Optimistic Crash Consistency
0x00 引言
这篇Paper是Paper[2]中提及到的比较多的一篇Paper,发表在SOSP’13上面。这篇Paper是一篇非常好的一篇Paper,墙裂推荐。主要探讨的是文件系统中一致性和性能之间的权衡的问题。另外[3]是一个理解这篇Paper的好Presentation。Paper提出了一个Optimistic Crash Consistency的方法来解决文件系统中的Crash的一致性的问题。Paper中提出了两个新的系统原语: osync和dsync(现在的系统中有的是fsync和fdatasync)来将写入的顺序和持久化的顺序分离开。通过使得应用可通过OptFS提供的API来实现不必要使用flush的方式来实现写入的顺序从而提高性能,
OptFS improves performance for many workloads, sometimes by an order of magnitude; we confirm its correctness through a series of robustness tests, showing it recovers to a consistent state after crashes. Finally, we show that osync() and dsync() are useful in atomic file system and database update scenarios, both improving performance and meet- ing application-level consistency demands.
0x01 背景
文件系统的持久化保证和性能之间的权衡是很多系统必须处理的问题,也是一个很棘手的问题。
-
先来看看现在的IO栈和硬件的两个特点:1. 缓冲,无论是OS的Page Cache还是磁盘本身内部的Cache,未来提高IO栈的性能,缓冲是被普遍使用了,带来的问题就是持久化在一些情况下可能就等不到保证了,使用为了解决这个问题常用的方式就是同步IO和Flush的繁华似;2. 乱序,iO请求从进程发出之后,最终持久化的顺序和持久化的顺序不一定是相同的,OS以及硬件都有可能对这些操作进行重排序。在对这个顺序很敏感的一些应用,比如数据库的某些文件IO,就必须等到前面的IO完成才会进行后面的IO,以此保证顺序。
-
现在日志文件系统的一些操作逻辑:一个文件系统的写入来说,一般都要写数据和元数据。写数据操作(D)一般是最先进行的,其次是写元数据的日志的操作(J-M),再然后就是写入一个提交块(J-C),J-C持久化之后代表这个事务以及完成了。最后正式去更新元数据(M)(即使到这里失败了,也可以通过日志重做)。到这里就代表一个写入操作完成了(注意这里的细节,后面的asynchronous durability notifications的基本的思路与这里相关)。所以顺序可以表示为 \(\\ D \to J_{M} \to J_{C} \to M \\ 这里可以采用的一个优化就是D和J_{M}之间的顺序是可以打乱的。这样顺序就可以表示为D|J_{M} \to J_{C} \to M.\) 当使用checksum(这个写入事务相关的checksum,保存到J_{C}中)的优化方式时,J_{M}和J_{C}时可以同时发出操作,这样就可以表示为 \(\\ D \to \overline{J_{M}|J_{C}} \to M\) 但是前面的两点的优化时不能同时存在的。另外就是事务之间存在的顺序关系: \(\\ Tx_{i} \to Tx_{i+1}\) 这个被称作是悲观的日志方式(Pessimistic Journaling)。这里保证进行下一个操作前一个操作的数据已经持久化了的基本的一个方法就是使用Flush操作。
-
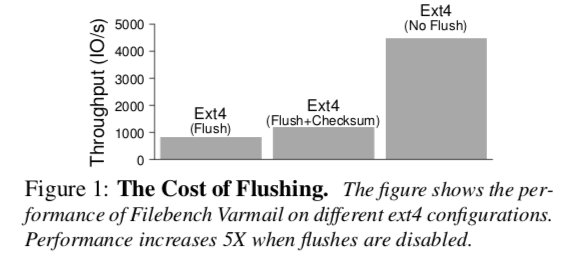
Flush带来的性能影响。由于不同层级时间的存储设备的速度存在巨大的差异,也就会导致Flush的操作的成本非常高,下面的图表示出了这一点:
0x02 概率性的Crash一致性
这里说的Probabilistic Crash Consistency是一种放弃一些情况下的一致性的保证来提高性能的方法。基本思路的思路就是省去一些Flush的操作。后果就是可能的不一致的状态,下面的图表示了一个例子:

Paper中对这里的不一致进行了仔细的量化分析[1]。这里暂时没有包含这一个部分,
... refers to specifically is two orderings: JM → JC and JC → M. In the first case, Ts’o notes that the disk is likely to commit JC to disk after JM even without an intervening flush (note that this is without the presence of transactional checksums) due to layout and scheduling; disks are simply unlikely to reorder two writes that are contiguous. In the second case, Ts’o notes that JC → M often holds without a flush due to time; the checkpoint traffic that commits M to disk often occurs long after the transaction has been committed, and thus ordering is preserved without a flush.
