TIMELY: RTT-based Congestion Control for the Datacenter
0x00 引言
这篇文章是发表在 SIGCOMM ’15一篇关于为Datacenter设计的基于RTT的Congestion Control算法的Paper。基于RTT的Congestion Control算法在很多年前就已经出现了,这篇Paper推出的算法在数据中心网络的环境下面实现了更加好的效果,
We show using experiments with up to hundreds of machines on a Clos network topology that it provides excellent performance: turning on TIMELY for OS-bypass messaging over a fabric with PFC lowers 99 percentile tail latency by 9X while maintaining near line-rate throughput. Our system also outperforms DCTCP running in an optimized kernel, reducing tail latency by 13X.
0x01 基本思路
关于使用RTT作为拥塞控制的优点和缺点可以这里可以参考一下[1]或者是其它相关论文。TIMELY的基本的思路很简单,这里可以先来看[2]上面给出的TIMELY上面的算法的C++代码的实现的判断,这部分主要就是新Rate的计算。可以看出在这段代码中,输入原来的发送的Rate和现在测量的RTT,就可以获取RTT的值,
/***********************************************************
TIMELY Algorithm to compute new rate
************************************************************/
/*
It is assumed this function is part of a 'sender' class, which declares the required instance variables and paramaters as detailed below.
It takes as input the current rate at which data is being sent and the current rtt.
It can be invoked when an ack/completion event is received.
It returns the new rate that can be enforced by the 'sender'.
*/
/*
Parameters used and their recommended values (these values may need finetuning based on experimental scenario)
ewma_alpha: recommended value = 0.02
t_low: recommended value = 0 (if using per-packet pacing), 50us (if using per 64KB message pacing)
t_high: recommended value = 1ms
HAI_Thresh: recommended value = 5
additiveIncrement: 10Mbps for 10Gbps line rate
decreaseFactor: 0.8
maxRate = line rate
minRate = optional
*/
/*
Other instance variables used and their initialization
prevRTT_: previous RTT (initialized to 0)
negGradientCount_: negative gradient counter for HAI increase (initialized to 0)
avgRTTDiff_: moving average of the RTT difference (initialized to 0)
minRTT_ = fixed minimum network RTT value
last_update_time_: initialized to 0
*/
double getNewRate(double rtt, double rate) {
if(prevRTT_ == 0) prevRTT_ = rtt;
double rtt_diff = rtt - prevRTT_;
if (rtt_diff < 0) {
negGradientCount_++;
} else {
negGradientCount_ = 0;
}
avgRTTDiff_ = ((1 - ewma_alpha) * avgRTTDiff_) + (ewma_alpha * rtt_diff);
double normalized_gradient = avgRTTDiff_ / minRTT_;
double delta_factor = (curTime() - last_update_time_) / minRTT_;
delta_factor = min(delta_factor, 1.0);
prevRTT_ = rtt;
last_update_time_ = curTime();
double new_rate;
if (rtt < t_low) { //additivive increase if rtt < t_low
new_rate = rate + (additiveIncrement * delta_factor);
} else {
if (rtt > t_high) { //multiplicative decrease if rtt > t_high
new_rate = rate * (1 - (delta_factor * decreaseFactor * (1 - (t_high / rtt))));
} else {
if (normalized_gradient <= 0) { //additive increase if avg gradient <= 0
int N = 1;
if (negGradientCount_ >= HAI_thresh) N = 5;
new_rate = rate + (N * additiveIncrement * delta_factor);
} else { //multiplicative decrease if avg gradient > 0
