Read-Log-Update – A Lightweight Synchronization Mechanism for Concurrent Programming
0x00 引言
RLU可以看作是RCU的升级版本。RCU在Linux Kernel 中已经得到广泛的应用了。但是其也存在一些缺点,最大的一个缺点就是很难用,其次就是只适应有很少的write操作的情形,最后就是等待读者完成操作的延时问题(具体看看RCU有关的东西?)。RLU则可以解决RCU存在的一些问题:
RLU provides support for multiple object updates in a single operation by combining the quiescence mechanism of RCU with a global clock and per thread object-level logs.
0x01 基本思路
通过使用综合了结合global clock的RCU的quiescence机制和 thread直接独立的object logs,RLU一个操作支持多个对象更新。RLU有以下的基本思路,这一部分先假设写都是顺序进行的:
- 所有操作在开始都要读取global clock(g-clock)到自己线程局部的l-lock中,使用这个lock来对共享的对象解引用;
- 对于更新操作,一个线程先将对象拷贝到自己的log中,在自己的log中操作这个对象,这里要获取object(s)的lock;这里读操作不需要申请任何lock(s),可以直接访问对象;
- 对于write操作,为了提交这次的更新,这个线程要先递增g-lock,这样就将各个线程的操作分为了两个部分:
- 在这个递增之前发起的;
- 在这个递增之后发起的;
- 对于前者,这些操作它们会读取旧的object(s),对于后者,这些操作会读取更新线程的log中的副本;
- 更新的线程等到在旧object(s)上的读操作都完成之后,更新的线程然后提交更新,释放lock(s),完成操作。
下面以一个图来一步步解释:
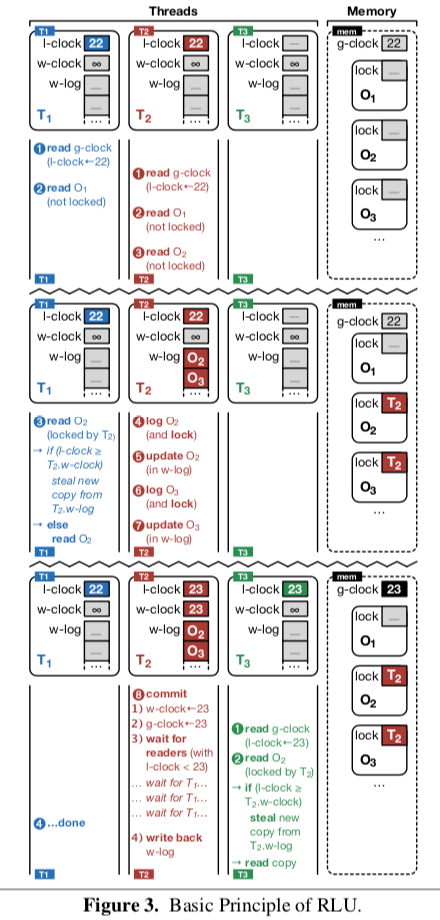
第1部分
T1和T2都先执行读操作。先读取g-clock到自己本地的l-clock之中;然后T1读取O1, T2读取 O1 O2,它什么都是直接读取,不需要lock操作;
第2部分
T2现在想要更新O2 O3,上面说到,更新都是在自己本地的log里面进行的,在此之前,T2要先申请O2 O3上的 RLU shared locks 。这个时候T1想要读取O2,然后它就会发现被T2 locked了,T1就去查看T2的w-clock,发现无穷大,T1就知道T2还没有提交更新的对象,T1就知道了自己的操作不在这个更新之后才发生的,这样它就应该直接去读取原来的object。
第3部分
T2完成了自己的更新操作,准备提交这次更新。它先递增clock,写到自己的w-clock,然后就是将递增之后的写到g-clock。不过此时T2要等到之前的操作都完成,这里是T1的操作。等到T1完成,T2就可以将对象安全写回,然后释放lock(s)。对于T3,由于它是属于之后的操作,就可以不用管了。对于T3的读取,如果T2次时没有将更新写回,它就比较T2的w-clock,发现T3的 l-clock >= T2的w-clock,他就可以去T2的log里面读取数据。
0x02 Synchronizing Write Operations
如果让RLU支持并发写操作呢?这里使用的直接就是细粒度的lock。
Another approach is to use fine-grained locks. In RLU, each object that a writer modifies is logged and locked by the RLU mechanism. Programmers can therefore use this locking process to coordinate write operations. For example, in a linked-list implementation, instead of grabbing a global lock for each writer, a programmer can use RLU to traverse the linked list, and then use the RLU mechanism to lock the target node and its predecessor. If the locking fails, then the operation restarts, otherwise the programmer can proceed and modify the target node (e.g., insertion or removal) and release the locks.
来看看伪代码,enjoy it:

0x03 一个优化
上面的伪代码中,可以发现writer每次提交都要call RLU_SYNCHRONIZE函数(第47行)。目的就是等待其它读者完成旧object(s)上面的操作,这里的一个优化就是尽可能地将这个操作推迟:
On commit, instead of incrementing the global clock and executing RLU synchronize, the RLU writer simply saves the current write-log and generates a new log for the next writer. In this way, RLU writers execute without blocking on RLU synchronize calls, while aggregating write-logs and locks of objects being modified.
Interval-Based Memory Reclamation
0x10 引言
和前面的RLU一样,Interval-Based Memory Reclamation(IBR)也是一种多线程并发控制的一种机制。它要解决的问题和RCU一样,也是在并发访问的情况下,如何在合适的时候回收内存。
0x11 基本思路
Interval-Based Reclamation和Epoch-Based Reclamation很类似。EBR是一种基于时间的方式,记录线程回访问的最早数据的Epoch,之前的数据就可以安全地进行数据回收的操作。这个方式是很多KVS、数据系统中常用的一种方式。但是这种的一个缺点在于一个停顿的线程可能给内存的回收带来严重的负面影响。与EBR一样,IBR也会记录一个全局的Epoch。另外还会记录一个对象的birth epoch和retire epoch,这两个epoch代表了这个对象的生命周期。下面是一个示例的伪代码。和EBR不同的是,它记录分配内存的次数,每经过若干的次数,会增加epoch的计数。对象要释放的时候使用retier喊出,这里就会记录这个对象retire的epoch。在之后合适的时候进行内存回收的操作。

0x11 评估
这里的具体信息可以参看[3],
参考
- Read-Log-Update: A Lightweight Synchronization Mechanism for Concurrent Programming, SOSP 2015.
- Austin T. Clements, M. Frans Kaashoek, Nickolai Zeldovich, Robert T. Morris, and Eddie Kohler. 2015. The scalable commutativity rule: Designing scalable software for multicore processors. ACM Trans. Comput. Syst. 32, 4, Article 10 (January 2015), 47 pages. DOI: http://dx.doi.org/10.1145/2699681.
- Interval-Based Memory Reclamation, PPoPP’18.
