Memory Checkpoint
0x00 引言
这篇总结总结的是3个为内存数据库设计的checkpoint的算法,一个发表在SIMOD2016[1],另外两个出自一篇Paper[2],发表在SIGMOD 2011。这两个Paper讲的是同一个问题,如何在内存中实现 checkpoint-recovery or snapshot算法。
0x01 Wait-Free Zigzag
这个算法出自[2]。基本思路如下: 在这个算法中的开始,系统的状态会被拷贝为2份,AS0 和 AS1,这两个数组的一个字就代表了一个状态信息。另外还有两个数组MR 和 MW,MR的一个bit,MR[i]用来指示应该从哪一个AS中读取,而后者则是指示应该写入哪一个AS,前者初始化为0,而后者初始化为1。在进行checkpoint操作的周期内,MW的值不会变化,这个保证了它不会写入的AS的值不会变化,而synchronous Writer操作就是讲这些words写入到磁盘以设置checkpoint。在更新一个状态值的时候,会写入MW[i]指示的位置,同时把MR[i]设置为MW[i]一样的值。这个算法理解起来很容易,结合下面的图很显然,
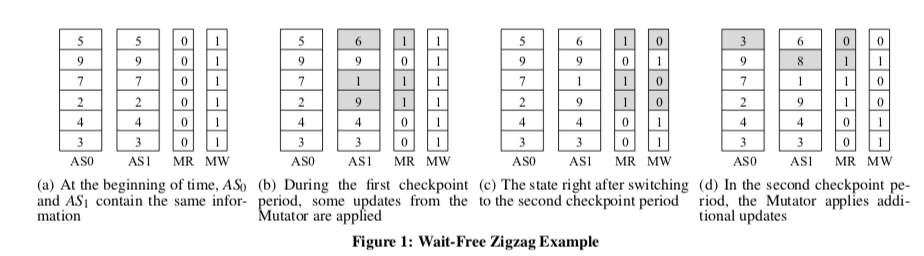
伪代码,
input:
/* ApplicationState is a vector containing words */ ApplicationState AS0 ← initial application state ApplicationState AS1 ← initial application state
/* size of application state in words */
sizeWords ← |AS0|
/* reads from the Mutator reference ASMR[k] */ BitArray MR ← {0,0,...,0}
/* writes from the Mutator affect ASMW[k] */
BitArray MW ← {1,1,...,1}
Mutator::PrepareForNextCheckpoint()
for i = 0 to sizeWords do MW [i] ← ¬MR[i]
end for
Mutator::PointOfConsistency()
if Asynchronous Writer done then
PrepareForNextCheckpoint()
NotifyAsynchronousWriter()
end if
Mutator::HandleRead(index)
return AS_{MR[index]}[index]
Mutator::HandleWrite(index, newValue)
AS_{MW[index]}[index] ← newValue
MR[index]←MW[index]
AsynchronousWriter::WriteToStableStorage()
loop
WaitForMutatorNotification()
for k = 0 to sizeWords do
write-to-disk AS¬MW[k][k]
end for
end loop
.
0x02 Wait-Free Ping-Pong
这个算法同样出自[2]。基本思路如下:算法保留了状态三份拷贝,其中两个用于保证Mutator和Asynchronous Writer总是访问不同版本的数据,而最后一份使得在checkpoint操作的时候不用在进行一次大的拷贝 or 一次线性时间的bit-array的重设,它只需要交换两个数组的指针。这也是一个很容易理解的方法,基本的操作方法:
- Mutator更新的时候同时更新AS数组和Current数组,Current数组为Odd和Even数组中的一个。读取的时候从AS数组中读取;
- Asynchronous Writer使用另外一份的拷贝写入磁盘来执行一个checkpoint,在checkpoint之后执行指针交换即可。
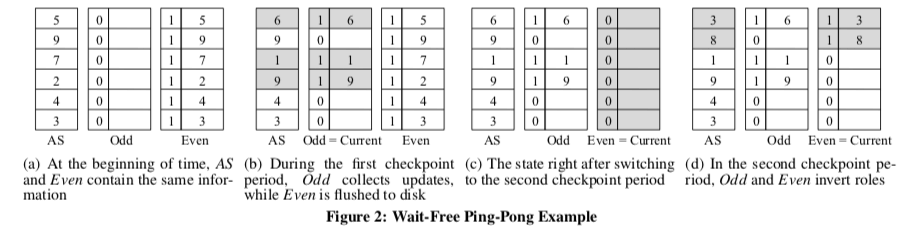
伪代码,
input:
/* ApplicationState is vector containing words */ ApplicationState AS ← initial application state ApplicationState currentAS
ApplicationState previousAS ← initial application state
/* size of application state in words */
sizeWords ← |AS|
/* dirty words in the current checkpoint */ BitArray currentBA ← {0,0,...,0}
/* dirty words from the last checkpoint */ BitArray previousBA ← {1, 1, . . . , 1}
Mutator::PrepareForNextCheckpoint()
/* pointer swapping */
swap (previousAS,currentAS)
swap (previousBA,currentBA)
Mutator::PointOfConsistency()
if Asynchronous Writer done then
PrepareForNextCheckpoint()
NotifyAsynchronousWriter()
end if
Mutator::HandleWrite(index, newValue)
AS[index]←newValue
currentAS[index]←newValue
currenBA[index]←1
AsynchronousWriter::WriteToStableStorage()
loop
WaitForMutatorNotification()
for k = 0 to sizeWords do
if previousBA[k] then
write-to-disk previousAS[k]
previousBA[k] ← 0
previousAS[k] ← empty
else
write-to-disk word k from previous checkpoint
end if
end for
end loop
0x03 Checkpointing Asynchronously using Logical Consistency (CALC)
这个算法出自[1]。CALC保护这样的一些结构,CALC算法分为5个步骤:
-
Rest phase,在这个步骤,所有的记录都只有一个live的版本,stable versions为空,stable status标记为为not_available。在这个阶段都读和写只会操作这个版本,不管是否事务已经提交。
Inserts and deletes are handled via two additional bit vectors, called add status and delete status. However, we only focus on updates in our discussion to keep the explanation simple. -
Prepare phase,一个checkpointing操作开始就进入到了这个阶段,这个阶段事务读写的也是live版本的记录。但是在读取一个版本的数据的时候,如果stable版本的数据是空或者是unavailable,就在更新操作之前把live版本保存到stable版本中,
