Barrier-Enabled IO Stack for Flash Storage
0x00 引言
这是一篇非常好的Paper,还是FAST18的best paper,很值得一看,也不是很好理解,233333,看这篇问题最好看一下[2,3],另外,[4]也是一篇理解相关知识的很好的文章。这篇Paper是关于在Flash存储上面IO栈的一个优化,核心的思路就是消除传统的IO栈上面Transfer-and-Flush在现在的一些新的存储硬件上面的开销。Barrier-Enabled IO Stack主要就是将数据的持久化和IO请求的属性分离开,在此之前的方法都是使用fysnc和fdatasync的API来实现这两个的功能。这种方式在现在的一些新的存储硬件上面不能很好的发挥硬件的性能,而Barrier-Enabled IO Stack则添加了fbarrier和fdatabarrier两个API,实现更加细粒度的控制,从而提高性能。
We implement the barrier-enabled IO stack in server as well as in mobile platforms. SQLite performance increases by 270% and 75%, in server and in smartphone, respectively. In a server storage, BarrierFS brings as much as by 43× and by 73× performance gain in MySQL and SQLite, respectively, against EXT4 via relaxing the dura- bility of a transaction.
0x01 基本思路
在了解基本的思路之前,先来看一下现在的IO Stack中的一些特点。首先最重要的是IO Stack中的顺序。这里定义了下面的几种顺序:1. Issue Order,发出顺序,表示为I(原Paper上面使用的是很奇怪的符号来表示,这里就以首字母来表示),表示了FS向下面发送请求的顺序;2. Dispatch Order,分发顺序,表示为D; 3. Transfer Order,传输顺序,表示为T;4. Persist Order,持久化顺序,表示为P。这里定义一种偏序(partial order):当上面的操作在各个操作之间相对的顺序保持不变,则说这顺序之间满足这个偏序关心。这里的“偏”是是对barrier而言的,
a partial order is preserved if the relative position of the requests against a designated request, *barrier*, are preserved between two different types of orders. We use the notation ‘=’ to denote that a partial order is preserved.
由于现在的IO Stack存在下面的一些原因,这个偏序关心是不能得到保证的。也就是说现在的IO Stack对于请求的执行顺序是乱序的(out-of-order),
- I != D,因为Block层的IO调度器会对请求重新排序和合并请求,这样的话顺序就会被打乱了。当然一些调度算法比如Noop调度器和NVMe的接口不会打乱顺序;
- D != T,这里有具体存储设备相关。现在的顺序设备对OS发送过来的IO请求可以进行调度,这样顺序也就不能保证了;
-
T != P,存储设备也是存在Cache的(在一些高端的SSD上面这个Cache还比较大,直接使用GB级别的DDR4,比如某星的高端的NVMe SSD)。Cache的数据持久化也是不能确定的。
最后面的顺序保证是现在的OS都默认不能确定的,为了保证操作之间一定的顺序,OS一般使用的方法是Wait-on-Transfer,这个带来了很大的开销,也很不利于现在的SSD并行性的发挥。此外,另外一个开销是Transfer-and-Flush,这里利用这种机制得目的是用来保证日志文件系统中日志之间和一个日志之内得一些操作得顺序,这里更加详细的信息可以参考相关日志式文件系统的资料。fsync在ext4文件系统中的操作流程:
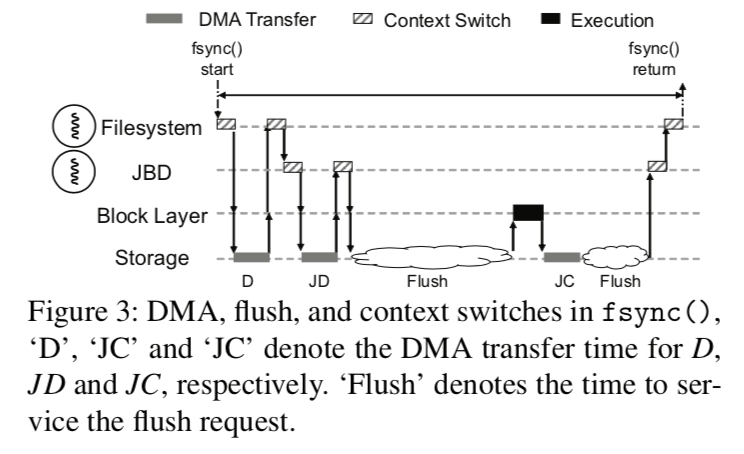
上面的图中字母表示的含义: D表示要写入存储设备的脏页,JC表示提交快(commit block),JD表示合并之后的日志描述符和日志块(journal descriptor block and the log blocks )。上面体条形的不同颜色填充形状表示来不同的时间消耗。在ext4日志式文件系统中,数据块是先于日志持久化的。文件系统在放松出写入脏页集合D之后,这个线程就会等待直到DMA传输的完成,在图中下面的D阶段。然后就是触犯系统中的JBD线程来持久化日志,这个过程发送请求的线程又得进入睡眠。这里这样做的一个原因之一就是保证数据块集合在日志数据之前持久化。此外一个日志的事务通常有写入日志描述块和日志块以及写入提交块组成。这里也是得保证顺序的,
Within a transaction, JBD needs to ensure that JD is made durable ahead of JC. Between the journal transactions, JBD has to ensure that journal transactions are made durable in order. When either of the two conditions are violated, the file system may recover incorrectly in case of unexpected failure.
