Maglev: A Fast and Reliable Software Network Load Balancer
0x00 引言
Maglev是Google的网络负载均衡器。Maglev 2008年开始在Google中得到应用,然后这篇论文发表在2016年(Google的风格)。不仅如此,国内的一些厂商在Google的这篇论文之上开发了类似于Maglev的系统。
0x01 概览
Google的每个服务器会被赋予一个or多个的VIP,这个VIP不同与实际的IP地址,这些VIP的背后是Maglev在处理。Maglev 会将一个VIP和一组的服务入口关联,这些信息会交给路由器(使用BGP路由协议)。之后这些VIP的信息时在互联网可见的,主要是用户的DNS请求之后,Google授权的DNS服务器会更具用户的位置和目前的负载均衡情况给用户返回一个VIP地址,之后就可以和这里VIP地址建立连接。路由器收到一个VIP的数据包是,使用ECMP的方式来决定将这个包发送给哪一个Maglev机器。之后就是Maglev收到这个包,它会使用它的方法从与这个VIP关联的服务器中选择其中的一个,之后这个数据包会被封装为Generic Routing Encapsulation(GRE)包(with the outer IP header destined to the endpoint)。服务器在处理请求给用户回复的时候,就可以直接将数据包递交给用户(原地址为VIP,并不使用服务器实际的IP地址),这样回复的数据包就可以不经过Maglev,又由于回复的数据一般都大于请求的数据,这个对提高Maglev实际的处理能力还是很有好处理的。这种处理的方式被称为Direct Server Return (DSR) ,具体的实现的内容在Paper中没有说明。
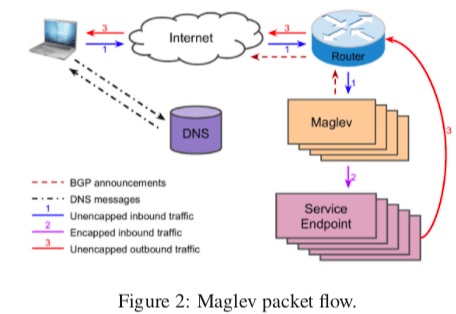
配置
在一台Maglev的机器中,主要就是两个部分,一个转发器和一个控制器。Maglev使用的VIP的相关的信息都来源于配置对象,这个最终来源于其它外部系统,Maglev使用RPC的方式去获取。在转发器中,一个VIP会配置一个or多个的后端(服务器)的资源池。一个池子里面包含的可能是后端服务器的实际的IP地址,也可能是递归包含另外的池子。这些池子会有对应的健康检查的方法。转发器的config manager负责来处理和验证配置信息。另外,对于一个集群来说,它可以配置多个的maglev,每一个负载处理不同的VIPs的部分。
0x02 转发器设计与实现
为了提高处理的性能,转发器的数据包处理是Kernel Bypass的。Maglev Kernel Bypass的技术采用的是Google自己开发的技术,没有采用现在的一些解决方案的原因可能是Maglev实际开发的很早。在Magev之中,数据被网卡接受到之后,Maglevc的steering模块会根据header中的5元祖使用 5-tuple hash算法来计算出一个hash值。然后根据这个hash值陪分配到不同的接受队列。这些队列中的包会被一个Header Rewriter的线程进行操作,这个线程首先会判断这个数据包是不是发给一个VIP的,在上面的Packet Flow的图中也有表示这两种包的处理路径有所不同。之后就是根据5元组hash去查找connection tracking table。这里为了避免跨线程的同步,这个第二次使用的hash值是重新计算的。
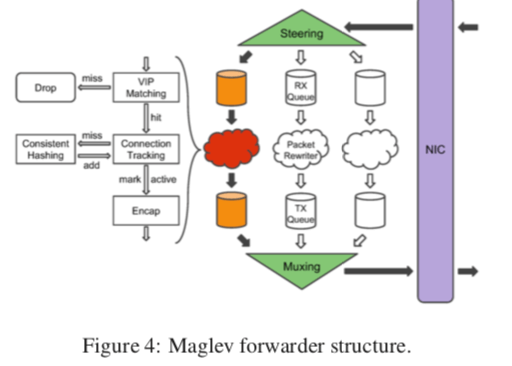
这个connection tracking table包含的是最近使用的一些后端的服务器的一些信息,在这个表中存在表明这个服务器在目前应该还是可以使用的,这个结果就可以继续使用。如果没有发现,那么就要使用一致性hash的方法选在一个性的后端服务器来使用,并添加到这个table中,以便于后面重用这个结果。在没有可以使用的后端服务器的时候,这个数据包就会被drop。另外,这个table是每一个处理的线程一个,避免了同步带来的开销。之后数据包被封装合适GRE/IP Header,转交给transmission queue,一个muxing模块会轮询这些queues,然后交给NIC发送。
包处理
在10Gbps的链路上面,如果数据包的大小为100bytes,那么一秒也处理的包的数量就有 9.06M,即使是1500bytes,也有813K。直接使用Linux内核网络栈处理起来比较困难。在Maglev中,数据从NIC到转发器是完全不同内核参与的。在Magelv启动的时候,就会预先分配一个packet pool,有NIC和转发器共享。这里应该就是一个使用ring queue的生产者消费者模型,
Both the steering and muxing modules maintain three pointers to the rings. At the receiving side, the NIC places newly received packets at the received pointer and advances it. The steering module distributes the received packets to packet threads and advances the processed pointer. It also reserves unused packets from the packet pool, places them into the ring and advances the reserved pointer.
