Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network
0x00 引言
这篇Paper Google数据中心网络发展的一个综述性的文章,这篇文章不是具体讨论一个数据中心网络的设计,而是讨论了Google的数据中心网络的发展变化,
Our datacenter networks run at dozens of sites across the planet, scaling in capacity by 100x over ten years to more than 1Pbps of bisection bandwidth.
0x01 动机与设计理念
Google发展它自己的网络的动机很简单:使用其它厂商的解决方案不仅仅是价格的问题,而且是很难区满足Google的要求。Google建设自己的网络的时候遵循下面的设计原则:
- Clos topologies,Clos是数据中心网络中最常见的网络拓扑技术,在很多的数据中心网络架构中得到了应用;
- Merchant silicon,使用普通的商用芯片而不是特用的。普通的商用芯片价格便宜得多,而且随着芯片技术的发展快速升级。定期更新网络电缆和最新代的芯片能够满足带宽增长的需要;
- 中心化的控制协议,数据中心网络的环境一般都是比较简单的,而且结构是稳定的,使用中心化的控制方法能够很好的满足要求;
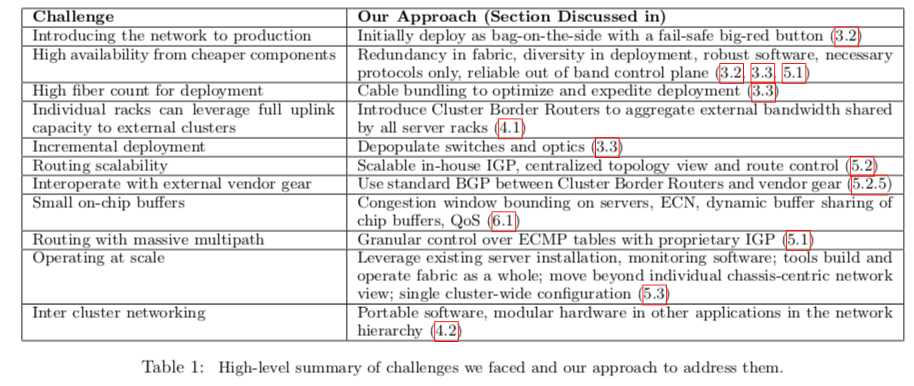
Google的数据中心网络的发展简而言之就是使用通常的硬件和Clos拓扑技术实现了Google对网络带宽快速增长的需要。下面的表是Google在数据中心网络发展中遇到的问题已经解决方案总结,
0x02 网络演进
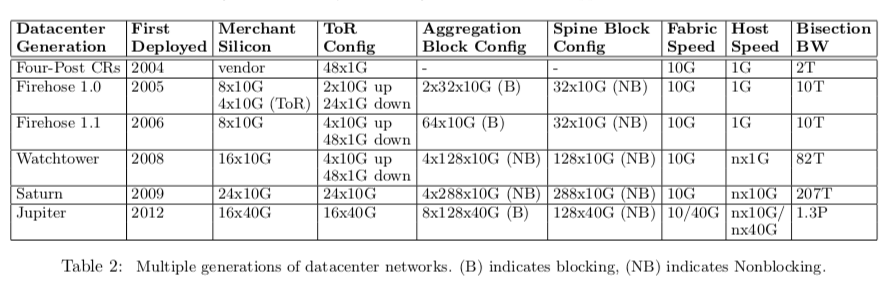
Google的数据中心网络的发展到这篇论文发表是一句经历了5代(Jupiter是2012开始部署的,估计到现在Google已经是这个下一代的产品了),下面是一个总结性的表:
Firehose 1.0 and Firehose 1.1
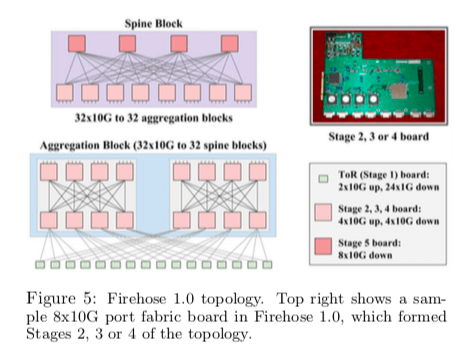
Firehose 1.0的基本拓扑如下图。Firehose 1.0的设计目标是为10K级别的机器机器每台提供1Gbps的带宽。它是一个五层的设计,最上层提供8*10G的端口,只会有向下的端口。而机架的交换机TOR是连接主机和上面层的。向下是24x1GE的端口,而向上是 2x10GE的端口。中间的都是4x10G的端口。如下面的图说是,第2、3层的交换机没8台组成一个聚集块(aggregation block),根据前面的端口的数量,它可以连接16台ToR交换机,每个ToR交换机连接20台主机,这样就是320台机器。第4、5层组成的是骨干块(spine block),各的交换机的数量为8台和4台。有32个10G的接口接下层,
Each aggregation block hosted 16 ToRs (320 machines) and exposed 32x10G ports towards 32 spine blocks. Each spine block had 32x10G towards 32 aggregation blocks resulting in a fabric that scaled to 10K machines at 1G average band- width to any machine in the fabric.