0x02 保留顺序的Block层
Barrier-Enabled IO Stack在Block层设计的一个重点就是如何保证上面的偏序关系。前面提到了系统发送给存储器的请求和请求持久化是不能保证的,Barrier-Enabled IO Stack是面向Flash存储设备的设计,在现在的一些Flash的存储设备上提供了相关的指令来实现相关的顺序保证。另外另外的的重点是如何在现在的改进现在的无序的IO Stack上面实现需要的偏序关系。保留顺序的Block层将写入请求分为顺序保留的和没有顺序要求的,对于后者这里不怎么关系,对于要求顺序保留的在一个epoch里面可以重新排序,以一个特殊的顺序保留的写入作为一个barrier write,同时一个barrier write也是界定一个epoch的基准。这里主要包含了三个组件:
-
屏障写及其命令,这里主要就是用来消除Transfer-and-Flush的开销。主要就是利用现在的一些Flash存储设备提供的barrier command来保证写入数据的顺序性。对于没有这种特性的存储设备,还是得使用原来的方式。如果没有等待FLush到存储设备的完成,那么一些保留在存储设备Cache中的数据可能就丢失了。一些存储设备有防掉点保护系统,主要就是一个电容,可以使得设备在掉电之后持久化它自己内部的缓存。但是对于没有这个特性的设备,就得使用其它的方式,这里有三种方式,in-order writeback: 以epoch为粒度的刷入数据块。简单但是可能不利于性能;transactional writeback: 写回缓存的内容作为一个整体被写入,不同epochs的写回的缓存一起被写入,顺序得以保证,这里还可以利用Flash的保留区域来提高性能;in-order recovery: 这种方法则把重点放到了回复的时候,为了简化回复时候的算法(因为存储设备的控制器使用对个通道并发写的时候会使得回复的算法非常复杂,得使用类型数据库中使用的算法),如果可以将一个存储设备看作一个单一的日志设备,则恢复算法可以简单很多(参考LFS)。在这篇Paper中,作者修改了某星的一种型号手机的UFS(这里的UFS是智能手机上面常见的一种闪存设备,不是指UFS文件系统)存储设备的固件来支持屏障写命令。
The modified firmware treats the entire storage device as a single log structured device. It maintains an active segment in memory. FTL appends incoming data blocks to the active segment in the order in which they are transferred. When an active segment becomes full, the controller stripes the active segment across the multiple Flash chips in log-structured manner.这部分是最底层的,对应上面顺序中的T到P。从这里看来这项工作的工作量还是非常大的,从存储设备固件到操作系统多个地方的修改,而且改起来都是很难的东西。
-
顺序保留的分发模块,这里主要就是用来消除Wait-on-Transfer的开销,这里对应的顺序是D到T。这里使用的机制叫做Wait-on-Dispatch,基本思路就是Block在分发一个请求之后不必要等到传输完成,而是直接处理其它的操作,下面服务于Block层的部分能够保证这项请求之间要求的顺序(这里只会对有顺序要求的请求有相关的操作,对于没有要求的还是使用原来的方法)。这里使用顺序保留的分发使用了SCSI中的优先级,
SCSI standard defines three command priority levels: head of the queue, ordered, and simple . ... The default priority is simple. The command with simple priority cannot be inserted in front of the existing ordered or head of the queue command. Exploiting the command priority of existing SCSI interface, the order-preserving dispatch module ensures that the barrier write is serviced only after the existing requests in the command queue are serviced and before any of the commands that follow the barrier write are serviced.
