Split-Level I/O Scheduling
0x00 引言
这篇文章是SOSP‘15上一篇关于IO调度的文章。主要的思路就是在block, system call, 和page cache三个层面实行分开的IO调度的逻辑,实现了更加好的效果。Split-Level I/O Scheduling是一个IO调度的框架,在这个框架之上可以实现具体的调度算法。
our Actually Fair Queuing sched- uler reduces priority-misallocation by 28×; our Split-Deadline scheduler reduces tail latencies by 4×; our Split-Token scheduler reduces sensitivity to interference by 6×. We show that the framework is general and operates correctly with disparate file systems (ext4 and XFS).
0x01 基本思路
传统的IO调度器一般是实现在block层的。这样的调度器存在2个主要的缺点,一个也是最重要的,block-level的调度器无法对这样的一些文件系统小心保证顺序的以达到一致性的写请求进行重排序。第二个就是无法进行精确的统计,它缺乏用于知道那一个原因负责哪一个IO请求的信息。Split-level I/O scheduling的解决办法就是这个调度器是跨越了多个layer的,即 system-call, page-cache,和 block layers三个层面。Split schedulers可以知道具体是哪一个应用发出的IO请求和精确地估计IO操作的开销。此外,它还可以,
Furthermore, memory notifications make schedulers aware of write work as soon as possible (not tens of seconds later when writeback occurs). Finally, split schedulers can prevent file systems from imposing orderings that are contrary to scheduling goals.
0x02 Split Framework Design
传统的IO请求从被发出,然后排队、批处理、然后被正式处理会经过OS的很多的layer,这样的很显然一个只在Block Layer的IO调度器会缺乏很多的优化的空间。 Split-Level I/O Scheduling最主要的就是要解决这个问题,这里使用的方法就是IO请求相关的信息可以通过scheduling hooks获取到,而无论这个操作发生在哪一个layer。这里就主要设计到3个问题:Cause Mapping、accurate cost estimation和reordering。
Cause Mapping
这个的主要功能就是追踪哪一个进程发出了IO请求,进而可以对这些信息进行统计。
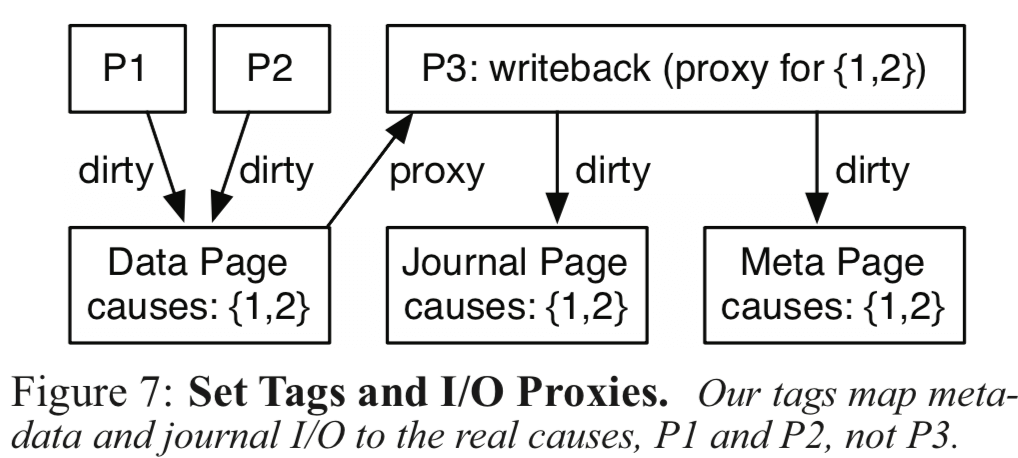
上面的图表示了一个例子,其中有两个问题:1. 一个数据page可以被多个进程处理,所以仅仅做一个tag是不够的,这里是一个tags的set,可以认为tag不是一个标量而是一个向量;2. 有些亲戚会被委托给另外的进程处理,这里将这样的进程叫做proxies(代理),这里的话要记录的tag就不应该是这个代理进程本书,而是看它这个操作是为哪一个进程服务的。
Processes P1 and P2 both dirty the same data page, so the page’s tag includes both processes in its set. Later, a writeback process, P3, writes the dirty buffer to disk. In doing so, P3 may need to dirty the journal and metadata, and will be marked as a proxy for {P1, P2}. Thus, P1 and P2 are considered responsible when P3 dirties other pages, and the tag of these pages will be marked as such. The tag of P3 is cleared when it finishes submitting the data page to the block level.
