NVMeDirect: A User-space I/O Framework for Application-specific Optimization on NVMe SSDs
0x00 引言
这篇Paper是关于在user-space实现一个为NVMe SSD优化的IO framework。与此类似的有SPDK。原来的内核的IO framework显得过于复杂,在高速的SSD面前显得开销太大,并不能很好的适应现在的NVMe的SSD,和一些network framework一样,这个NVMeDirect也尝试将其移到user-space来获取更好的灵活性和更高的性能,
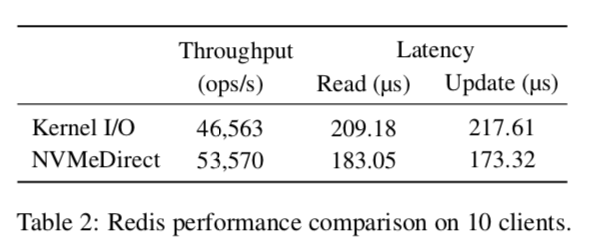
... the proposed framework provides flexibility where user applications can select their own I/O policies including I/O comple- tion method, caching, and I/O scheduling. Our evaluation results show that the proposed framework outperforms the kernel-based I/O by up to 30% on microbenchmarks and by up to 15% on Redis.
SPDK也是一个类似的framework,它的缺点是只支持单一的用户和应用,而NVMeDirect会尝试解决这些问题。这篇Paper只有5页,对比那些动不动就十几页的还是很短的。NVMeDirect的一些思路和netmap很像。
0x01 基本设计
在NVMe SSD中,一个很重要的概念就是队列(其实很多其它的存储设备也是)。NVMe可以提供多个的IO队列,单个的NVMe SSD可以提供多大64K个的队列,而一个队列可以管理多达64K个命令。这个数量是远超过一半的存储设备的。当一个向NVMe SSD发送一个IO命令时,先是将其放置到submission queue(SQ),然后通过doorbell寄存器来同时NVMe SSD。当NVMe SSD完成一个IO命令时,它将结果放入completion queue(CQ),然后使用中断的方式来通知系统。由于在高速的硬件下面,中断也是一个开销很大的操作,在这里使用了MSI/MSI-X和中断聚合的方式来提高性能。和其他很多优化一项,现在的Liunux Kernel也使用了per-core的数据结构来减少冲突。
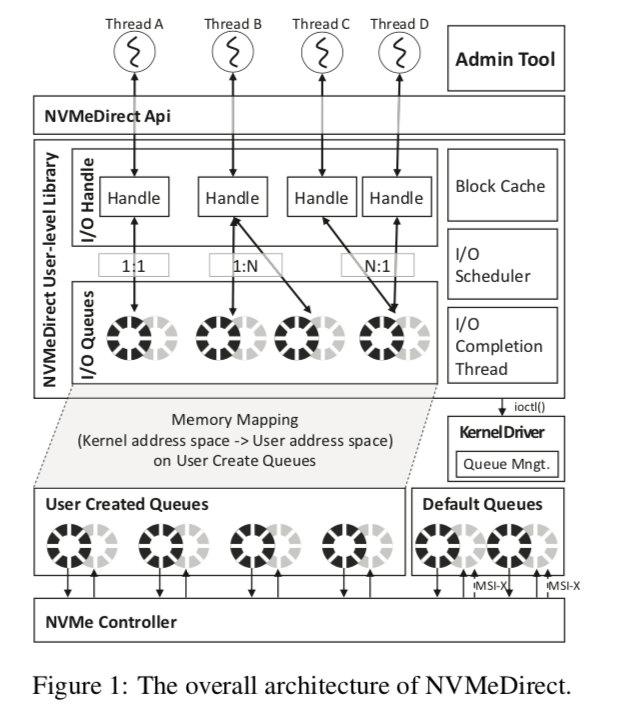
下面的图基本表示出了NVMeDirect的基本架构。在NVMeDirect中,一个叫做Admin Tool的工具控制,它是拥有root权限的。它管理应用对IO队列的访问。当一个应用请求一个IO队列的时候,在通过了权限检查之后。然后会给这个应用创建一个SQ和一个CQ,在讲其加上doorbell寄存器都映射到应用的内存空间的一个区域。这样,应用就可以通过直接访问这些内存区域来对这些队列进行操作,从而实现在user-space使用IO framwork。
0x02 一些细节
在上面的图中可以看出,应用对IO队列的操作使用了一个handle的抽象,handle和队列的映射存在不同的对应关系:1:1,1:N和N:1。Handle可以根据具体的情况设置不同的参数。Handle的抽象对提高灵活性很有帮助,比如可以通过一个handle绑定到不同的队列上来实现读写分离,减少相互的感染,另外也可以多个handle绑定到一个共享的队列上面。下面是一些提供的API:

在传统的IO栈中常见的Block缓存、IO调度器和IO completion线程之类的组件都是提供的。这里相比而言,应用可以根据自己的情况选择不同的设置,这样的灵活性就是实现在内核中的IO栈就高多了,
* Block cache manipulates the memory for I/O in 4KB unit size similar to the page cache in the kernel. Since the NVMe interface uses the physical memory addresses for I/O commands, the memory in the block cache utilizes pretranslated physical addresses to avoid address translation overhead.
* I/O scheduler issues I/O commands for asynchronous I/O operations or when an I/O request is dispatched from the block cache.
* Since the interrupt-based I/O completion incurs context switching and additional software overhead, ... , NVMeDirect utilizes a dedicated polling thread with dynamic polling period control based on the I/O size or a hint from applications to avoid unnecessary CPU usage.
这里的IO completion线程作为一个独立的线程,使用轮询检查IO的完成情况。多个CQ可以共享一个IO completion线程,or 单个CQ可以使用专有的线程。不同的配置可以根据应用自身调整,这也是它的一个灵活性的表现。此外,轮询周期可以根据应用的IO特性动态调整。 在实现中,NVMeDirect主要有三个组件组成,queue management, admin tool和user-level library。前两个运行在内核空间之中,而后者是用户空间内的一个函数库。如前面所言,admin tool类似于一个Master的存在,做为一个管理者。Queue management则具体地去管理队列的创建和管理,并负责请需要的东西映射到用户空间中。
0x03 评估
具体参考[1]。
参考
- Hyeong-Jun Kim, Young-Sik Lee, and Jin-Soo Kim, “NVMeDirect: A user-space I/O Framework for Application-specific Optimization on NVMe SSDs,” Proceedings of the 8th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage), Denver, Colorado, USA, June 2016.