This is done because the system is not sure in which phase the transaction will be committed. For example, a transaction TP that begins during the prepare phase and writes a record R1— overwriting a previous value R0—makes a copy of R0 in its stable version before replacing R0 in the live version. Immediately after committing, but before releasing any locks, a check is made: if the system is still in the prepare phase at the time the transaction is committed, the stable version is removed. -
Resolve phase,在rest阶段的事务都完成的时候,系统进入Resolve阶段(appending a phase-transition token to the commit-log)。这个点的一个事务被定义为virtual point of consistency,在这个之前提交的写入都能够反映到这个checkpoint中,否则就不能,
Transactions that start during the resolve phase are already beginning after the point of consistency, so they will certainly complete after the checkpoint’s point of consistency. -
Capture phase,当在prepare阶段启动的事务完成操作并释放它们的锁的时候,系统进入到Capture阶段,写入的行为和前一个resolve步骤的一样。这个阶段一个后台的线程会将stable版本的数据写入到磁盘中(对于没有明确的stable版本的数据就写入live版本的数据)。这个操作会同时删除stable版本的数据,但是stable status标记为依然会被设置为available以免其他的线程重复写入磁盘操作。
-
Complete phase,前一个阶段完成的时候进入了Complete阶段。写入操作的行为和前面rest阶段的一样,这个阶段完成之后回到步骤1。在回去之前,这个要使用SwapAvailableAndNotAvailable函数将对应的值设置为相反(是标记的available和not available的值设置为相反,而不是标记数组的值),
In one iteration of the checkpointing algorithm, not available maps to “1” and available maps to “0”; in the next not available maps to “0” and available maps to “1”. This allows the system to avoid a full scan to reset the stable status bits, since after the capture phase all the stable status bits are set to available, but at the beginning of the rest phase we want all the stable status bits to be set to not available.
伪代码,
Initialized Database status:
bit not available = 0;
bit available = 1;
bit stable status[DB SIZE];
foreach key in Database
db[key].live contains actual record value;
db[key].stable is empty;
stable status[key] = not available;
function ApplyWrite(txn, key, value)
if (txn.start−phase is PREPARE)
if (stable status[key] == not available)
db[key].stable = db[key].live;
else if (txn.start−phase is RESOLVE OR CAPTURE)
if (stable status[key] == not available)
db[key].stable = db[key].live;
stable status[key] = available;
else if (txn.start−phase is COMPLETE OR REST)
if (db[key].stable is not empty)
Erase db[key].stable;
db[key].live = value
function Execute(txn)
txn.start−phase = current−phase;
request txn’s locks;
run txn logic, using ApplyWrite for updates;
append txn commit token to commit−log;
if (txn.start−phase is PREPARE)
if (txn committed during PREPARE phase)
foreach key in txn
Erase db[key].stable;
else if (txn committed during RESOLVE phase)
foreach key in txn
stable status[key] = available;
release txn’s locks;
function RunCheckpointer()
while (true)
SetPhase(REST );
wait for signal to start checkpointing;
SetPhase(PREPARE );
wait for all active txns to have start−phase == PREPARE;
SetPhase(RESOLVE );
wait for all active txns to have start−phase == RESOLVE ; SetPhase(CAPTURE );
foreach key in db
if (stable status[key] == available)
write db[key].stable to Checkpoint;
Erase db[key].stable;
else if (stable status[key] == not available)
stable status[key] = available;
val = db[key].live;
if (db[key].stable is not empty)
write db[key].stable to Checkpointing;
Erase db[key].stable;
else if (db[key].stable is empty)
write val to Checkpointing;
SetPhase(COMPLETE );
wait for all active txns to have start−phase == COMPLETE;
SwapAvailableAndNotAvailable ();
0x04 评估
这里具体信息可以参看[1,2].
参考
- Low-Overhead Asynchronous Checkpointing in Main-Memory Database Systems, SIGMOD’16.
- Fast Checkpoint Recovery Algorithms for Frequently Consistent Applications, SIGMOD’11.