- 基于epoch的IO调度器。Epoch的界定以一个屏障写为基准,这里对应的顺序是I到D。这里就比前面的容易理解了。现在的Linux的调度器会对(不是所有的)请求进行重新排序。这里加入以barrier界定的epoch就是防止不同epoch之间的有顺序要求的请求被重新排序之后不能满足要求的顺序。而对于没有顺序要求的请求,则可以不用care这个epoch来重新排序。这里主要涉及到的是Block层IO调度器的修改,
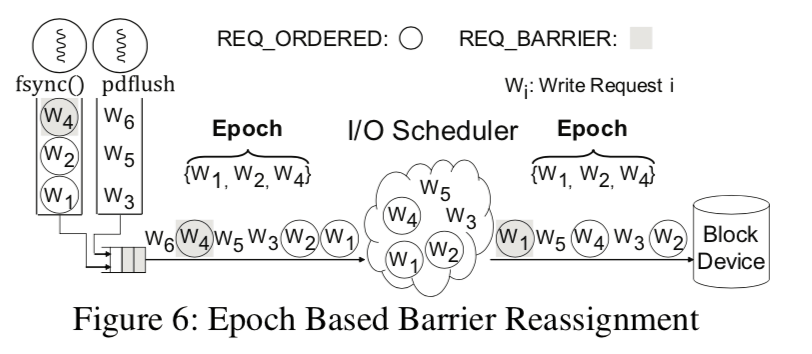
经过了上面的三个部分的工作,就可以保证从IO请求被发出到被持久化之间的偏序关系是可以得到保留的。看起来这个工作一点都不容易。
0x03 可使用屏障的文件系统
为了支持在应用层面使用这个屏障,这里条件了两个syscall: fbarrier和fdatabarrier。这个两者之间的差异和fsync和fdatasync之间的差异是一样。这两个添加的API用来表示要满足的顺序关系,而不会保证数据的持久化,
write(fileA, "Hello") ;
fdatabarrier(fileA) ;
write(fileA, "World") ;
为了优化文件系统在order-preserving的Block层上面实现更加好的性能,这篇Paper做了如下的工作,这里是对ext4文件系统进行改进:
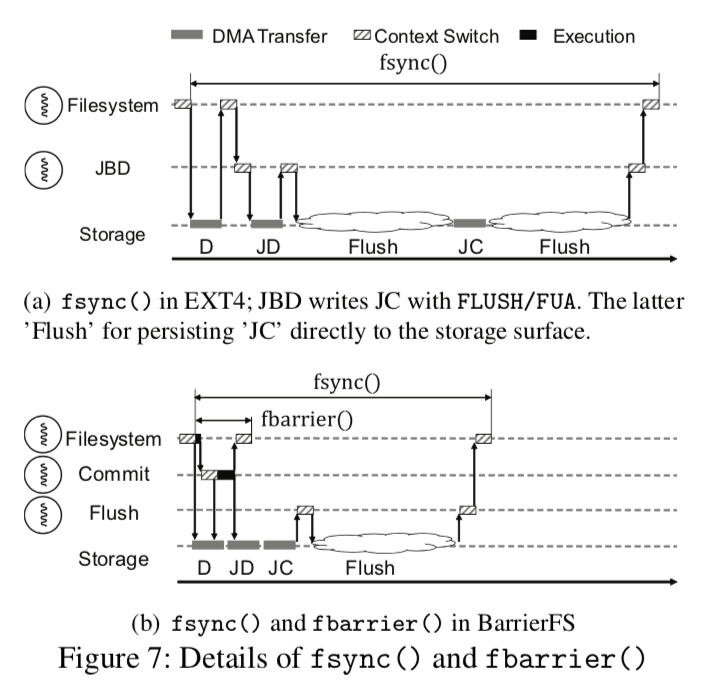
- 双模式日志,FS中日志事务的提交可以大体上分为两个任务,1. 发出JD和JC的写入请求,2. 使JD和JC持久化。这里将写入请求提交称为控制层面的操作,而数据块持久化的操作称为数据层面的操作。这两个工作在被分开,可以使用两个线程来完成操作。提交线程负责处理JD和JC的写入请求,使用写入屏障来保证它们按照顺序来持久化,由于不用等到数据被Flush,所以提交线程的写起请求操作可以是没有延时的。刷新线程负责发出flush命令和处理错误并重试,以及从事务列表中移除事务。刷新线程对不同的情况有不同的处理,对于fbarrier触发,则不发出flush命令,因为fbarrier并没有数据持久化的保证,而如果是fsync出发的话,就必须发出flush命令,在等待设备flush完成之后才从中事务列表中去除这个事务。这里将日志的操作分为了控制面的活动和数据面的活动,Paper中认为这个设计有着深远的意义,可以对目前的实现有着很大的改进。下面的图表示了之前的实现和现在的实现的对比。
-
