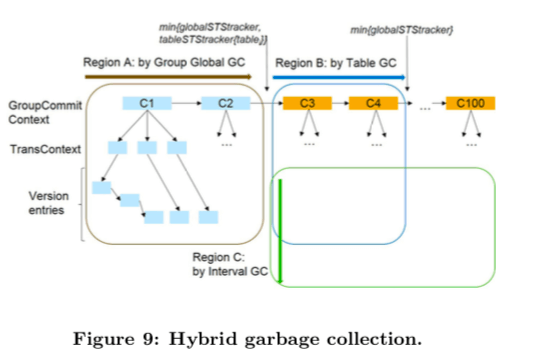
而HANA的hybrid garbage collector就是将前面这些垃圾回收器综合到一起,即global group garbage collector, the table garbage collector, 和 the interval garbage collector。这三个垃圾回收器分别独立工作。三个垃圾回收器有各自回收的区域,综合下来,整体的架构如下图所示。
0x03 评估
这里的具体信息可以参看[1].
参考
- Hybrid Garbage Collection for Multi-Version Concurrency Control in SAP HANA, SIGMOD ’16.