0x03 乐观的Crash一致性
接下来就是这篇Paper要将的解决方案了。这个方案被称为乐观的Crash一致性(Optimistic Crash Consistency)。这个方案注意基于两个主要的ideas:
-
使用Checksum的方式可以检测数据写入的完整性。这个一般在Crash恢复的时候使用,
Optimistic crash consistency eliminates the need for ordering during transaction commit by generalizing metadata transactional checksums to include data blocks. During recovery, transactions are discarded upon checksum mismatch. -
使用asynchronous durability notifications的方式来一个事务的checkpointing操作(这里有点像Amazon Aurora(MySQL)中的一个事务提交的优化)。基本的思路就是使用异步通知的方式来通知checkpointing操作持久化了。这个不会对应用的性能产生影响,因为IO操作只会被阻塞到这个IO操作事务完成的时候,而不是一直阻塞到它被已经是checkpointed,
... Fortunately, this delay does not affect application performance, as applications block until the transaction is committed, not until it is checkpointed. Additional techniques are required for correctness in scenarios such as block reuse and overwrite.
Asynchronous Durability Notification
现在的文件系统实现写入以特点的顺序初始化使用的基本的方法就是上层的问题让下层的设备在写入操作之后在刷新其Cache。而实际上,这些写入的顺序在正常的情况下是不重要的,它们一般也不是写入同一个地方,而是一种逻辑上的先后关系,比如前面讲的日志式文件系统一个事务的执行过程。但是在发生Crash的时候,这个顺序的意义才会显示出来。
由此,这里就想办法来放松这里的顺序的要求。为了让文件系统在Crash的时候在放松了这里顺序的限制的情况下依然能保持一致性。这里就是提出了一种叫做asynchronous durability notification的方法。使用异步通知的方式来通知执行的结果,这里一个写入操作会上层的文件系统会收到两个通知,一个是设备接收到了这个写入操作的请求,后一个是写入的数据已经持久化了。
Optimistic Consistency的特性
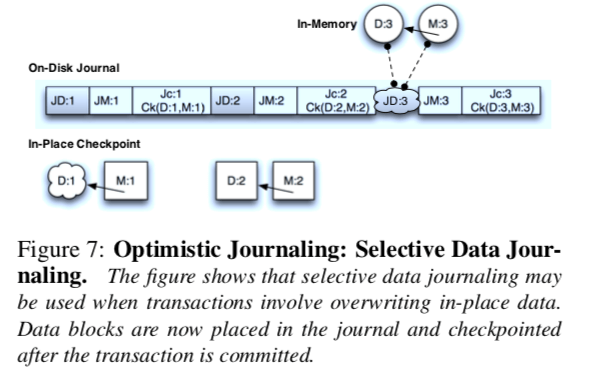
下面是一个乐观式日志的示意图:

上面提到的概念比较抽象,下面举一个例子来说明:
-
上面的图中,Tx0的各个D,J-M,J-C都已经成功持久化,这个时候就可以认为这个写入操作可以提交了,进行M操作;
-
对于Tx1来说,即使启动的部分持久化了但是D操作的数据没有持久化,这个时候恢复操作的时候会检查到checksum对不上,从而知道这个操作没有完成,即使相关的元数据已经持久化了。对于Tx2来说,它可以可Tx1并行进行,相关的数据存在没有成功持久化的时候也会在恢复的时候被检查出来;
-
对于Tx3来说,即使它的数据都已经持久化了,但是由于它之前的事务没有持久化,它也不能提交,
Even if the file system is notified that D: 3, JM : 3, and JC : 3 are all durable, the checkpoint of M:3 cannot yet be initiated because essential writes in T x: 1 and T x: 2 are not durable (namely, D: 1 and JC : 2). T x: 3 cannot be made durable until all previous transactions are guaranteed to be durable; there- fore, its metadata M:3 cannot be checkpointed.
