CORFU: A Shared Log Design for Flash Clusters
0x00 引言
Shared Log是一些分布式系统的一种的实现思路。CORFU是一个 Shared Log的实现,它主要是面向SSD设计。CORFU可以被视为一个分布式的SSD,同时提供普通的SSD不能支持的功能,包括容错、可拓展性和垮地理区域复制等。
A single CORFU instance can support up to 200K appends/sec, while reads scale linearly with cluster size. Importantly, CORFU is designed to work directly over network-attached flash devices, slashing cost, power consumption and latency by eliminating storage servers.
0x01 基本设计
CORFU提供的API是很简单的。顾名思义,log的方式就是只添加的写入,然后可以选择读取log的某个部分的数据,
append(b) Append an entry b and return the log position l it occupies
read(l) Return entry at log position l
trim(l) Indicate that no valid data exists at log position l
fill(l) Fill log position l with junk
CORFU只提供很简单的接口,而具体的用CORFU实现的应用是由客户端来实现的。所以CORFU的设计是以客户端为中心的。在这些基本的接口之上,客户端可以用其实现KVS、复制状态机或者是分布式数据结构[2]等。
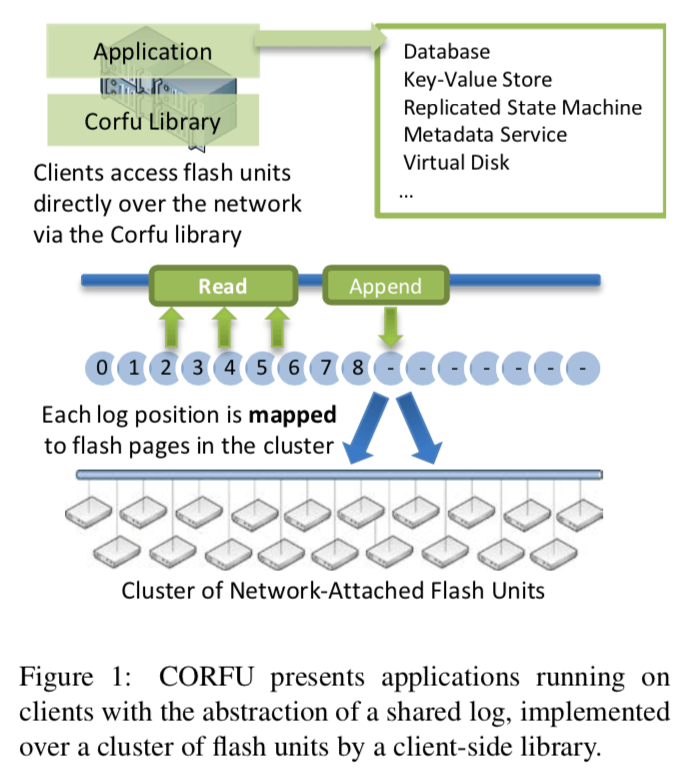
CORFU的主要作用是在这些SSD集群上面实现一个shared log的抽象。对于每一个log,都有它的地址空间。它主要要做下面的三件事情:
- mapping function,负责将一个逻辑位置映射到集群中一个SSD的具体的一个page;
- tail-finding mechanism,用于发现这个log的末尾,以便于写入新的数据;
- replication protocol,复制log数据;
基本使用方法就是,
To read data at a specific log position, the client-side library uses the mapping function to find the appropriate flash page, and then directly issues a read to the device where the flash page is located. To append data, a client finds the tail position of the log, maps it to a set of flash pages, and then initiates the replication protocol that issues writes to the appropriate devices.

0x02 Mapping in CORFU
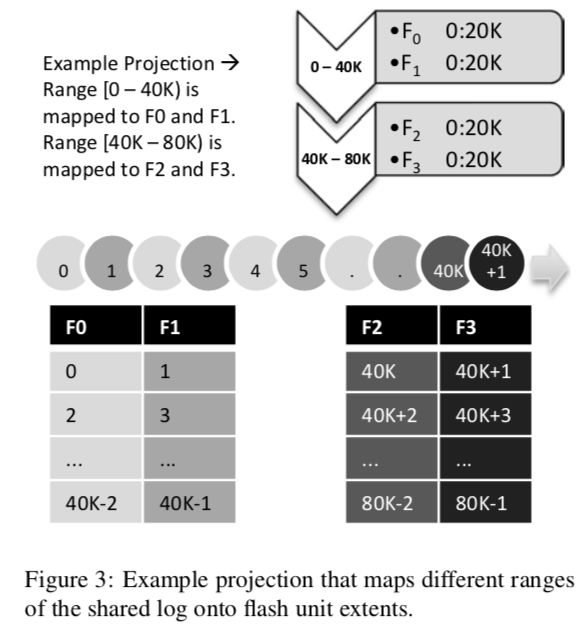
CORFU是一个比较简单的机制。首先,在CORFU中,log的地址空间会被分成连续的一系列的range,这些range会被映射到一个具体的flash(flash based ssd)单元。每一个CORFU的客户端都维持一个数据结构来保存这些映射关系,这个在CORFU中被称为投影(projection)。如下面的图所示,[0, 40K )被映射到flash单元F0和F1,而[40K, 80K)被映射到F2和F3。对于log中具体的一个range来说,它的位置被映射到一个flash单元的一个page使用的是一个简单的、确定的方式。默认使用的是RR的方法,比如log的position 0被映射到F0 :0,而position1被映射到F1 :0,然后position被映射到 F0 : 1。这里的位置就可以是一个page。而在实际的实现中,log的数据都是存在副本的,而在一个position在这些副本上面的位置都是相同的,
The example above maps each log position to a single flash page; for replication, each extent is associated with a replica set of flash units rather than just one unit. For example, for two-way replication the extent F0 : 0 : 20K would be replaced by F0/F0′ : 0 : 20K andtheextentF1 : 0 : 20K would be replaced by F1/F1 : 0 : 20K.