Cost Estimation
执行IO操作成本也是做出调度决策的一个重要因素,比如消耗存储设备的适合or其它的一些标准。这里统计的最好的地方是在靠近的硬件的地方。在Block层,写入的位置是已经知道了的。此外,不会因为实际读取的吃page cache而操作多估计,也不会因为没有统计到例如写入日志而造成少估计。不过这里存在的一个问题就是写入时候的page cache。由于写入的数据可以会被保存到buffer中一段比较长的时间,才会被flush。这样的话会对统计造成比较大的误差。将这个统计的操作放在更高的layer(memory level (write buffer))上面则可以避免这个问题,不过前面的在block layer统计的优点就会变成缺点。这里的做法是在两个地方都是添加了hooks,两个地方都可以被使用。其间的权衡有具体的调度器实现自己来做,
Our framework exposes hooks at both the memory and block levels, enabling each scheduler to handle the trade-off in the manner most suitable to its goals. Schedulers may even utilize hooks at both levels. For example, Split-Token promptly guesses write costs as soon as buffers are dirtied, but later revises that estimate when more information becomes available (e.g., when the dirty data is flushed to disk).
Reordering
对请求进行重排序是IO调度器实现更好性能的一个常用的手段,特别是在机械磁盘上面。 Split Framework在block 层开放了hooks用于实现读写请求的重新排序。这里存在的一个问题就是写请求的可重排序的能力会收到了文件系统特点的影响。所以这里的hooks也会暴露给文件系统,调度器可以通过控制写入的syscall的运行来控制写入操作对文件系统的可见性。Split Framework也会将对元数据的操作的hooks暴露出来,同样的,元数据操作的成本文件系统的内部实现很大的影响。此外,fsync之类的操作对调度的决择也有很大的影响,比如写入后面跟着一个fsync操作和仅仅是一个写入操作相比,前者的成本高很多,由此,这里也会暴露相关的hook.
0x03 Split Scheduling in Linux
Paper中将这个实现在了Linux上面,并和ext4和XFS集成。这里的主要做的就是下面这些:
-
Cross-Layer Tagging,Linux 的IO操作早不同的层涉及到不同的调用和不同的数据结构,这里在一个请求中添加了一个
causes标记,用于追踪这个请求。对于Writeback(比如ext4中的ext4_da_writepages,“da”代表 “delayed allocation”,是ext4中叫做延迟分配的一个功能) or 日志写入,它们都会写入一个文件的一个范围内的pages。这里对这些都需要额外处理,We modify this function so that as it does allocation for the pages, it sets the writeback thread’s proxy state as appropriate. For the journal proxy, we modify jbd2 (ext4’s journal) to keep track of all tasks responsible for adding changes to the current transaction. -
Scheduling Hooks,这里的hooks主要就是在前面说过的三个层面:
-
System Call,通过这里的hooks,调度器可以拦截一个写入请求,这里不对读取请求进行拦截。对于拦截的请求,调度器可以对于进程延迟处理。此外对于元数据的操作和同步的操作(creat and mkdir,fsync)都会暴露给调度器。而发出这个请求的发出者会被阻塞到这个syscall被调度。
-
Memory,这里的hooks暴露page-cache获取内部的信息,获取什么时候数据page被写“脏”了,什么时候这个page被删除了,
Schedulers can either rely on Linux to perform writeback and throttle write system calls to control how much dirty data accumulates before writeback, or they can take complete control of the writeback. -
Block,这里的hooks主要是获取请求被添加到block层的信息和请求被完成的信息。之前的Linux的实现上就存在了很多的hooks,比如请求合并等。这里也都支持。
-
-
Overhead, 这里讨论的就是这个framework给系统带来的开销,在Paper中的例子中,开销是很小的:
with the default Linux settings, average overhead is 14.5 MB (0.2% of total RAM); the maximum is 23.3 MB. Most tagging is on the write buffers; thus, a system tuned for more buffering should have higher tagging overheads. With a 50% dirty ratio [5], maximum usage is still only 52.2 MB (0.6% of total RAM).