在Magelv中,处理一个数据包的时候一般为350ns。转发器使用批处理的方式来平摊在每一个数据包上面的消耗。导致可以导致一些包处理的延迟变长,这个是一个普遍存在的问题,这个超时的时间在Magelv中被设置为50us。这个情况在Maglev工作量很小的时候显得更加明显,一个处理的方式是动态的批处理的待下。另外一个可能导致延迟增大的情况是Magelv处理负载太大的时候。关于Maglev的另外两个问题,
-
后端服务器的选择,这里主要就是两个问题:1. 使用一种新的一致性hash来在可用的后端服务器中选择一个,2. 对于TCP这类面向连接的传输协议来说,需要记录一个flow转发到的服务器。对于第二点,Magelv使用一个固定大小的Hash Table来追踪这些连接。但是,仅仅是每台Maglev机器使用的追踪方式还是不够的,有几个原因:具有起一般不提供连接亲和性;Magelv的机器状态、数量也会变化,另外这个追踪使用table的大小也是有限的;
-
一致性hash,为了解决上面的问题,Maglev还使用了一种新的一致性hash的方法,Maglev hashing。Maglev hashing的基本思路是给每一个后端服务器分配一个查找表的位置的一个偏好列表,每个后端机器会去填写它们喜欢的位置,直到这个table被填满。
Pseudocode 1 Populate Maglev hashing lookup table. 1: function POPULATE 2: for each i < N do next[i] ← 0 end for 3: for each j < M do entry[j] ← −1 end for 4: n ← 0 5: while true do 6: for each i < N do 7: c ← permutation[i][next[i]] 8: while entry[c] ≥ 0 do 9: next[i] ← next[i]+1 10: c ← permutation[i][next[i]] 11: end while 12: entry[c] ← i 13: next[i] ← next[i]+1 14: n ← n+1 15: if n = M then return end if 16: end for 17: end while 18: end function /* Then we generate permutation[i] using these numbers as follows: offset ← h1(name[i]) mod M skip←h2(name[i]) mod (M−1)+1 permutation[ i ][ j ] ← (offset + j × skip) mod M */
0x03 另外的几个问题
关于Maglev的另外的几个问题,
-
故障处理,Maglev开始的时候使用备份的方式来保证在一台机器故障之后另外一台可以无缝切换,不过这样的方式效率太低。只有50%的利用率。之后Maglev使用在ECMP上改进的方法,
We gained a great deal of capacity, efficiency, and operational simplicity by moving to an ECMP model. While Maglev hashing continues to protect us against occasional ECMP flaps, we can multiply the capacity of a VIP by the maximum ECMP set size of the routers, and all machines can be fully utilized. -
IP分片处理。处理这个问题需要处理两个问题,一个是要保证所有的发片的数据包被发送到同一个Maglev机器,另外一个是Magelv对分片了的数据包也会选择同一个后端服务器。这里的第一点就是很难满足的,Magelv的解决方式在使用一个pool,这个pool包含Magev机器的信息,Maglev在这些分片的数据包上使用3元组hash(L3 header)转发到一个Magev机器。解决第二个问题也使用了和处理连接传输协议一样的追踪的方法。这样的方式页存在一些缺点,
This approach has two limitations: it introduces extra hops to fragmented packets, which can potentially lead to packet reordering. It also requires extra memory to buffer non-first fragments. Since packet reordering may happen anywhere in the network, we rely on the endpoints to handle out-of-order packets.
