FlashShare: Punching Through Server Storage Stack from Kernel to Firmware for Ultra-Low Latency SSDs
0x00 引言
这篇Paper将的时如何从内核到固件为现在的Ultra-Low-Latency (ULL) SSD进行优化,这是最近的第好几篇关于这个方面的文章了。这个优化感觉和数据中心内一些为网络优化的类似,也是针对不同的应用区分不同要求的请求,在这篇Paper中特别注意的是延迟敏感性的请求。在固件层面对NVMe的控制权和缓存进行了改进,使用动态的DRAM分区满足不同应用的要求。Paper中几个重要的内容总结如下:
- Kernel-level enhancement,目前,Linux对于这类高性能的SSD使用的block layer是 multi- queue block layer (blk-mq),blk-mq也为SSD之类的硬件做了很多的优化,但是它没有考虑到IO请求的优先级。FlashShare先对kernel进行改进,将这类IO请求(延时敏感类型)可以绕开现在内核一些处理机制,直接达到NVMe的驱动层。
- Firmware-level design,为了能让SSD的固件也能意识到这些延迟敏感类型的请求,FlashShare重新设计了固件的调度和缓存。FlashShare将SSD内置的Cache根据workload的特点进行分别分配Cache,还可以动态调整这些分区。
- New interrupt services for ULL SSDs,FlashShare认为现在的基于中断的方式(message-signaled interrupts)会有存储栈带来的很长的延时的问题,使用轮询的方式会消耗大量的CPU。FlashShare则使用折中的设计,使用了一种叫做selective interrupt service routine (Select-ISR)的方式,就是对在线交互类的应用使用轮询的方式,对线下应用使用中断的方式。
通过使用这些方式它实现了一下的效果:
We also revise the memory controller and I/O bridge model of the framework, and validate the simulator with a real 800GB Z-SSD prototype. The evaluation results show that FLASHSHARE can reduce the latency of I/O stack and the number of system context switch by 73% and 42%, respectively, while improving SSD internal cache hit rate by 37% in the co-located workload execution. These in turn shorten the average and 99th percentile request turnaround response times of the servers co-running multiple applications (from an end-user viewpoint) by 22% and 31%, respectively.
0x01 背景知识
这里的背景知识和Paper内容是强相关的而且内容比较多,所以了解这里相关的一些知识。
内核存储栈
下面是现在的Linux的Storage Stack的Overview。这里使用的blk-mq,这里之前有一篇总结专门讲了这个。
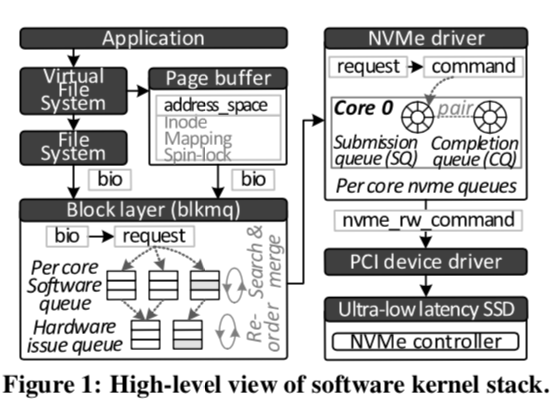
一个IO请求要到达NVMe 去佛那个由两条路径,区别只有Page Buffer这里。在NVMe的驱动中,会有多个的NVMe Queque。这其中连个队列比较核心,一个就是 submission queue (SQ),另外一个就是completion queue (CQ)。与其它一般的存储栈不同,这里NVMe的SSD可以直接从主机的内存里面拉取数据和命令。当一个IO请求完成的时候,SSD发送一个 message signaled interrupt (MSI)直接写入每一个core的可编程中断控制器的中断向量,
When the I/O request is completed by the SSD, it sends a message signaled interrupt (MSI) that directly writes the interrupt vector of each core’s programmable interrupt controller. The interrupted core executes an ISR associated with the vector’s interrupt request (IRQ). Subsequently, the NVMe driver cleans up the corresponding entry of the target SQ/CQ and returns the completion results to its upper layers, such as blk-mq and filesystem.
