Evolving Ext4 for Shingled Disks
0x00 引言
这篇Paper是关于ext4文件系统在叠瓦式磁盘上面的一个优化。由于SMR磁盘极差劲的随机写的性能,在ext4原本的工作方式下面,文件系统的性能会下降得非常明显。特别是ext4文件系统还是起源于Unix FFS文件系统,其元数据的写还是一些随机写的操作。这篇Paper讲的就是如何优化ext4文件系统更新元数据时的性能,
... We present benchmarks on four different drive-managed SMR disks from two vendors, showing that ext4-lazy achieves 1.7-5.4× improvement over ext4 on a metadata-light file server benchmark. On metadata-heavy benchmarks it achieves 2-13× improvement over ext4 on drive-managed SMR disks as well as on conventional disks.
0x01 背景与基本思路
叠瓦式磁盘由于增大存储容量的方法是让磁盘的磁道像瓦片一样叠在一下,消除了传统的机械磁盘上面的磁道之间的间隔。这样的到来的缺点就是磁盘的数据只能顺序写,就类似于磁带一样。因为写入前面的磁道会导致覆盖其它的数据。为了让缓解这个问题,叠瓦式磁盘讲存储空间分为zone,zone之间是存储间隔的,一个zone里面的写入操作就不会影响到另外的zone。zone的大小多为256MB。叠瓦式磁盘要写入一个zone中间的数据,就得把这个zone里面所有的数据都读出来,修改之后写回。
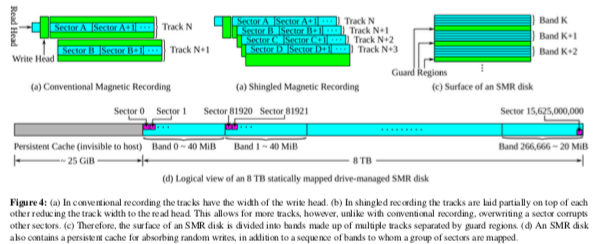
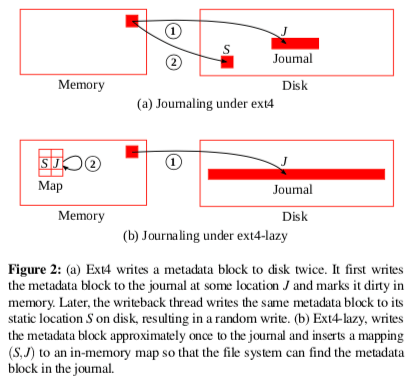
ext4使用bitmap来管理磁盘的空闲的空间。而写入导致会更改这些信息,这里就会造成随机写入的操作。这里提出的ext4-lazy的思路如下图所示。ext4写入操作的时候,元数据回写入日志一次,写入元数据所在的区域一次。而这里的优化就是利用了日志中写入的元数据。通过一个暂时的映射,jmap,记录在相关的最新元数据在日志中的位置。这个jmap在文件系统挂在的时候扫描日志来构建,在运行的时候回不断更新。这些数据回在需要的时候写会元数据原来的应该在的位置。另外,文件系统的访问也存在局部性的特点,
... file system metadata comprises a small set of blocks, and hot (frequently updated) metadata is an even smaller set. The corollary of the latter observation is that managing hot metadata in a circular log several times the size of hot metadata turns random writes into purely sequential writes, reducing the cleaning load on a DM-SMR disk.