FH1.0存在的一个缺点在与它的两个ToR交换机之间连线无法正常工作的时候相关连的机架就不能联系了。
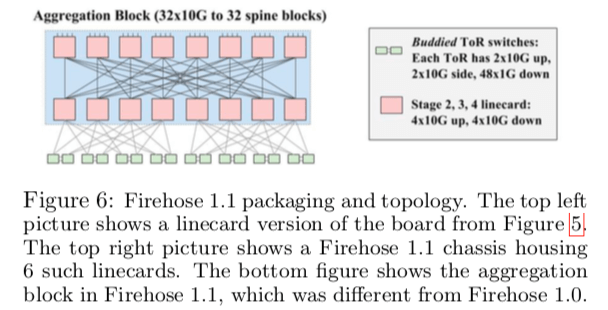
FH1.0并没有实际被部署,第一个被部署的是FH1.1。它相对于1.0的改进在于ToR使用两个4x10G+24x1G互连代替了原来的一个,改进了FH1.0存在的一些缺陷变成了下图所示的样子,
With up to 40 machines under each ToR, the FH1.1 aggregation block could scale to 640 machines at 2:1 oversubscription. The changes in the aggregation block allowed Firehose 1.1 to scale to 2x the number of machines while being much more robust to link failures compared to FH1.0.
FH1.1的时候,Google采取了保守的做法。FH1.1和之前使用的网络是同时存在的。
Watchtower
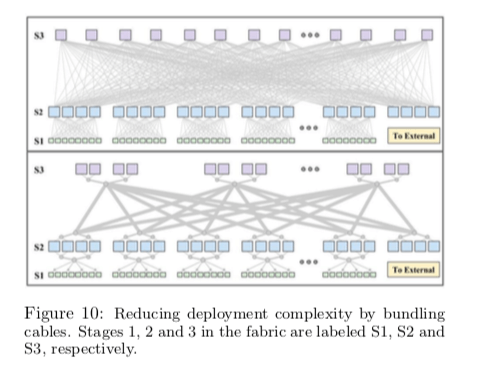
在FH1.1获得成功之后,Google发展了第3代的Watchtower。主要就是利用新一代的16x10G的交换机芯片。它还使用了捆绑光纤的技术,得到了诸多的好处,如下图所示。
Saturn
第4代的改进也主要是为了利用新的24x10G的交换机芯片。每一个Saturn底盘自持12个卡,这样就能提供288个端口的无阻塞交换。另外还有就是Pluto的单芯片的ToR交换机,它支持4x10G的端口为20台主机平均每台提供2Gbps带宽。对于对带宽要求更加高的情况,ToR交换机可以支持 8x10G向上的接口和16x10G 的接口为每台主机平均提供5Gbps的带宽。另外一个重要的特性就是服务器最大可以获取10Gbps的带宽。
Jupiter
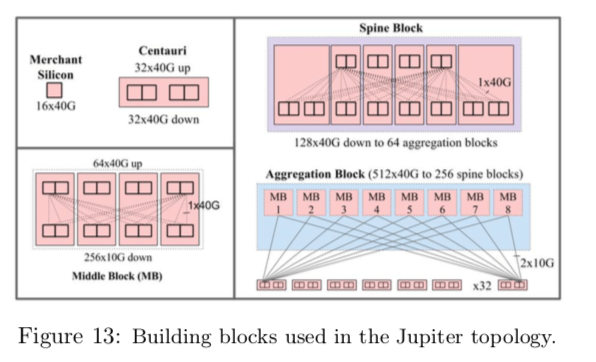
Jupiter是这篇Paper时最新的一代。它使用了16x40G的交换机芯片。它也使用了新的改进的拓扑结构。四个16x40G的芯片组成一个Centauri,然后上下四组相连组成一个Middle Block,这个是聚集块的基本组成单元。在聚集块中,由8个这样的MB组成,向上是40Gbps的端口与骨干块连接。每一个ToR交换机是48x10G的端口面向主机16x10G面向上,
Each ToR chip connects to eight such MBs with dual redundant 10G links. The dual redundancy aids fast reconvergence for the common case of single link failure or maintenance. Each aggregation block exposes 512x40G (full pop) or 256x40G (depop) links towards the spine blocks. Jupiter employs six Centauris in a spine block exposing 128x40G ports towards the aggregation blocks.
