Remote Core Locking and ffwd
0x00 引言
这篇总结包含了2篇Paper的内容,一篇是ATC‘12上面的Remote Core Locking,一篇是SOSP 2017上面的ffwd。两者将的都是利用另外的核心来执行临界区代码的一个并发控制的思路。对于一段程序,多核真的能加快运行速度?答案显然是不一定的。对于那种能够存在多个同时操作的结构,比如B-tree,很多时候是能起到加速的效果。但对于临界区多个线程就只能顺序的执行,实际上在这段临界区的代码中就运行多线程就可能比单核还慢,特别是核心数很多 or NUMA架构的情况下,前者是因为维持缓存一致性带来的巨大的开销,后者一般是访问远端的内存的高成本(大概就是这个意思了)。这个时候还不如直接使用单核了。Remote Core Locking 和 ffwd 就是这样一种访问临界区的方式,基本思想都是将这段访问的任务都交个另外一个核心来运行,也就是一种代理的方式。基本的思路:
- 减少原子指令的使用,降低cache miss率;
- 在另外的一个指定的核心上执行临界区代码;
- 快速的控制转移,没有同步也没有全局变量;
- 共享的数据保持在server核心上(即用来执行临界区的代码的核心),这意味着更加少的cache miss。
0x01 Remote Core Locking(RCL)
RCL的基本原理:
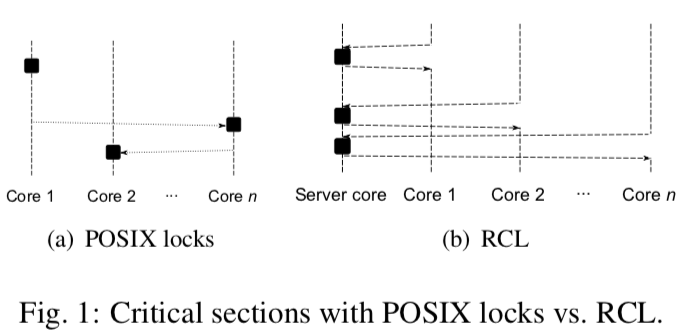
在RCL中,执行临界区的代码编程了一种远程方法调用。为了实现这个“RPC”调用,客户端和服务段使用一个请求结构的数组来进行交互。这个数组一共有C项,这个C代表了能够请求服务的客户端的数量。一般而言都要大于CPU 核心的数量。这个数组每一项的长度为L bytes,这个L一般是CPU缓存行的大小。第i项记为req-i,代表了一个client-i和服务端和交互的结构。
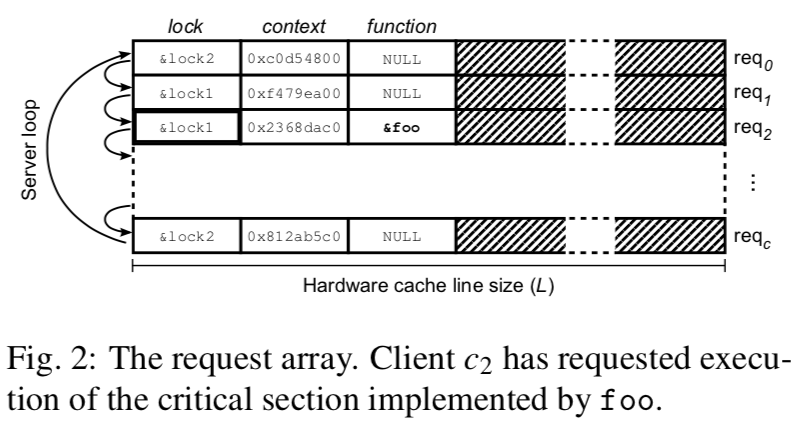
req-i包含了以下的几个字段:
- 这个临界区相关的lock的地址;
- 一个context结构的地址,包含了一些会由临界区引用or更新的一些变量之类的东西;
- 包含了临界区代码的函数的地址,如果没有临界区,这个字段就是NULL;
操作过程
- 客户端: 依次写入lock的地址、context 结构的地址、要执行函数的地址到req-i的第1、2、3个部分,然后等待第3个部分被服务方设置为NULL,代表了服务方已经将请求完成,这里可以使用SSE3 的
monitor/mwait指令优化。 - 服务端:轮询这些request结构的数组,当发现req-i的第3个字段不为NULL的时候,先检查lock是否是空闲的,如果是,则获取lock,然后执行函数,执行完成之后,设置第3个字段为NULL,重复以上的过程。
关于算法的详细伪代码和评估数据可以参看论文[1].