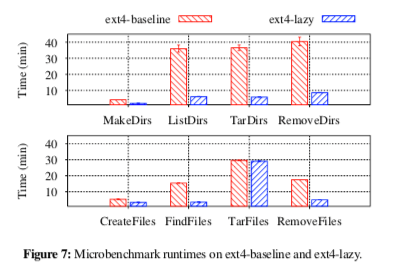
0x02 评估
这里的具体信息可以参看[1],
iJournaling: Fine-Grained Journaling for Improving the Latency of Fsync System Call
0x10 引言
这篇Paper也是关在如何优化fsync操作的一篇文章。在fsync的语义中,它的sync操作是针对某个文件来说的,但是在很多文件系统的实现中,还是回涉及到很多与这个文件无关的一些操作。Paper中针对的文件系统是ext4文件系统。iJournaling通过引入一个额外的iJournaling日志来实现更加细粒度的fsync操作。
0x11 背景与基本原理
在Linux中ext4文件系统的日志提交的一个示例如下图,这个示例的应该是工作在ext4默认的ordered的模式下面。一个fsync操作在这里执行的大概步骤是,1. 更新对应文件的元数据,并添加到一个JBD2的事务中,并将对用的数据Blocks刷到磁盘上面,2. 如果对用JBD2事务仍然处于运行的状态,则向其发送一个提交的操作。这里存在这样的基本影响到性能的问题,1. JBD2使用一个线程执行提交的操作,也就是说同一时间只会有一个事务提交,2. 一个事务在执行提交操作的时候,阻塞后面的提交操作。这种情况在多个线程(进程)都执行fsync操作的时候变得更加严重。
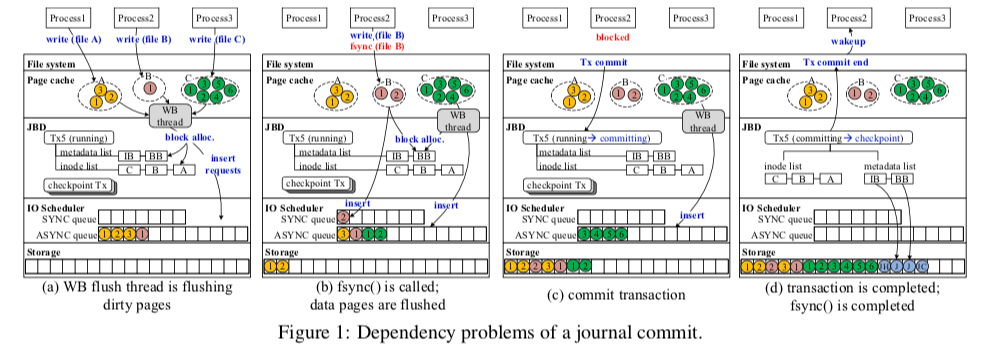
iJournaling的主要思路就是引入另外的一个日志区域,相关的操作称之为i-transaction。在iJournaling中,日志只会包含最小能够从故障中恢复的对于被修改文件系统的元数据,这里应该是基于ext4的ordered的模式。不像JBD2中提交可能涉及到多个文件,这里是单个文件系统上的操作,
Only file-level metadata such as an inode entry and the external extent structures of the target file, and any related directory entries (DEs), are recorded. Other modified metadata blocks shared by other files, such as GDT, block bitmap, inode bitmap, or inode table, are not flushed into the ijournal area. They can be recovered during the crash recovery time using com- mitted i-transactions.
