LightNVM: The Linux Open-Channel SSD Subsystem
0x00 引言
继续来看关于新存储硬件的Paper。这篇Paper是FAST ‘17上面关于Linux的Open-Channel SSD Subsystem的文章。Open-Channel的主要主要目的是用来解决Log-on-Log之类的问题的。可以是应用获得很多的对SSD内部的一些组件的控制能力,这个对于一些应用特别是数据库和KVS之类的很有用,比如RocksDB。
We introduce a new Physical Page Address I/O interface that exposes SSD parallelism and storage media characteristics. LightNVM integrates into traditional storage stacks, while also enabling storage engines to take advantage of the new I/O interface. Our experimental results demonstrate that LightNVM has modest host overhead, that it can be tuned to limit read latency variability and that it can be customized to achieve predictable I/O latencies.
0x01 Open-Channel SSD管理
这里先来看看NAND Flash的一些特性和Open-Channel SSD管理的一些基本的问题。
-
基本特性,基本的存储单元为cell,每一个cell可以存储1-4个bits,bits数越低性能和耐用性越好,价格越高。bits数越多就反之。基本的接口为read/write/erase,一个NAND package中,存储介质被等级划分,从高到低分别是die, plane, block,和 page。一个die同时可以执行一个 I/O指令。而一个die里面有多个plane,一个plane可以同时执行多个flash指令。每一个plane有相同数量的blocks组成,一个blocks由相同数量的pages组成。Page是读取和写入的最小的单位,而block是最下的erase(擦除)操作的最小的单位。一个page的组成是一些固定大小的sectors和一个额外的区域组成,这个额外的区域可能用来保存ECC和用户特定的数量之类的东西。NAND flash的读操作的延时明显小于写和擦除操作的延时。
-
写入次数限制,这个对SSD优点了解的都知道,
(i) a write command must always contain enough data to program one (or several) full flash page(s), (ii) writes must be sequential within a block, and (iii) an erase must be performed before a page within a block can be (re)written. The number of program/erase (PE) cycles is limited. The limit depends on the type of flash: 10^2 for TLC/QLC flash, 10^3 for MLC, or 10^5 for SLC. -
错误模式,1. Bits Errors,指的是存储bits数据的时候出现的错误,每个cell的bits数量越多,一般这个错误的概率越大;2. 读写扰乱(Read and Write Disturb)读写cell的时候可能影响到临近的cells;3. 数据留存,一个cell数量留存的能力会逐渐降低,为了长时间持久化地保存数据可能需要多次的写入多次;4. Write/Erase,写or擦除的操作的时候可能发生错误;5. Die Failure,整个die失效,数据丢失。
几个要处理的问题:
-
Write Buffering,一个sector的大小由主机定义的时候(比如Linux的设备驱动),sector的大小可能小于一个page的消息。Write Buffering就是用来处理这个大小不匹配的问题。如果应用有通过flush这样的操作强制持久化数据,这个时候就需要填充操作。关于cache的位置,
If the cache resides on the host, then the two advantages are that (1) writes are all generated by the host, thus avoiding interference between the host and devices, and that (2) writes are acknowledged as they hit the cache. The disadvantage is that the contents of the cache might be lost in case of a power failure.除了直接在主机上面外,还可以就在设备上面,比如一些NVMe就可以使用Controller Memory Buffer (CMB)控制一些Cache的操作。
-
错误处理,前面讲到了NANF Flash可能出现的各种的错误,管理NAND Flash也就需要处理这些可能出现的错误。
Paper中还总结了几个从之前的实践中获取到的一些经验[1].
0x02 物理页地址IO接口
Physical Page Address (PPA) I/O接口是管理设备几何(geometry,翻译成什么比较好)信息的接口。它基于一个层级的地址空间。PPA的地址空间依赖于下面两个的特性:
-
SSD架构,Open-Channel的SSDs会向主机暴露一组channels,每个channel包含一组并行单元(Paralle Units, PUs, or LUNs)。这里将一个PU定义为一个设备并行性的单元,可能覆盖一个or多个设备上面的die。每一个PU可以同时处理一个IO请求;
-
Media架构,NAND chips被分为上面提到的层级的组成:Blocks,Pages,Sectors。可比特寻址的memories(这里应该指的是可byte寻址的存储设备,比如非易失性内存之类的)可能被组织为一个sectors的扁平的地址空间;
In the rest of this paper, we assume that a PU corresponds to a single physical NAND die. With such a physical PU definition, the controller exposes a simple, well-understood, performance model of the media.