For the applications that spend 20-70% of their time in critical sections when using POSIX locks (Raytrace/Balls4, String Match, and Memcached/Set), RCL gives significantly better performance than POSIX locks, but in most cases it gives about the same performance as MCS and Flat Combining, as predicted by our microbenchmark. For Memcached/Set, however, which spends only 54% of the time in critical sections when using POSIX locks, RCL gives a large improvement over all other approaches, because it sig- nificantly improves cache locality. When using POSIX locks, Memcached/Set critical sections have on average 32.7 cache misses, which roughly correspond to accesses to 30 shared cache lines, plus the cache misses incurred for the management of POSIX locks. Using RCL, the 30 shared cache lines remain in the server cache.
0x02 ffwd
ffwd的基本原理和RCL是一样的,不过它实现了更加好的性能:
Our system: fast, fly-weight delegation (ffwd, pronounced “fast-forward”), is a stripped-down implementation of delegation that is highly optimized for low latency and high throughput. ffwd offers up to 10× the throughput of the state-of-the-art in delegation, RCL [53], in microbenchmarks, or up to 100% in application-level benchmarks. With respect to locking and other methods, ffwd is often able to improve performance by 10× or more, for data structures suitable to delegation.
ffwd实现这样的性能的主要方式就是有效的隐藏在服务线程和客户现场之间互联产生的延时。方法综合了指令级的并行和小心地安排内存访问。ffwd中避免了原子指令的使用,允许服务线程重排序指令,此外还有将请求和响应打包到接近客户端的cache line pairs中,缓冲响应以减少维持缓存一致性带来的数据流量。
The primary contributions of this paper are as follows:
• The design and implementation of ffwd, to our knowledge the fastest delegation system to date. At approximately 40 cycles of server-side overhead per request, ffwd-delegated data structures closely approximate single-thread performance, in a multi-threaded setting.
• A low-level analysis of the performance bounds on locking vs. delegation, from an architectural perspective, setting the stage for further improvements.
• A publicly available implementation of ffwd, including a general purpose API, and a set of benchmark programs ported to delegation, for the community to reproduce and build upon our results.
ffwd提高的API也很简单:
FFWD Server Init()
Starts a server thread, allocates and initializes the request and response lines.
FFWD Delegate(s, f, retvar, argc, args...)
This macro delegates function f to server s, with specified arguments. Stores return value in retvar.
Lock and Delegation Performance Bounds
ffwd之类的基于委托的同步方式都特别适合临界区比较小的情况。这里先分析一下影响这些同步方式性能的主要因素。先来考虑一个理想的情况,对于一个one-way 互联延时为L的,临界区执行时间为C-lock的情况,理想的吞吐为T-lock = 1 / (l + C-lock),这是如何如优化的一个指导。
Consider an idealized system. Assuming no back-to-back acquisitions, the maximum single-lock throughput is T-lock = 1 / (l + C-lock), where l is the mean one-way interconnect latency, and C-C-lock is the mean duration of the critical section. When (C-lock → 0), lock throughput is dominated by bus latency.