0x04 评估
这里的详细详细可以参看[1],
Stateless Datacenter Load-balancing with Beamer
0x10 引言
这里Paper是NSDI‘18上面的,这篇Paper中的主要数据也是和Maglev的对比。在Paper
0x11 Stable Hasing & Daisy Chaining
Stable Hasing
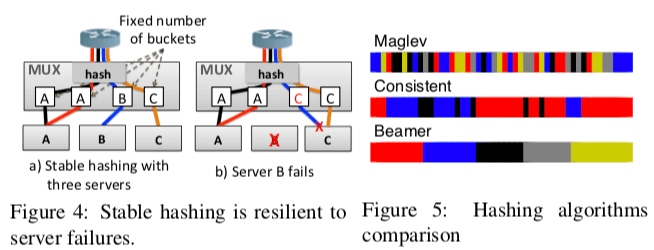
在使用hash多路分发数据包的时候,前面的Maglev使用了一种一致性hash的变体Maglev Hashing。而在这里Beamer提出了另外的一种hash的思路:连续会被hash算法hash到若干的的buckets,这里的buckets的数量会远大于服务器的数量,这里Buckets的数量记为B,服务器的数量记为N(B的数量严格大于N,比如B = 100N)。一个Bucket在一个特点的时间只会对应一台服务器,而一台服务器会对应到多个的Buckets。Beamer同样使用连接的5元组计算出hash值,然后使用b=hash(5tuple)%B选择对应的Bucket,从而转发给对应的服务器。在Beamer关联一台服务器的Buckets是连续的。这些Bucket到服务器的映射关系会因为服务器的故障或者就是人为去修改,这些信息会被保存早可靠的存储中,Beamer选择的是ZooKeeper。这个映射改变的频率是很低的,
When server B fails, the controller will move the third bucket from B to C; the mapping is then stored in ZooKeeper and disseminated to all muxes. After the mapping is updated, flows initially going to A or C are unaffected, and flows destined for B are now sent to C. Only the blue connection, handled by B, is affected.