同步原语, 在执行fbarrier和fsync的时候,BarrierFS(Paper中改动之后的文件系统的名称)以流水线的方式处理D、JD和JC。对于D,可以是1个or多个的顺序保留写入,而JD和JC使用屏障写入(barrier write)。这样这里就有两个epoch: {D,JD}和{JC}(查看[1]对于顺序保留写入和屏障写入已经epoch的定义),BarrierFS要确保它们之间的写入顺序。fbarrier调用会在文件系统发出了FC写入请求的时候的就返回,而fsync则要等到JC确保被持久化。而fdatabarrier和 fdatasync的调用由于只用处理数据部分,所以只有将D看作顺序保留写入而D中的最后一个写入看着是屏障写入,同样这两个之间的差别也和fbarrier和fsync的差别一样。
An fdatabarrier() returns immediately after dispatching the write requests for D. fdatabarrier() is the crux of the barrier- enabled IO stack. With fdatabarrier(), the application can control the storage order virtually without any overheads: without waiting for the flush, without waiting for DMA completion, and even without the context switch. fdatabarrier() is a very light-weight storage barrier. -
Paper中这部分还对在改动ext4文件系统是Page冲突和并发日志进行了说明,具体参考[1].
0x04 看几段代码
等等,2333.
0x05 评估
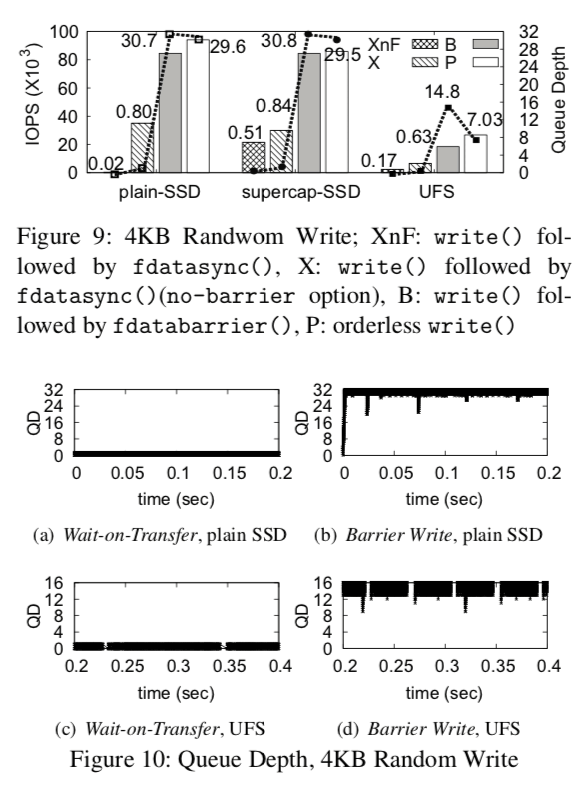
这里具体的信息还是参考[1]。在一些数据库的应用对性能的提升还是非常大的。
参考
- Barrier-Enabled IO Stack for Flash Storage, FAST’18.
- Optimistic Crash Consistency, SOSP’13.
- Consistency Without Ordering, FAST’12.
- Nightingale, E. B., Kaushik, V., Chen, P. M., and Flinn, J. 2008. Rethink the Sync. ACM Trans. Comput. Syst. 26, 3, Article 6 (September 2008), 26 pages. DOI=10.1145/1394441.1394442. http://doi.acm.org/10.1145/1394441.1394442