i-transaction这样做的优点就是完全兼容了fysnc的语义以及之前文件系统修改部分的实现,只是相当于额外的一个功能增强的Patch。这个i-transaction的日志区域是每一个CPU核心一个单独的区域。这个方式在现在的一些SSD上面对更加有利一些。由于一些文件的修改与目录是相关的,这里还需要记录相关目录的改动。另外,在一些情况下仍然使用原来的fsync实现的逻辑,由于简化iJournaling的实现,比如对目录进行操作、对有hard-link的inode上面的操作的情况。日志的基本格式如下图,
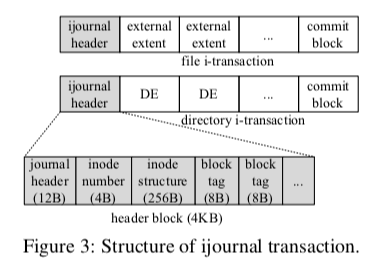
在系统崩溃之后,其中包含的数据可以让系统恢复到一个正确的状态。具体的操作在Paper中有详细说明。
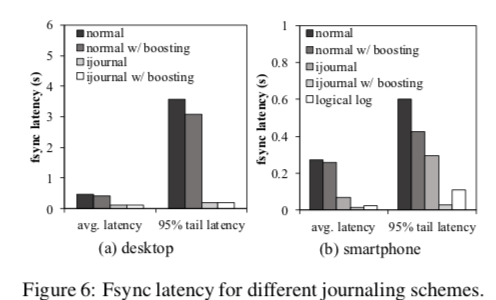
0x12 评估
这里的详细信息可以参看[2],
High-Performance Transaction Processing in Journaling File Systems
0x20 引言
这篇Paper主要将的是如何优化ext4文件系统的日志操作流程中的并发的问题。在现在ext4文件系统的实现中,运行中(running)、提交中(committing)以及checopointing的操作都是使用锁来保证并发操作的正确性。另外就是前篇Paper提到的,ext4中日志事务的提交都是单线程来处理的,在之前机械磁盘的时代,这样的设计是很适应的,但是这些设计早现在一些高速存储硬件的情况下就逐渐显示出问题。
0x21 背景和基本思路
这篇Paper要优化的第一个点就是就是ext4文件系统中的这个几个环形链表中的几个锁。
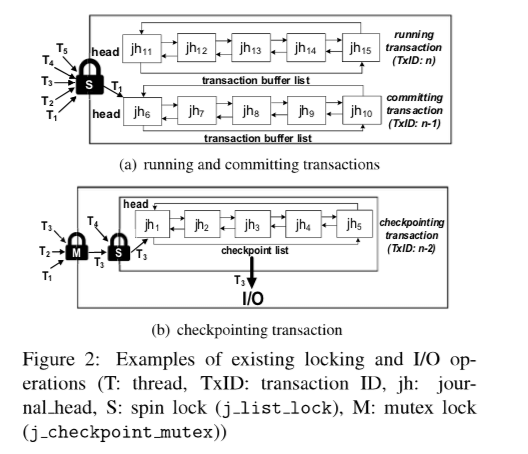
这里优化的基本思路就是把这些列表操作变成lock-free的。这个算是一种实现中编程上面的一种优化。有环形链表实现lock-free的操作比较困难,在这里将其变成了一种普通的double-linked的链表。而对于移除操作,就可以与到一些并发编程中invalid reference的问题,即尝试去释放一块内存的时候,实际上这个时候还有其它的线程正在持有这个块内存做一些操作。这里就是使用了一个两阶段释放的方法,即现将这个区域的state置为无效,然后在后面合适的时候进行实际的移除操作。
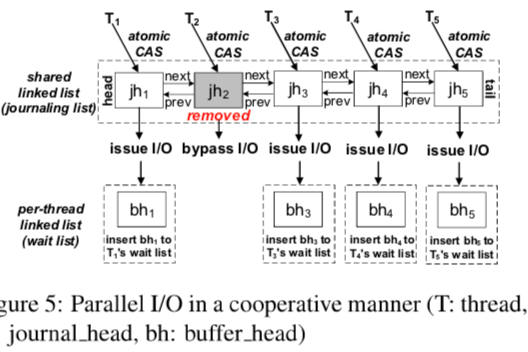
另外的一个主要的优化就是改变这里都是串行操作带来的并发性的问题。比这里的实现中,如果一个IO操作不能获取一个running transaction,可以通过添加IO操作到这个事务中的方式[3]。这篇Paper对这些方法具体的实现思路有详细的面试[3]。
0x22 评估
这里的具体信息可以参看[3],
参考
- Evolving Ext4 for Shingled Disks, FAST’17.
- iJournaling: Fine-Grained Journaling for Improving the Latency of Fsync System Call, ATC ‘17.
- High-Performance Transaction Processing in Journaling File Systems, FAST’18.