new_rate = rate * (1.0 - (decreaseFactor * normalized_gradient));
}
}
}
//derease in rate capped by 0.5 times the old rate
new_rate = max(new_rate, rate * 0.5);
//enabling max and min cap on the new rate
new_rate = min(new_rate, maxRate);
new_rate = max(new_rate, minRate);
return new_rate;
}
TIMELY Framework主要有三个部分组成:
-
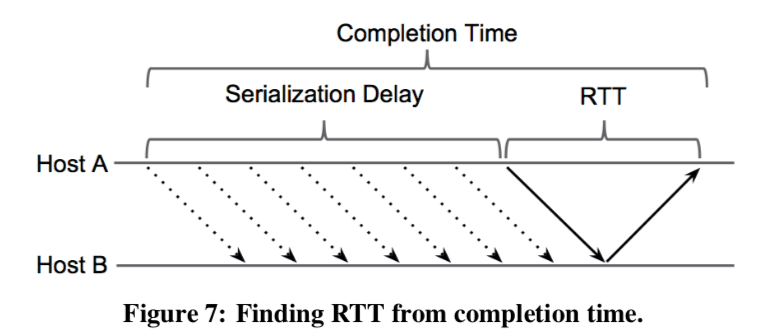
由于算法时以RTT为核心,所以RTT的测量当然就是核心的部分。RTT的定义如下图所示,注意这里和TCP中定义的RTT存在一些差别,
We define the RTT in terms of Figure 7, which shows the time-line of a message: a segment consisting of multiple packets is sent as a single burst and then ACKed as a unit by the receiver. A completion event is generated upon receiving an ACK for a segment of data and includes the ACK receive time. The time from when the first packet is sent (t-send) until the ACK is received (t-completion) is defined as the completion time. Unlike TCP, there is one RTT for the set of packets rather than one RTT per 1-2 packets.数据在端到端的传输中的演示来自多个方面,TIMELY只会关注传播延时和排队延时。RTT通过下面的公式计算, \(\\ RTT = t_{completion} - t_{send} - \frac{SegSize}{NICLineRate}\) 此外这里为了更加精确地测量到RTT,要求NIC有下面的两个支持:
- ACK时间戳,t-completion由NIC提供,OS提供这个时间戳的方式会收到其它的因素的影响,使其变得不精确,比如调度和中断。同理t-send也是NIC在一个segment发动开始时设置的时间戳;
- Prompt ACK generation,使用基于NIC的ACK的方式,消除了OS处理数据包的时间带来的周转时间导致的RTT计算的不准确。因为这里传播延时和排队延时,在数据中心这些数据在多数的情况下都比较小,这样的话对测量的精度要求就比较高。
-
新Rate计算,如上面的代码所示,具体的逻辑在下面说明;
-
Rate控制,TIMELY使用的方法是基于速率发送Segment的方法,在前面计算出发送的速率之后,一个发送的调度器会根据Segment Size和最后一个Segment发送的是来决定当前Segment发送的时机。Paper中认为,传统的TCP基于窗口的方法不能很好的实现数据中心这样的环境,
The bandwidth-delay product is only a small number of packet bursts in datacenters, e.g., 51 μs at 10 Gbps is one 64 KB message. In this regime, windows do not provide fine-grained control over packet transmissions. It is easier to directly control the gap between bursts by specifying a target rate. As a safeguard, we limit the volume of outstanding data to a static worst-case limit.
0x02 TIMELY拥塞控制算法
在数据中心网络中,常有突发性的消息发送的负载。不同于广域网,在数据中心中,网络的带宽一般是足够的,流完成时间是最关心的,比如在RPC这类的应用,这个就直接影响到RPC的核心技术指标。TIMELY主要关于的指标就是99th的RTT的时间和吞吐量,当这个两个指标出现冲突的时候,有限选择低延时。下面是算法实现的伪代码:

算法的一个核心是delay gradient,或者叫做queue随着时间变化的导数。上面的的C++代码有一个误导人的地方,就是输入看似只有double rtt, double rate,当时间上还是需要用到之前的RTT的数据(一个问题: Paper中使用的算法是使用了一个过去的RTT值,如果使用不止一个呢?),也就是说输入不只是double rtt, double rate而已。算法还是基于拥塞控制基本的AIMD的原则,下面的图很好的表示了基本的原理,注意下面的T-low、和T-hight两个定义的值。来看看主要的算法:
- Computing the delay gradient,计算延时的变化率,就是上面伪代码中的normalized_gradient得计算过程,rtt-diff的计算思路和一般TCP中使用的方式很相似。
- Computing the sending rate,新速率的计算在上面的伪代码中主要分为4中情况下,也是下面的这个图思想的体现。基本的思路就是当RTT小于一定的值的时候加性增(T-low),在RTT大于一定值的时候(T-high)被认为发生了拥塞,就应该乘性减,在中间的主要就是看着根据RTT的变化,这里的思路和一些TCP拥塞控制的算法的思路比较相似,可以理解为在AIMD之间加入另外一个类似过渡的阶段来实现更加好的性能,具体细节讨论[1]。
- RTT变化率和QueueSize之间的讨论;Paper中通过一些数据表明,基于QueueSize的方式可以实现低延时or高吞吐,但是很难二者皆得。而基于变化率更能反映变化的趋势,预测到可能即将发生的拥塞,实现更加好的权衡。

0x03 评估
具体信息可以参看[1]
参考
- TIMELY: RTT-based Congestion Control for the Datacenter, SIGCOMM ’15.
- TIMELY Algorithm Code Snippet: http://radhikam.web.illinois.edu/timely-code-snippet.cc