设备固件栈
SSD的内部其实就是一个特殊的小型计算机系统,其中一个重要的部分就是NVMe Controller,它控制下吗的内置的Cache和FTL。内核的Cache其实就是DRAM,高端的SSD会有数GB的Cache。NVMe Controller即可用接收主机推送的请求,也可以直接自己去拉取。
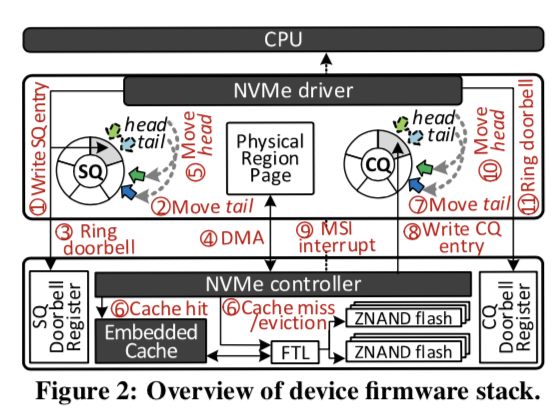
这里来描述一下一个请求到NVMe驱动然后执行完成的过程比较复杂,Paper中有具体的描述。与这里相关的一个就是SQ和CQ。这两个队列本质是就是一个生产者消费者的队列。SQ的生产者时主机,任务通过写入到SQ的tail,SSD这里就是消费者,从head中读取请求。CQ中的内容就是请求完成的学习,生产者和消费者相反。SSD中的Doorbell Register也与这里的过程直接相关,可以参看相关资料。
0x02 Kernel Layer Enhancement
FlashShare认为之间让kernel去识别IO请求的延迟敏感性是很难的,所以FlashShare这里直接吧这个工作交给了应用程序,它在添加了两个Linux的系统调用,在Linux进程的PCB struct task_struct中添加了相关的属性值来标示。
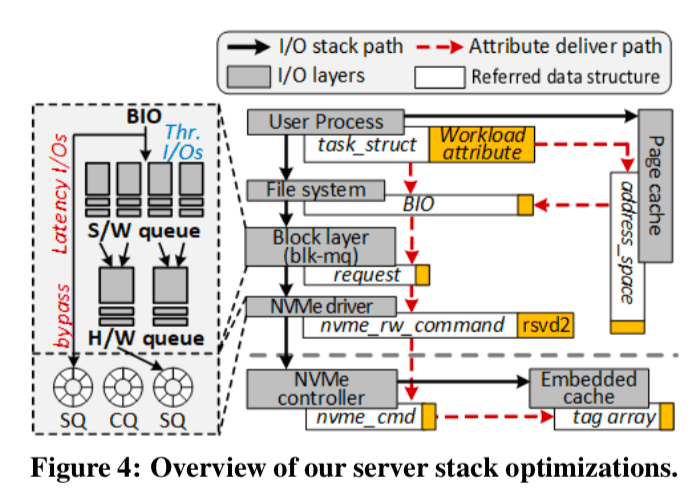
上面的图中很清晰的标示了这个属性值的传递过程。这里也就同时显示出一般的请求经历的过程和改进之后的之间就bypass了这些层,直接达到了驱动。在使用FlashShare添加的chworkload_attr设置了相关的熟悉之后,当一个使用了O DIRECT参数的IO请求达到kernel的时候,FS先从struct task_struct中取到相关的属性值放到bio结构中,其它情况会考虑到文件缓存,这里就会将struct task_struct复制到address_space结构中,这样就可以将这个属性值一种传递下去,以便于使用这个属性值。
在kernel层面的优化主要集中在两个地方:
-
blk-mq,一般情况下,kernel的block layer都会尝试对IO请求进行合并和重排序大的操作,这个在超低延时的SSD or NVM有时候是不适合的,这个会增加IO请求的延时(Linux这里一般的默认的行为就是一个IO请求不会被马上执行,而是会稍微等待一段时间,增加合并请求批量处理的机会,可以提高效率)。这里FlashShare的处理方式就是bypass了上面图4中的多个的服务层,直接达到NVMe驱动。
这里这样简单的bypass的方式但来的问题就是可能导致冒险(hazard),一个例子就是一个非敏感性的IO请求正在blk-mq中处理中,这个时候一个延时敏感性的IO请求到来了,它们会对同一个逻辑块进行操作。对于这样的情况就不能简单地bypass了。这里要处理一下,如何这两个请求是不同的操作类型(读写),blk-mq就一前一后地提交这两个请求,如果是相同的类型的,就将其合并处理然后转发到NVMe的驱动。
-
NVMe driver,这里要解决的一个问题是由于NVMe对的head/tail是由NVMe的驱动和NVMe控制器共同处理的。这里即使通过改动blk-mq使得这些延时敏感的IO请求先于其它请求到达了SQ,但是NVMe控制器并不会去提前处理这些请求。这里的解决方式就是使用两个SQ,不同类型的IO请求放到不同的SQ中,避免了相互的影响。在图4中就表示出了添加的bypass的SQ。同时为了避免产生饥饿的问题,这里如果原来的SQ上面的IO请求达到一定的阈值的之后or等待了一定的时间之后,FlashShare就会去处理这个SQ上面的请求。
0x03 Selective Interrupt Service Routine
Select-ISR使用来处理前面提到的中断和轮询存在的问题的,
With Select-ISR, the CPU core can be released from the NVMe driver through a context switch (CS), if the request came from offline applications. Otherwise, blk-mq invokes to the polling mechanism, blk poll(), after recording the tag of the I/O service along with online applications. blk poll() continues to invoke nvme poll(), which checks whether a valid completion entry exists in the target NVMe CQ. If it is, blk-mq disables IRQ of such CQ so that MSI cannot hook the procedures of blk-mq later again. nvme poll() then looks up the CQ for a new entry by checking the CQ’s phase tags.
