Automatic Database Management System Tuning Through Large-scale Machine Learning
0x00 引言
这是一篇很赞的Paper。这篇Paper代表的思路很有可能引起后面更多的研究,而且在以后有很大的应用空间。利用机器学习来自动调优数据库是一个很有吸引力的事情。在之前有自动调优的一些研究称之为Self-Tuning Database System。数据里面会有成百上千的参数来调整数据库运行时候的一些行为,这篇Paper提出了数据库自动调优核心问题之一就是如何找到影响到数据库性能表现的关系参数,这里称之为knobs。为了解决这个问题,这里引入了机器学习的方式,使用监督学习和非监督学习的方式,由于实现,1. 找出这些knobs,2. 对于未曾出现的workloads,从之前出现过的workloads中找出类似的,3. 给出这些“knobs”参考设置,优化系统性能。
0x01 基本架构
OtterTune的基本架构如下图所示。主要由两个部分组成,一个部分是客户端的Controller,它于目标的数据交互。它收集通过标准的API收集数据库运行时的一些数据,也会负责将新的数据配置发送到数据中。另外的一个部分是Tunning Manager,它接受来自Controller收集到的信息,并将其数据保存。保存的数据不会包含数据库的任何机密的信息,只会保存一些配置的数据和一些性能数据。由于不同的数据版本之间的配置参数等存在一些差异,所以OtterTune会将这些数据会根据数据库的版本保存,使用这个OtterTune的一个例子,
- 在开启一个tuning session的时候,DBA告诉OtterTune什么指标是准备要去调优的,比如吞吐、延迟等。OtterTune COntroller之后会连接数据库获取硬件配置和目前的knob配置。这里假设和谐硬件配置不是随机的,而是从一个硬件配置的列表中选择的一个,这个在云计算的环境中问题不大。Paper中提到更加广泛的硬件支持会是未来的工作;
- Controller之后开始一个observation period。这一步会花费一些时间来测量一些需要的数据。DBA可以选择让数据执行一组查询或者是一个特定的workload的追踪,这些操作是数据获取的来源,这个时间段内收集的指标一般为外部可见的一些指标,比如说吞吐,延迟。在这个observation period结束之后,Controller会收集DBSM特定的内部的一些Metrics,比如MySQL从磁盘上面写入和读取的Page的数量统计。不同的DBMS提供了很多类似的指标数据,但是OtterTune不需要提供这些数据的含义具体是什么,后者是相同含义的参数在不同的数据库中有不同的名字,这些数据OtterTune都是不需要。
- 在Tuning Manager收到了这个observation period收集到的数据之后,这些数据会先被保存起来。基于这些数据,OtterTune计算出来下一个数据的配置参数。这步主要分为两个步骤,第一步会将这个workload的特点映射到之前一个已经知道的workload的特点上面。第二步根据这个硬件和这些数据得到一个推荐配置。这里也会给DBA提供一个控制的接口。
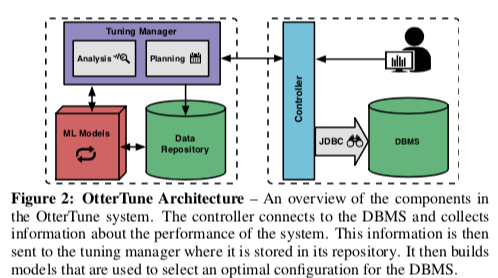
OtterTune的设计中存在一些假设和一些限制。OtterTune的一些操作是需要Admin级别的的权限的。由于数据有些设置在数据库中是在启动的时候就确定了的,且在运行中不能更改,所有未来更新参数,在必要的时候可能需要数据库重启。
0x02 Workload特性&Knobs
OtterTune探究数据库Workload的特性并不是完全从数据当前的出发,给出一个数据库当前Workload的特性描述,而是根据目前的一些数据寻找OtterTune以及预先知道的一些Wrorkload特性的相同or相似点。在探究Workload的特性上面,OtterTune这里提出了两种基本的方式,
- 第一种是直接从逻辑的层面上起理解。这些逻辑上的信息可以利用数据库的优化器。这样的缺点时不能很好地反映数据实际运行的信息,也不能很好地表示出一个Knobs参数改变后数据库的影响。
- 另外一种OtterTune采用的方式,这种方式总体上来看更好一些。这种方式直接利用数据库运行时候内部的统计的一些Metrics。现代的数据一般都在数据内存记录了大量的数据内部统计的一些信息,比如在MySQL InnoDB存储引擎中会统计Page读取和写入数量的信息,Queue Cache的利用率以及锁开销的一些信息。OtterTune通过这些内部的统计信息来标示出一个Workload的特性,这种方式的一个优化是这些统计信息反应的是数据库运行时候实际的特点,另外的一个优点是这些统计信息的值直接被Knob配置影响,不如如何配置Buffer Pool小了,在内部的统计数据中就会Buffer Pool的Cache缺失率上升。一般的数据库系统都有这样的一些统计信息,在不同的数据中这些统计信息的名字可能不同,这也是OtterTune设计为它不需要知道数据库中一个参数的含义的重要原因。