Interconnect Bandwidth & Interconnect Latency
在Paper中测试的系统中,Interconnect Bandwidth一般为150 - 390 million缓存行每秒,由于在ffwd使用了2个缓存行,这里去最小的值的话就是75Mops,又系统上面有2条这样的通道,所以就是150Mops。委托失的执行方式需要一个请求一个响应,使用这里最大的吞吐就是1 / 2*L,着Paper中的系统上面大概就是2.5Mops。
Interconnect Parallelism: Store Buffers
经过上面的分析就可以发现,互联的延时是影响性能的主要因素。所以这里想办法优化这里。使用的方法就是同时使用多个请求响应来隐藏延时,这里使用了store buffer。在Broadwell CPU上面,cache-coherent stores最多支持42个执行中的stores,假设一个对应一个的话,就是42 * 2.5 = 105 Mops。
Demarshalling Overhead
这里还有由Demarshalling带来的开销。假设服务方执行临界区代码的时间是C-del,Demarshalling的开销是O-del,这样得到最大的吞吐就是 1/ (C-del + O-del)。
It is unknown how efficient a delegation server can be. However, our current implementation achieves 55 Mops on a 2.2 GHz CPU, or 40 cycles per request, whereas locking requires more than 450 cycles per request.
In summary, with locking, throughput is limited to 5 Mops per lock, or 12.5 Mops when running on a single socket. With delegation, performance is limited primarily by server processing capacity, and the number of processor cycles spent on each delegated function.
fast, fly-weight delegation (ffwd)
基本工作方式示意图:
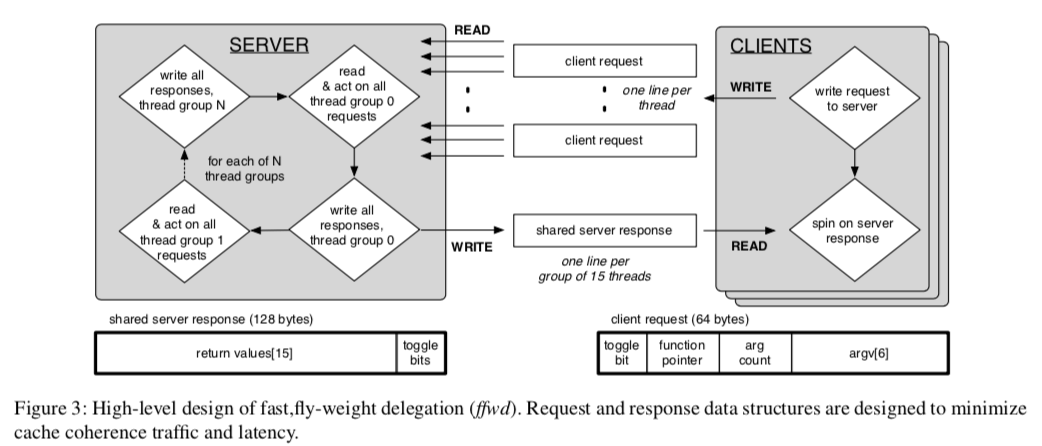
ffwd中每一个客户端都有一个128byte的的请求cache line pair,这个pair只能被运行在特定一个硬件线程上面运行的线程使用,只能被服务端读取。当一个客户端线程写入请求cache line pair之后,它就在特定的响应cache line pair上面子旋转。这个响应cache line pair能读和写的对象和请求的相反。服务方也像RCL一样轮询请求,不过它一次性处理一组之后在写回结果。每个请求结构与前面的RCL有所区别,有一个toggle bit,一个函数指针,一个参数数量值和最多6个参数组成。在一个socket上面(CPU的socket),响应行最多由15个线程共享,也包含了一个toggle bit,8byte的返回值。toggle bit指示了每个单独请求/响应通道的状态。如果与给定客户端对应的请求和响应toggle bit不同, 则新请求处于挂起状态。如果它们相等, 则服务方已经处理完成,响应已准备就绪。服务方处理请求, 就是加载提供给相应的参数, 并调用指定的函数。
ffwd的优化策略
-
Eliminating false sharing,与一般的只是设置为64byte大小不同,ffwd这里的去除伪共享还考虑到了缓存预取,所以将大小设置为128byte,