由于不同种类的SSD也有着不同的特点,这里讨论的两种一个就是常见的基于层级组成的SSD,另外一种就是可byte寻址的设备,对此这里有不同的地址的处理方式,
PPAs are organized as a decomposition hierarchy that reflects the SSD and media architecture. For example, NAND flash may be organized as a hierarchy of plane, block, page, and sector, while byte-addressable memories, such as PCM, is a collection of sectors. While the components of the SSD architecture, channel and PU, are present in all PPA addresses, media architecture compo- nents can be abstracted.
每个设备被定义为一个在PPA地址组织向的bit数组。PPA对每个设备最大的Channel的数量,每个PU最大的Block的数量没有做限制,而有具体的设备处理。

一个64bits的地址的值可以有逻辑上和物理上的抽象,示例如上图所示。注意的是不一定所有的地址值都是有效的,地址空间也可能存在“空洞”。一个SSD需要暴露出下面一些特点才发表主机对SSD进行管理:
- Geometry特性,就是上面的PPA地址的维度以及每一个维度的大小的信息,比如多少Channel,每一个Channel多少PU等。这里假设一个SSD的这些信息是一致的,如果一个SSD内部不同的部分这些特性不相同,就得使用不同的地址空间来处理;
- Performance特性,一些性能的基本信息,比如数据指令的性能,还有比如一个读写以及擦除操作分别的最大的延迟,一个Channel内最多能同时处理的指令数量;
- Media特定的元数据,包括NAND flash类型、multi-plane操作是否支持、可访问的out-of-bound的信息等;
- Controller functionalities,写入buffering、错误处理等的信息;
此外,还有关于Vectored I/Os的一些信息[1],向量IO的目的是如何利用好SSD的并行性。
0x03 LightNVM
LightNVM被分为三层:NVMe设备驱动、LightNVM子系统和高层次的IO接口。每一层提供不同的SSD的抽象。
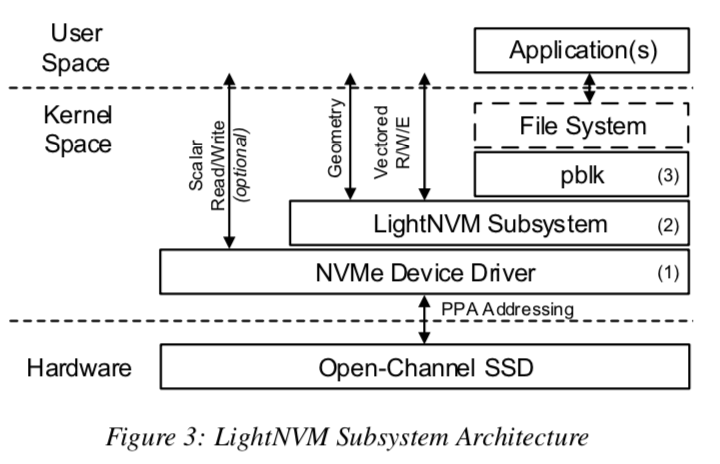
- NVMe设备驱动,通过这个驱动,内核模块就可以通过PPA IO接口访问SSD,这个驱动会和其它的设备一样给用户暴露一个设备抽象,用户可以通过ioctl之类的接口控制设备;
- LightNVM子系统,构建在PPA IO接口之上,可以通过此字系统保留SSD的Geometry的特性,它还暴露处理vector接口方便处理vector IOs;
- High-level I/O 接口,暴露一个block IO接口or其它类型的接口;
pblk: 物理块设备
如上面的图所示,LightNVM中的高层级的接口表示的是pblk。pblk主要是实现了一个FTL,暴露了一个传统的块设备的接口。此外,pblk还处理下面的一些东西:1. 处理控制器后者是媒介特定的限制;2. 映射逻辑地址到物理地址(4KB粒度);3. 错误处理;4. GC的实现;5. 处理flush(刷新)。这里其实就是一般的SSD它自己要实现的一些东西搬到了主机上面的pblk来实现。关于这些实现的一些细节(暂略)[1]。
0x04 评估
这里具体参考[1].

参考
- LightNVM: The Linux Open-Channel SSD Subsystem, FAST’17.
