A Fast File System for Unix
0x00 引言
Unix FFS是针对HHD的经典文件系统设计,文章发表于1984了,距今已有34年了(比我年龄大上好多)。这篇论文在大三的时候就看过了。FFS的论文里面的思想影响到了现在很多文件系统的设计。
0x01 原有解决方案存在的问题
经典的Unix文件系统布局:
Super Block
+------+---------+---------------------------+
| | | |
| | | Data |
| | inodes | |
+------+---------+---------------------------+
原有系统的问题就是糟糕的性能表现,大概只能发挥出磁盘2%的带宽,低到可怕。性能低的一个最主要的原因就是远文件系统的设计是把此篇当作是一个随机访问的内存,只不过这个不支持byte-addressable而已,只能按块来访问。系统运行一段时间后碎片导致了文件块发布在此篇的各个地方,操作文件造成了大量的seek操作,严重降低了性能。所以FFS的核心就是[2]:
How can we organize file system data structures so as to improve per- formance? What types of allocation policies do we need on top of those data structures? How do we make the file system “disk aware”?
0x02 基本思路
问了保持兼容性,针对文件系统的API没有变化,变化的只是内部的实现。
关键思路 01: The Cylinder Group
FFS第一个思路就是将磁盘的空间分组,主要是安照块在磁盘上的位置,它们有着到磁片中心相同的距离。
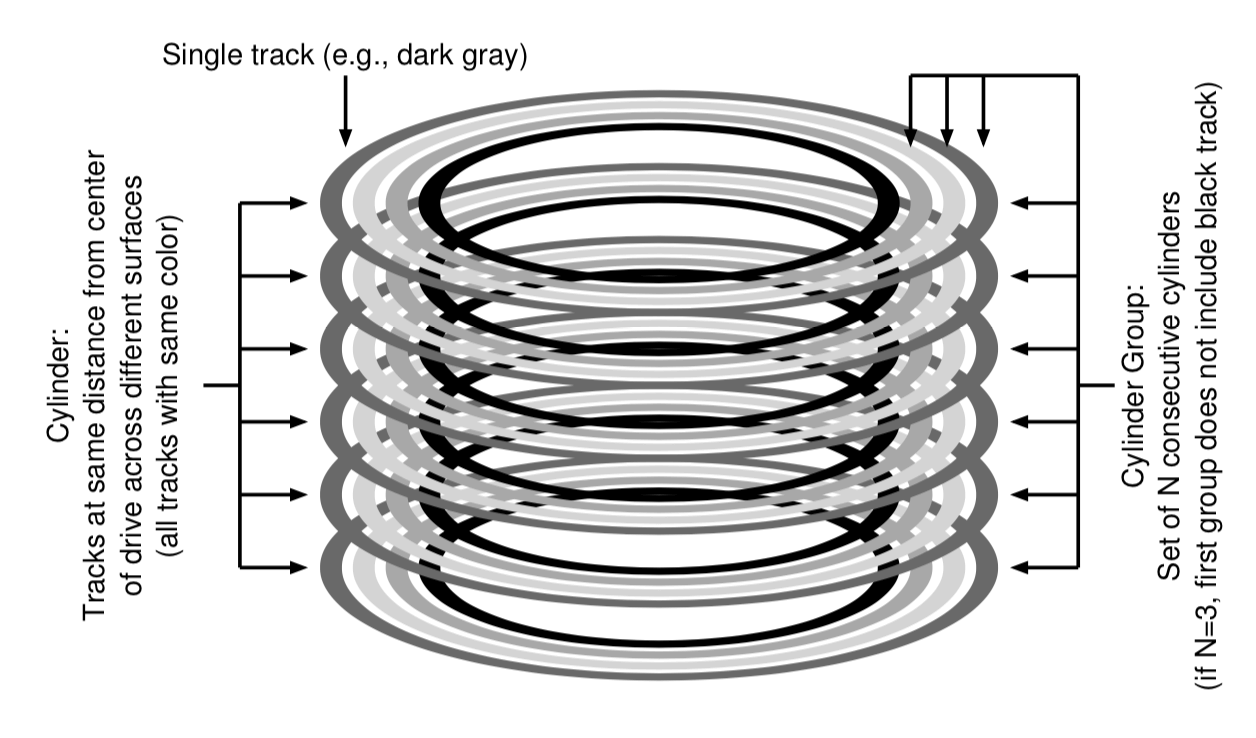
[2]中的这一幅图很好的表达了这种思想。值得注意的是现在的磁盘已经获取不到相关的物理信息了,所以现在的一些FS使用的方法是将磁盘分为block group,每一个group是在磁盘上是连续的。
+--------------------+-------------------+----------------------+
| | | |
| Group 0 | Group 1 | Group 2 |
| | | |
+--------------------+-------------------+----------------------+
磁盘的结构也做了一些变化:
Super Block
+-------+---------+------------+--------------------------------+
| | | | |
| | | inodes | data |
| | | | |
+-------+---------+------------+--------------------------------+
inode bitmap
data bitmap
Super Block包含了文件系统的基本元数据信息,inode bitmap, data bitmap用于指示后面的indoes,data哪些部分被使用了。后面的两个部分用途和之前系统的一样(这里bitmap,inodes是预先就分配好的,在1984年的时候磁盘比较小,分配死的没有什么问题,后来的磁盘越来越多,现在的很多文件系统针对这个方面有了很多的优化)。这里的要按照cylinder group来方便分配。
基本操作
让我们来想想在这个FS中创建一个文件并写入少量数据,它会进行哪些操作呢?
- 分配一个新的inode;
- 在inode bitmap中表示这个inode被分配了;
- 分配一个数据块(假如一个就可以了),这样的话需要写data部分;
- 在data bitmap中标示对应的数据块被分配;