下面的图的下半不是就表现了log的是如何保存在这几个flash单元上面。这样的映射方式客户端可以很容易的计算处理要读取数据的位置。CORFU只会对最后的一个range进行写入操作,这个range被称为active range。
Changing the mapping
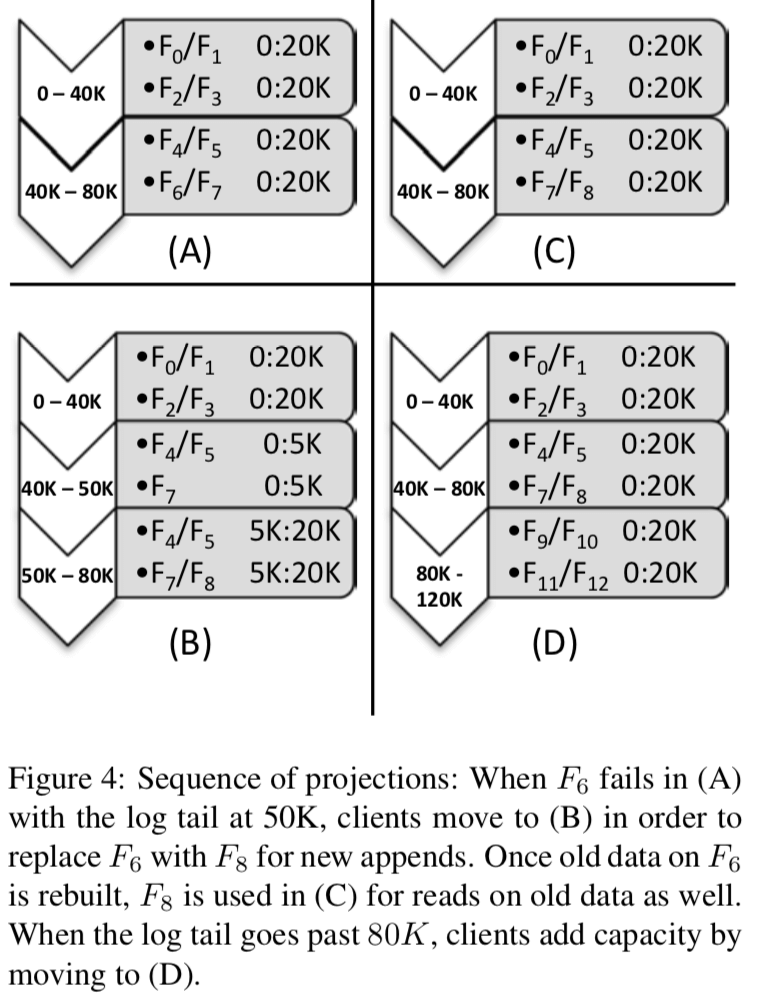
log的range和flash单元之间的映射关系在一些情况下是会改变的,最明显的例子就是某个flash单元出现故障无法被使用的时候。为了实现重新映射,CORFU采用了一个在分布式系统中常用的机制:epoch。客户端的每一个操作都必须带上这个epoch的信息,如何epoch变化了,这些“旧”的过时的操作就无法执行。一个新的epoch代表了一个新的投影,而一个新的投影必须完整地反映了这个epoch之前的操作,在epoch改变的时候的“in-fight”的操作都不能被执行后者是在新的投影下重试。CORFU使用了基于辅助(auxiliary)的reconfiguration protocol。 辅助是投影(projections)的序列(sequence),被持久化保存。一个投影在这个序列中的位置等于它的epoch,这里就可以理解为这些抽象意义上面的投影(随着事件不断添加了新的)组成的一个序列。这里就可以理解为是这个projection的multi-version的机制。
Clients can read the ith entry in the auxiliary (getting an error if no such entry exists), or write the ith entry (getting an error if an entry already exists at that position). The auxiliary can be implemented in multiple ways: on a conventional disk volume, as a Paxos state machine, or even as a CORFU instance with a static, never-changing projection.