On Intel’s Xeon family of architectures, cache lines are 64 bytes, but the L2 cache of each core includes a spatial (pair) prefetcher, which treats memory as consisting of 128-byte line-pairs, and automatically prefetches the “other” 64-byte line when one of the lines is otherwise retrieved. -
Independent, per-core request lines,没什么特别的。
-
Buffered, shared response lines,这里与RCL的差别比较大, 这里ffwd是分配128-bytes response line pairs, 最多由15个在同一个socket上面的硬件线程共享, 其中包含切换位和8字节返回值。服务方的写入操作使得response line pairs对相应的socket上的所有副本失效。但是此失效过程中, 服务方的响应写入到本地核心的存储缓冲区, 实际上保证整个128bytes可以写入,这样就不会导致维持缓存一致性的流量增加。最后复制toggle bits。
The first subsequent read by a client transitions the cache line pair to the S state and copies the data. Subsequent reads by other clients on the same socket are served by their local last-level cache. In short, every round of service, serving up to 15 clients on one socket, incurs at most 17 cache line data transfers and 17 corresponding cache line invalidations over the interconnect. -
NUMA-aware allocation of request and response lines,请求行分配在客户端所在的结点上面,响应行则在服务方所在的结点;
-
Minimal demarshalling overhead,降低由内存到对象的开支,
our server starts processing a request by reading the specified number of parameters from the request into the parameter passing registers. It then calls the specified function, and finally buffers the eventual return value for subse- quent combined transmission. -
No atomic instructions,不使用用原子指令。
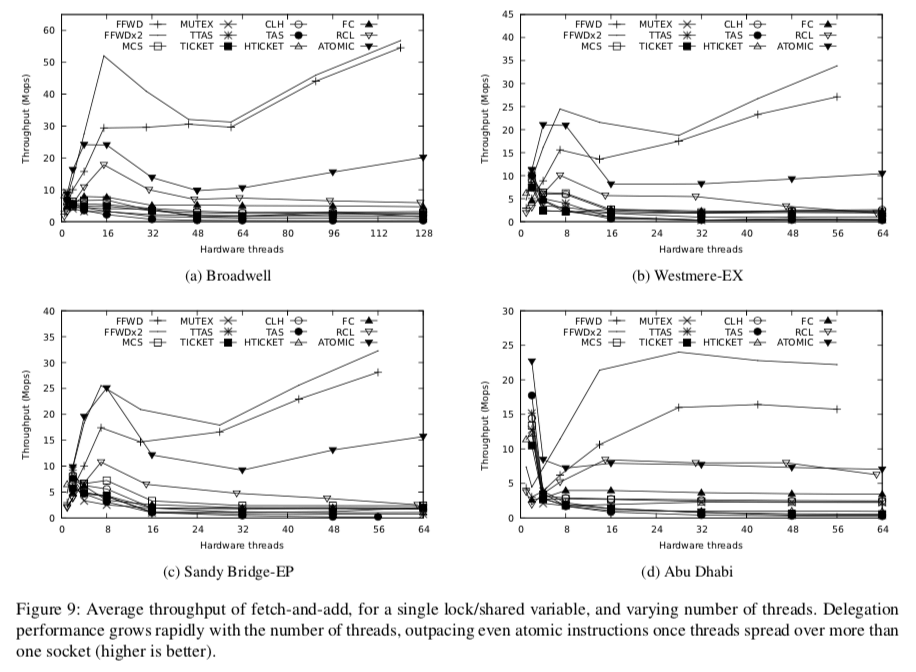
性能表现:
参考
- Remote core locking: migrating critical-section execution to improve the performance of multithreaded applications, ATC’12.
- ffwd: delegation is (much) faster than you think, SOSP 2017.