- 这还没有完,文件系统是存在目录结构的,所以对应的目录的元数据也要修改;
关键思路 02: 把相关的东西放一起
使用了几种方式把相关的东西放在一起(要考虑到HHD的特点)
- 对于目录: 查找有最少数量的目录和最多空闲inodes的cylinder,将目录的inode和数据放在这里。
- 对于文件: 保证inode和数据块在一个group内,将同一个目录下面的文件放在一个group内。
The FFS policy heuristics are not based on extensive studies of filesystem traffic or anything particularly nuanced; rather, they are based on good old-fashioned common sense (isn’t that what CS stands for after all?)1. Files in a directory are often accessed together: imagine compiling a bunch of files and then linking them into a single executable. Be- cause such namespace-based locality exists, FFS will often improve performance, making sure that seeks between related files are nice and short.
关键思路 03: 处理大文件
由于大文件会占据一大块的空间,访问后面的文件时会造成比较昂贵的seek操作。FFS会将文件的前面几个block放到文件所在的group,而将后面的数据分成比较大的chunk,保存在其它的group中。虽然这里可能造成一些额外的seek操作,但是由于文件比较大,会被数据的传输时间”掩盖”.
Specifically, if the chunk size is large enough, the file system will spend most of its time transferring data from disk and just a (relatively) little time seeking between chunks of the block. This process of reducing an overhead by doing more work per overhead paid is called amortization and is a common technique in computer systems.
关键思路 04: Block 和 sub-blocks
FFS将block的大小增大为4k,减小了overhead,提高了性能。更加大的block也使得前面的bitmap结构更加小。带来的缺点就是可能更加多的内部碎片,因为一般情况下小文件总是占了大部分。FFS这里使用的解决方法是将一个block又可以在内部分为4个sub-blocks。好处就是文件都很小的时候能更充分利用空间,减少碎片,缺点就是处理这个使得系统的复杂程度增加了不少,有时候还会造成额外的数据移动。
0x03 Summary
Certainly all modern systems account for the main lesson of FFS: treat the disk like it’s a disk.
参考
- A Fast File System for Unix, TOCS 1984.
- “Operating Systems: Three Easy Pieces“ (Chapter: Locality and The Fast File System) by Remzi Arpaci-Dusseau and Andrea Arpaci-Dusseau. Arpaci-Dusseau Books, 2014.
