Linux Block IO: Introducing Multi-queue SSD Access on Multi-core Systems
0x00 引言
这篇Paper讲的是Linux Multi-Queue Block Layer。Linux Multi-Queue Block Layer主要是为了解决现在的Linux Block Layer不能很好地使用新的高速的存储硬件(比如4k读写能得到100W的超高速的NVMe的SSD)。Multi-Queue Block Layer在Linux 3.x的后期合并到了Linux内核主线,在Linux 4.x变化比较大。 硬件性能的快速变化,这里还只是2012年的数据,实际上现在的SSD的性能比这些数据高出很多。
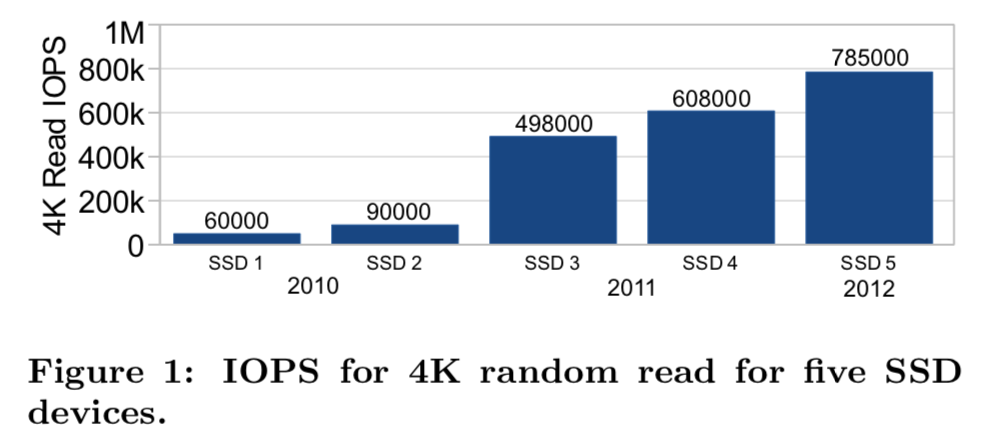
0x02 目前的问题
Linux目前的Block Layer都是为HHD优化设计的。
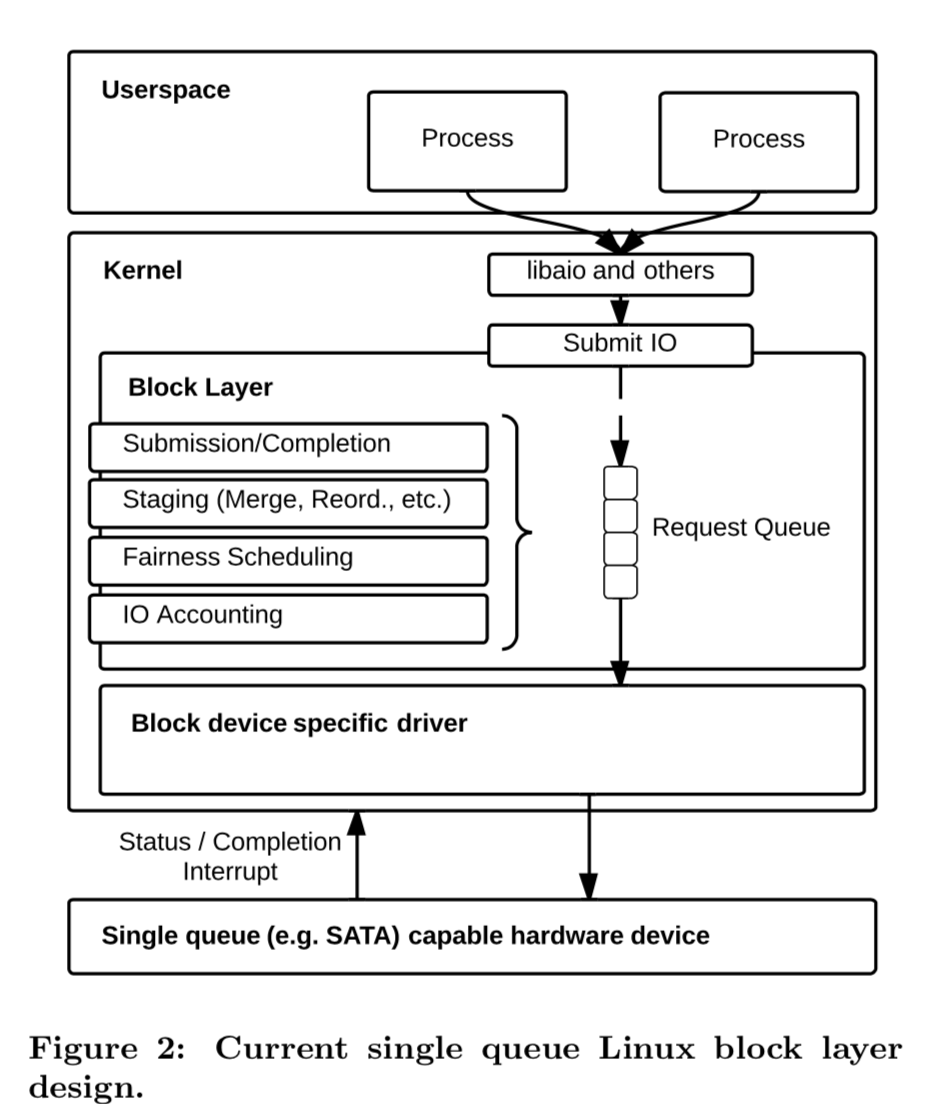
IO操作在Block Layer中会经过复杂的操作才会被执行,在高速的存储硬件目前暴露出了以下的缺点:
- Request Queue Locking,现在的请求队列只的操作中,会频繁地使用锁,而这里的很多锁都是全局的,也就是说所有经过这里的请求都有可能形成竞争。在HHD这样性能比较低的硬件上,带来的竞争不明显。但是在SSD上,这里的竞争、同步操作显著了性能。
- Hardware Interrupts,IOPS达到了几十万甚至更加高的时候,很多的时间就会被消耗在中断处理上了。
- Remote Memory Accesses,目前的设计会导致CPU核心访问的会是Remote Memory,这个造成了不小的性能损失,特别是在NUMA架构的机器上。对缓存也不友好。
0x03 基本设计
顾名思义,Mutil-Queue就是由对个队列,不过不是简单的拆分而言,还要考虑到block layer上层和block layer下层各自的特性。这里使用两级队列的结构,上层的软件队列和下层的硬队列,两个队列实现不同的功能,对应不同的优化策略。
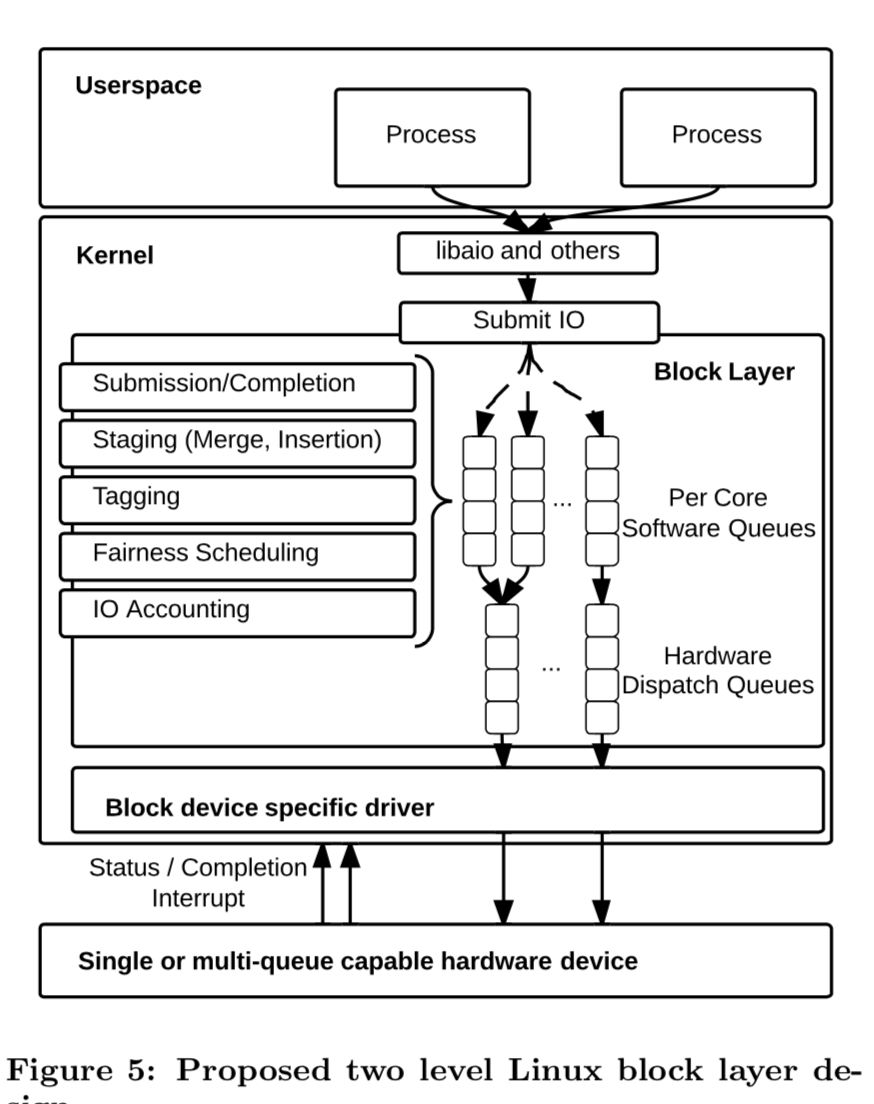
Software Staging Queues
多个Software Staging Queues为了减少请求之间的竞争,数量根据CPU数量 or CPU核心的数据确定,这个数量的确定是在lock竞争、缓存友好性和内存等资源消耗之间的一个权衡。
So, on a NUMA system with 4 sockets and 6 cores per socket, the staging area may contain as few as 4 and as many as 24 queues. The variable nature of the request queues decreases the proliferation of locks if contention on a single queue is not a bottleneck. With