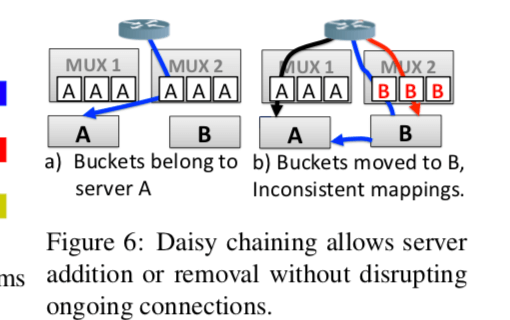
Daisy Chaining
Daisy Chaining为了处理映射关系变更的时候旧的连接的问题的。基本的方式就是在服务器收到之前的连接的数据包的时候将其转发给正确的服务器。在映射关系变更之后,mux会记得之前这个bucket映射到哪一个服务器,mux会将这些信息和数据包封装到一个包里面,服务器在接收到这些数据包之后,会根据包的类型(SYN (TCP or MPTCP),a valid SYN-cookie ACK或者是一个本地连接的数据包),则会就地处理,如果不是,则需要对这个包进行转发。对这样的处理会有一个超时的时间,如果超时了就会将包drop,并会发送RST包。
这里还有另外一个问题要处理,在下面的图中,开始的时候只有mux1,之后添加了mux2,mux2有更新之后的配置的信息,而此时mux1还是使用之前的配置信息。图中红色的连接后面的数据包发送给了mux1(基于ECMP转发的数据包),由于mux1还不知道新的配置信息,这个数据包会被mux1转发给A,A将会reset这个连接。为了解决这个问题,数据包会带上一个generation的信息(epoch),每个服务器会记住它遇到的最高的epcoh,比如在A中收到了B来的数据包,带有的generation信息为2。当A收到一个连接中间状态的数据包(就是连接好之后一般的数据包),如果不是通过Daisy Chaining过来的,回去检查是不是有最高的generation number,是就reset连接,否则静默drop这个数据包,客户端就会重传这个数据包。
0x12 MPTCP
现在存在的一些负载均器不能很好地处理MPTCP的情况,如Ananta, Maglev, SilkRoad, Duet等将MPTCP的子流都视为独立的TCP连接,这样的话不同的子流可能最终被发送到不同的服务器。Beamer使用大于1024的端口作为服务器的标识,在Beamer部署的时候就会决定这个标识关系。一个MPTCP后续的子流会使用这些指定的端口。另外,mux为了处理这些MPTCP的子流,在上面的伪代码中也有体现,大于1024端口的数据包会被直接处理,
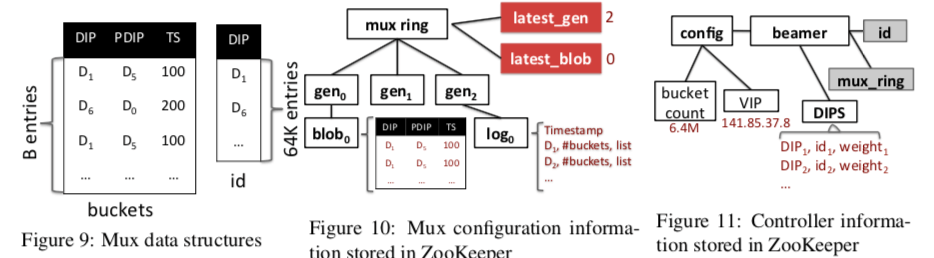
As each server has exactly one port associated to it, our solution can support at most 64K servers for each VIP. The muxes use another indirection table called id, that simply maps port numbers to DIP addresses (identified with Di here, see Fig. 9).
Note that we only need daisy chaining to redirect initial subflows of MPTCP connections or plain TCP connections. Secondary subflows are sent directly to the appropriate server (uniquely identified by the port).
0x13 控制面
Beamer的控制面基于ZooKeeper设计。控制器会向其中写入配置相关信息,而mux只会从中读取它们。
0x14 评估
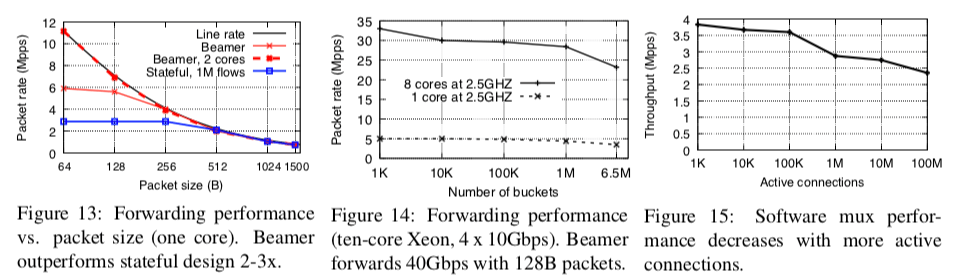
这里的具体信息可以参看[2],
参考
- Maglev: A Fast and Reliable Software Network Load Balancer, NSDI’16.
- Stateless Datacenter Load-balancing with Beamer, NSDI’ 18.