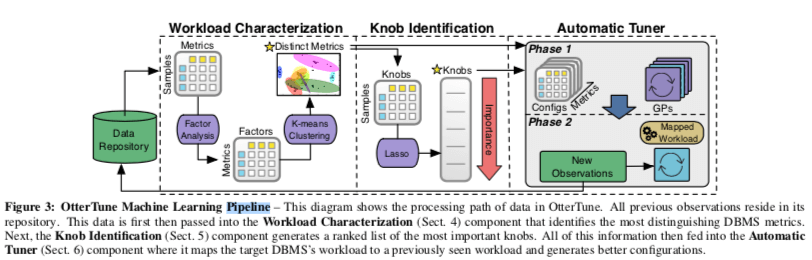
在决定来获取Workload特性的策略之后,下面要做的事就是如何获取这些统计信息,以及对统计信息进行一些处理,取出掉一些无用的信息,
- 信息收集,OtterTune将数据收集的操作划为为一个个的observation period。在每一个period开始的时候重置所有的统计信息,信息收集的这一步由于OtterTune最终哪些数据会有用,OtterTune这里就直接收集可以收集到的所有的信息。这些数据以Key-Value Pair的方式保存。这里还有另外的一个问题要处理,就是不同的数据库系统中这些数据统计的一个“精细”程度的不同,比如在MySQL中,这些统计信息是统计了整个数据库层面,而在其它的一些系统中,统计的是表层面或者是库层面的。为了简化处理,这里都使用了一个总的统计数据,更加细层面的数据统计处理会是以后的工作内容。
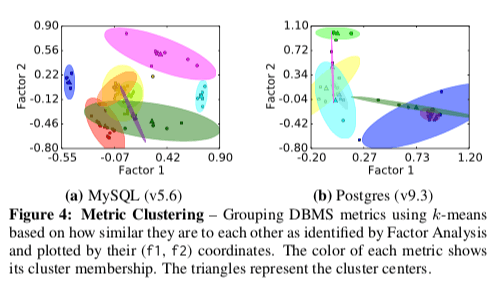
- 去除无用的Metrics,在收集了统计信息之后就是自动去除一些无用的数据。如果不去出一些无用参数,这样算法需要计算的空间会是一个极其大的值。多余的统计数据一般有两种出现原因,一种是不同的统计数据统计的是相同或者是很类似的数据,比如MySQL中统计的Pages读取数量和Bytes统计数。另外一个原因是这些数据虽然含义不同,但是它们之间是强相关的,知道了一个就基本上可以推导出另外的参数是个什么情况。来实现去除这些冗余数据的两种基本方式是factor analysis和k-means。前者用于高维的数据转化为更低维的数据,后者拥有是被出油强相关的统计参数,这个是一个常见的聚类的问题,
Knob Configuration是OtterTune的一个核心的概念。在数据众多的参数设置中,不是所有的设置都对数据库的性能有显著的影响,在有显著影响的参数里面,也会有对数据性能影响程度的一个差别。将这些显著影响数据性能的参数找出来,可以大大减少需要工作量。这里的基本方式是线性回归的方式,找出对数据性能有这明显关系的参数。这里使用的方法是Lasso,具体内容TODO。
0x03 自动调优
在经过前面一系列的处理之后,OtterTune获取到了,1. 一个非冗余的Metrics的集合,2. 一个对数据性能影响最大的Knobs参数的一个集合,3. 其在前面的Tuning Session保存的数据。之后就是使用一个两步的操作来实现最终自动调优的过程。
- Workload Mapping,OtterTume会将数据库目前Workload的特性和它已经保存的Workload特性对比,从中找出最相似的一个。OtterTune利用的是已知的Worload及其优化配置和现在策略到的对比,从而最初现在的优化的决策。也就是说,OtterTune中保存的Workload特性和优化策略越多,OtterTune做出的决策会更好。Otter为每一个数据库系统建立一个N个Metrics的集合S(X0, X1,….Xn-1)。OtterTune得到的Metrics数据,这个集合可以看作是一个多维的表格,Xm,i,j表示Metrcis M在Workload i 和配置j下面的一个数值。这里也可以使用多次策略却平均值的方式。至于Workload的映射,这里使用了计算欧几里得距离的方式,对于每个workload i的都会计算一次。最后根据这个距离信息给每个workload计算一个“评分”。评分最低的一个为最相似的一个。另外,这里要保证所有的参数都使用同样的数量级表示,否则的话数值上面很大的参数会将数据小的参数隐藏。
- Configuration Recommendation,这一部分,OutterTune使用Gaussian Process (GP) regression来形成推荐参数。这里会复用在事前预定于的workload中训练出来的结果,并加入新的metrcis来更新这个model。OtterTune通过(1) searching an unknown region in its GP (i.e., workloads for which it has little to no data for), 或者是 (2) selecting a configuration that is near the best configuration in its GP,即找一个新的,or从选一个最接近的来作为新的配置推荐。这里具体调优方法TODO。
0x04 评估
这里的具体信息可以参看[1].
参考
- Automatic Database Management System Tuning Through Large-scale Machine Learning, SIGMOD ’17.