使用的技术
为了实现Optimistic Consistency,Paper中说明了下面的被使用了的技术:
-
In-Order Journal Recovery,用来保证恢复操作的时候按照逻辑顺序进行(不一定和物理的顺序一致),一个没有提交的操作后面的操作也不同管了,技术它的数据都持久化了;
-
In-Order Journal Release,释放操作的时候由于乱序的存在,要保证不要释放不应该释放的数据;
-
Checksums,常见的metadata transactional checksumming方式可以用来放松J-M和J-C之间的顺序。一种类似的但是更加复杂的方法是data transactional checksumming,也是Optimistic Consistency使用方法。基本的思路就是计算数据的checksum,相关数据保存在J-C之中,
With the data checksums and their on-disk block addresses stored in JC, the journal recovery process can abort transactions upon mismatch. Thus, data transactional checksums enable optimistic journaling to ensure that metadata is not checkpointed if the corresponding data was not durably written. -
Background Write after Notification,讲一些写操作放入后台进行;
-
Reuse after Notification,这里要解决的问题就是在前面的A操作删除一个文件之后,之后的B操作重新使用了A删除的文件使用的数据块。这样就可能导致A看到B操作的结果(类似数据库中的隔离级别中的一些情况)。这里的解决方案就是这些删除的数据块不能被马上使用,必须等到A操作新的元数据被完成更新操作,
When the file MB must be allocated a new data block, the optimistic file system allocates a “durably-free” data block that is known to not be referenced by any other files; finding a durably-free data block is straight-forward given the proposed asynchronous durability notification from disks. -
Selective Data Journaling,一种为update-in-place的优化方式,
Data journaling places both metadata and data in the journal and both are then updated inplace at checkpoint time. The attractive property of data journaling is that inplace data blocks are not overwritten until the transaction is checkpointed; therefore, data blocks can be reused if their metadata is also updated in the same transaction. The disadvantage of data journaling is that every data block is written twice (once in the journal, JD, and once in its checkpointed in-place location, D) and therefore often has worse performance than ordered journaling
持久性和一致性
Optimistic Consistency通过前面的一些方法来保证操作符合一定的顺序,以此来实现Crash时的一致性,但是并没有保证持久化。但是有的时候顺序和持久只追求其中的一个,而现在使用的方法要么是都符合要么是都不符合。这里提提出了两个新的借口:1. osync()用来保证写入操作之间的顺序,2. dsync()用来保存数据的数据化。
Now consider when every write is followed by dsync(), i.e., W1,d1,W2,d2,...,Wn,dn. If a crash hap- pens after di, the file system will recover to a state with W1,W2,...,Wi applied.
If every write was followed by osync(), i.e., W1,o1,W2,o2,...,Wn,on, and a crash happens after oi, the file system will recover to a state with W1,W2,...,Wi−k applied, where the last k writes had not been made durable before the crash. We term this eventual durability. Thus osync() provides prefix semantics
0x04 OptFS实现
Paper中还讨论了对于上面提及到基本设计思路和使用的技术的具体实现,可以参看[1].
0x05 评估
具体参看[1].
参考
- Optimistic Crash Consistency, SOSP’13.
- Barrier-Enabled IO Stack for Flash Storage, FAST’18.
- http://research.cs.wisc.edu/adsl/Publications/optfs-sosp13-slides.pdf, OptFS SOSP13 Slides.