0x03 软件控制
Google在路由算法(软件)也是使用了自己开发的技术,也认为已经存在的解决方案不能满足Google的要求。在路由方面,Paper中主要讨论了下面这些内容:
-
Neighbor Discovery to Verify Connectivity,因为在网络的部署使用中难免会存在一些错误,Google使用Neighbor Discovery (ND)协议来解决网络中的在线存活性和对等正确性检查问题,它使用一些预配置的网络拓扑和端口ID检查的方式来检查正确性,
Neighbor Discovery (ND) uses the configured view of cluster topology together with a switch’s local ID to determine the expected peer IDs of its local ports. It regularly exchanges its local port ID, expected peer port ID, discovered peer port ID, and link error signal. Doing so allows ND on both ends of a link to verify correct cabling. -
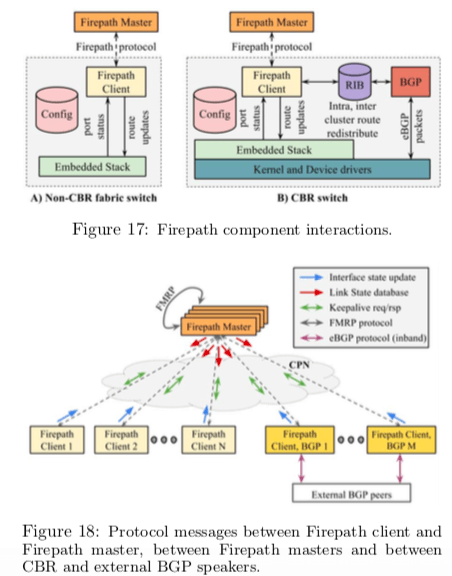
Firepath,Firepath是Google发展的路由算法,Firepath的一个特点是由一个中心化的服务器来协调处理,这个中心服务器会有冗余的设计。另外,在网络边缘使用的是BGP协议。
0x04 一些经验
另外Paper中还总结了几个在发展过程总的几条经验,
-
线路拥塞(Fabric Congestion),Google发现路线在利用率达到25%的时候就会发生由于拥塞导致丢包的问题,分析之后发现有以下的原因:1. 网络内突发的流量;2. 交换机的缓存不足,没有与使用的网络栈想适应;3. 为了节省成本的超额认购(oversubscribed),比如ToR的上行线路;4. 不完美的 flow hashing ,特别是在出现错误的情况下。Google也使用了一下的一些方法来解决这些问题:1. 设置QoS;2. 设计TCP拥塞窗口;3. 不要过多的oversubscribed;4. 使用ECN(DCTCP中的思路?);5. 改进交换机;6. 使用更好的hashing来实现更加好的负载均衡;
Our congestion mitigation techniques delivered substantial improvements. We reduced the packet discard rate in a typical Clos fabric at 25% average utilization from 1% to < 0.01%. -
运行中断(Outages)。这里是发现的导致网络无法正常工作的几个原因: 1. 控制软件太老无法应对这么大的规模;2. 老旧的硬件会出现的未知的问题;3. 人操作配置的一些失误;
参考
- Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network, SIGCOMM’15.