这个reconfiguration操作分为两步:
- Sealing the current projection,一个客户端准备创建一个新的projections的时候,它需要向一部分的flash单元发送seal的命令,这些flash单元是那些包含了一个page在前一个projection中,而不在后一个之中的。这个seal操作是为了避免其它的客户端在对这部分的数据进行操作,包括读和写。
- Writing the new projection at the auxiliary,当前面的seal操作成功之后,这个客户端回尝试写入新的projection。如何这个时候发现这个位置的projection已经被写入了,那么它只能abort它的操作,然后读取被其它客户端写入的新到的projection。
下面的图表明了一个该表projection的过程:
0x03 Finding the tail in CORFU
发现log的尾部是log写入的必须操作。这里最简单的方式就是客户端以自己目前知道的tail的位置写入(初始化的时候就是0)。当然这个tail的位置可以已经被更新,这个时候这个客户端的写入操作就会发生错误,这个时候客户端就得更新它的tail的信息在重新进行写入操作。这种方式优点项乐观并发控制的方法。这样的缺点就是比较低的性能。为了解决这个问题,CORFU使用的方式是使用一个专用(dedicated)的sequencer做为一个写入的位置的token。这个sequencer可以理解为一个网络的计数器。客户端准备写入数据的时候,它首先得请求这个sequencer,sequencer返回它当前的值,然后自增。客户端获取的这个值就相当于一个预留的写入的位置,这些写入操作的时候就不会有不同的客户端竞争写入的问题了。很显然,这样的方式会带来额外的两个问题:
- sequencer可用性的问题,这个在CORFU不是很重要,因为这个sequencer在CORFU不是必须的组件,它只是一个优化的方法。CORFU使用它的reconfiguration机制来指明当前的sequencer,也方便在一个sequencer故障的时候快速恢复。初始化这个sequencer值的方法就是读取现在这个log写入位置的信息即可;
- 空洞的问题,这个问题比前一个问题复杂一些。一个客户端获取来一个预留的写入位置之后,有可能它在实际写入数据的时候就crash了。这些空洞的存在可以会导致一些应用的错误结构。这里使用的方法是当其它的客户端发现了这些的空洞之后,就标记这个位置为垃圾,这里只要对元数据进行修改即可。很不幸,这样会导致另外的一个问题,就是预留这个位置的客户端可能不是真正的crash了,这个时候就可能方式不同的客户端写入冲突,一个客户端准备将这个位置标记为垃圾,另外一个准备写入数据,所以这个的sequencer并没有完全地写入冲突。CORFU必须能够处理这种情况。
0x04 Replication in CORFU
复制这里CORFU使用的是现成的解决方案:Chain Replication,这个可以参考论文[3]。这里就不说了。在这种chain的复制方式中,要满足下面的几个条件,
Further, we impose two conditions on the transition: if the old chain had a prefix of non-zero length, the new chain must have one as well with the same value. If the old chain had a zero-length suffix, the new chain must have one too. Lastly, to prevent split-brain scenarios, we require that at least one flash unit in the old replica set be sealed in the old projection’s epoch.
Paper中描述的实现这些要求的方式是首先创建一个没有失败节点的chain。然后使用复制数据的方式创建副本。当新的副本准备好的时候,系统重新配置将其添加到副本chain的末尾。
0x05 Garbage Collection & Flash Unit Implementations
CORFU提供了trim的API来删除数据,随着数据的不断删除,log的地址空间回变得越来越稀疏。为了支持稀疏的地址空间,除了前面说的projection的映射方式之外,在flash的单元中,保持了一个extents到若干的物理page的映射。这个extent是64bit的地址空间中的一部分。Flash单元要求满足下面的三个要求:
- write-once semantics,这里也需要用到实现地址映射的hash map,对应的地址存在这个hash map之中的是就代表已经有被写入了。
- seal capability,这个的实现比较简单,就是使用的epoch的方式。对于小于cur-sealed-epoch的操作都拒绝。当一个创建新的epoch操作被接受的时候,这个flash操作完成正在进行的操作之后更新cur-sealed-epoch这个值。然后返回cur highest offset的值,这样也就透露出了地址空间中已经被写入的最高的地址。
- infinite address space,这里的实现方式就是flash单元用hash map实现的一个映射的关系;
0x06 应用和评估
Paper中以CORFU实现一个key-value和一个State Machine Replication为例。具体的信息可以参考[1].
参考
- Balakrishnan, M., Malkhi, D., Davis, J. D., Prabhakaran, V., Wei, M., and Wobber, T. 2013. CORFU: A distributed shared log. ACM Trans. Comput. Syst. 31, 4, Article 10 (December 2013), 24 pages. DOI: http://dx.doi.org/10.1145/2535930.
- Tango: Distributed Data Structures over a Shared Log, SOSP’13.
- Chain Replication for Supporting High Throughput and Availability, OSDI 2004.