0x04 Scheduler Case Studies
这里讲的是在这个framework上面实现Actually Fair Queuing,Deadline和Token Bucket具体的调度器的实现。这里只总结了一下Actually Fair Queuing调度器。
Actually Fair Queuing设计
使用两层的调度策略,读请求在block层处理(这里的handle应该值得是调度器如何对这个请求调度的处理),而写入请求(包括fsync之类)在syscall层面处理。这样可以使得读取在命中cache的时候同时避免写入受日志的影响,
This design allows reads to hit the cache while protecting writes from journal entanglement. Beneath the journal, low-priority blocks may be prerequisites for high-priority fsync calls, so writes at the block level are dispatched immediately.
到达block层的写入请求就被理解处理。一些测试结果,详细讨论参看[1],
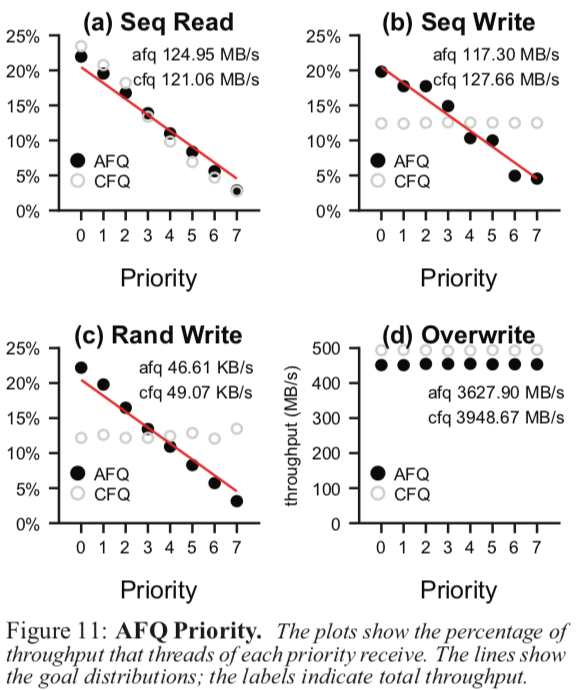
0x05 评估
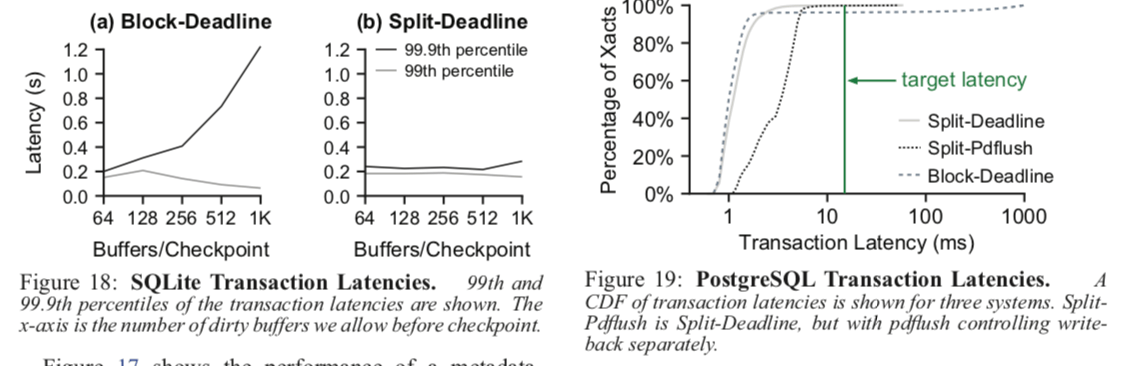
这里详细信息还是参看原论文[1],
参考
- Split-Level I/O Scheduling, SOSP’15.