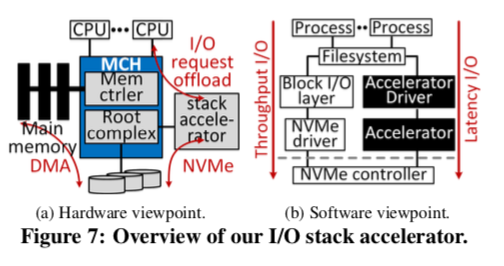
即使这样,还是存在轮询消耗大量CPU的问题,主要的原因是查找SQ/CQ里面的tag以及合并每一个IO Service的请求,在这种ULL SSD的情况下,这部分的消耗被放大。这里采用的解决办法是使用了I/O-stack accelerator:
we propose an I/O-stack accelerator. Figure 7 shows how our I/O-stack accelerator is organized from the hardware and software viewpoints. This additional enhancement migrates the management of the software and hardware queues from blk-mq to an accelerator attached to a PCIe. This allows a bio generated by the upper file system to be directly converted into a nvm rw command. Especially, the accelerator searches a queue entry with a specific tag index and merges bio requests on behalf of a CPU core.
这样从旁边开一个accelerator减少了一半的tag查找和合并bio的请求的消耗。这里具体时如何实现的是Paper中4.2节的内容。
0x04 Firmware-Level Enhancement
前面提到了通过在NVMe控制器中使用2两个SQ并优先处理延时敏感SQ的请求解决了一部分的不同类型之间请求感人的问题。不过在固件层面,这个允许还是存在,前面的背景知识里面说了SSD中是存在DRAM的Cache的,在一些高端的SSD上面这个Cache的大小能达到GB的级别,同样地,这些Cache的使用也会产生相互的影响,
In addition, the I/O patterns and locality of online applications are typically different from those of offline applications. That is, a single generic cache access policy cannot efficiently manage I/O requests from both online and offline applications.
同样地,这里也使用的是分开处理的方式。FlashShare将这些Cache分为两部分,各个部分由相同的缓存项的数量(这里个人猜测由相同的项数时为了方便处理),但是由不同的关联度(可以类比CPU Cache的组相联)。固定的划分时很难使用不同的使用情况的,所以这里FlashShare使用了动态的处理方式。在这一个epoch内,FlashShare会统计不同类型IO请求的数量,根据这些请求的变化来动态调整。此外,FlashShare为了处理不佳的数据预取导致的污染Cache的问题,这里使用了一种叫做“ghost caching” 的机制,它会评估不同的预取配置的“好坏”。这些“ghost caching”只是一个Cache的标示,并不实际上预取数据。每一个epoch内,FlashShare会计算出那一个方式是最好的,就使用这种预取的配置。
0x05 评估
一些基本的性能数据。
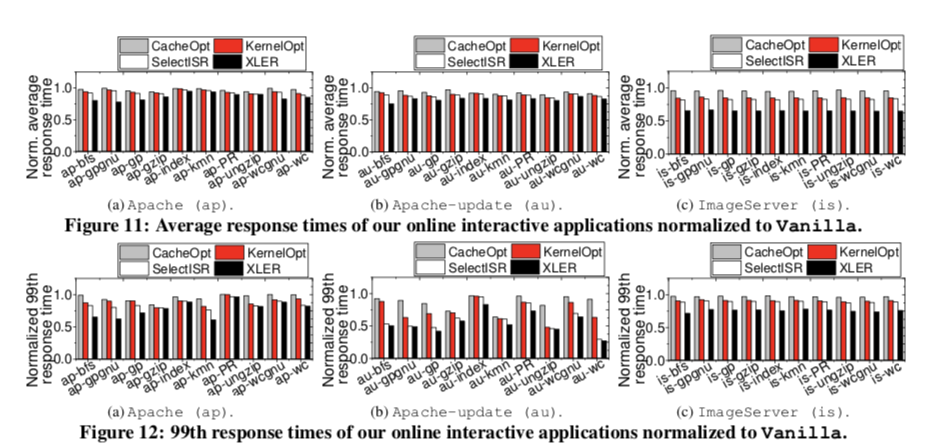
更加详细的分析可以参看原论文。
参考
- Flashshare: Punching Through Server Storage Stack from Kernel to Firmware for Ultra-Low Latency SSDs, OSDI 2018.