many CPU architectures offering a large shared L3 cache per socket (typically a NUMA node as well), having just a single queue per proces- sor socket offers a good trade-off between duplicated data structures which are cache unfriendly and lock contention.
Hardware Dispatch Queues
Hardware Dispatch Queues利用的是存储设备自己的并行特点,具体的数量设置根据设备的特点决定,可在1 - 2048个之间选择。这里不负责顺序保障,这部分的工作在上面的层级保障。对于NVMe的SSD,一般有对个提交队列以及多个完成队列,这里的设计就显得更加重要。
Because IO ordering is not supported within the block layer any software queue may feed any hardware queue without needing to maintain a global ordering. This allows hardware to implement one or more queues that map onto NUMA nodes or CPU’s directly and provide a fast IO path from application to hardware that never has to access remote memory on any other node.
Software 和 Hardware之间的队列不一定是一一对应的关系。Software Staging Queues可以利用之前block layer的一些优化策略。
IO-Scheduling & Tagged IO and IO Accounting
现在的IO-Scheduling想尽办法地将随机操作转化为顺序操作,所以要做很多的额外的工作。这里的实现方式不同,在Hardware Dispatch Queues上面的IO请求,使用的是简单的FIFO的策略。与此同时,为了在HHD之类的硬件上or保持兼容性等的原因。请求全局的重排序也是可以在Mutil-Queue中实现的,实现的位置在Software Staging Queues。对于现在默认的保证公平的IO调度器(就是CFQ IO调度器),是在IO性能不足下的一种资源分配策略,而如果是高速的存储硬件,IO性能是充足的,也就不需要复杂的调度策略。这里Paper中也没有把问题说死:
If fairness is essential, it is possible to design a scheduler that exploits the characteristics of SSDs at coarser granularity to achieve lower performance overhead. Whether the scheduler should reside in the block layer or on the SSD controller is an open issue. If the SSD is responsible for fair IO scheduling, it can leverage internal device parallelism, and lower latency, at the cost of additional interface complexity between disk and OS.
为了与前面的两级队列相适应,在其它方面也走出了一些优化。
- tag-based completions,一个tag 是一个整数,标示出了一个IO请求在驱动submission queue中的位置。当完成这个标记后(一种指示操作?),就意味着对应的IO操作以及完成。避免了一些搜索。
- 更加细粒度的统计功能,同时考虑了software queues 和 dispatch queues。也方便了blktrace之类的工具对IO的追踪操作。
Multiqueue Impact on Device Manufacturers
对于制造商来说就是驱动的优化了,主要是dispatch queue,submission queue ,IO tag handling 的处理。
0x04 评估
具体参看论文:
With SQ, the maximum latency reaches 250 milliseconds in the 4 sockets system and 750 milliseconds on the 8 sockets system. Interestingly, with SQ on a 8 sockets sys- tems, 20% of the IO requests take more than 1 millisecond to complete. This is a very significant source of variability for IO performance. In contrast, with MQ, the number of IOs which take more than 1ms to complete only reaches 0.15% for an 8 socket system, while it is below 0.01% for the other systems. Note Raw exhibits minimal, but stable, variation across all systems with around 0.02% of the IOs that take more than 1ms to complete.
参考
- Linux Block IO: Introducing Multi-queue SSD Access on Multi-core Systems, SYSTOR ’13.
