Understanding PCIe Performance for End Host Networking
0x00 引言
这篇Paper从PCIe的角度讨论了PCIe性能对终端网络的影响。Paper中指出,随着网络带宽的增长,在40Gb和100Gb的网卡面前,PCIe也会成为网络性能的一个瓶颈。Paper中提出了一个pcie-bench工具,用来测量PCIe在多种环境下的一些性能指标。更重要的是通过对这些测量的数据来对以后的系统设计提出指导。
0x01 背景
PCIe对网络延迟的影响。PCIe的传输会增加延迟,特别是网络数据包很小的时候,这个延迟占到(终端部分?)的90%。另外,对着多种的技术操作对PCIe的性能测量是比较困难的,比如intel的DIDO技术,还有就是NUMA也增加测量的复杂度。还有就是IOMMU的影响。PCIe的一些特点:
-
PCIe是通过几条串行链路连接的串行连接,它的协议有3层:物理层,数据链路层和传输层。
-
现在一般的40Gb的网卡使用的是第3代的PCIe,使用8路,每路提供8GT/s的带宽。使用128b/130b编码下实现的带宽是8 × 7.87 Gb/s = 62.96 Gb/s。这个理论上的最大带宽,算上数据链路层加入overhead,这个带宽大约在 57.88 Gb/s。另外在传输层又会增加开支。
-
读取一定的数据量sz情况下,实际需要传输的数据量: \(\\ B_{tx} = \lceil sz / MRRS \rceil \cdot MRdHdr + sz \\ B_{rx} = \lceil sz / MPS \rceil \cdot CplHdr + sz\\ 其中MRRS,MPS每次最大能传输的量;MRdHdr,CplHdr,头部的大小;\)
上面的一些事基本的情况,另外考虑到诸多的优化技术情况下会更加复杂。
0x02 测量方法
测量主要关于带宽和延迟两个指标。测量中使用的host buffer要考虑到是否在地址空间中是否联系、缓存的大小等。对于测量缓存影响的情况。这里还有很多的细节的考量[1]。
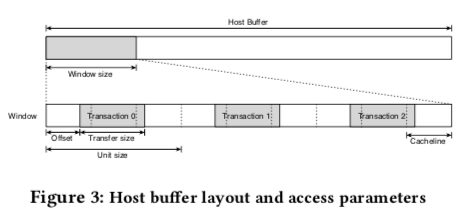
-
延迟。对于度延迟的测量通过发送一个读的请求,记录发出的时间戳。测量延迟只能用很小的数据包。在完成之后DMA engine会通报一个完成的时间戳。通过这两个时间戳的时间差来测量,记为LAT_RD。由于写操作没有读操作这样的显式的ACK。使用的方法是写入数据之后从相同的地址在读取。这样的方法存在的缺点就是读写之间的相互影响。这个测量的值记为LAT_WRRD,
For latency benchmarks we record the latency for each transaction and then calculate the average, median, min, max, 95th, and 99th percentile.延迟的测量可以用来分析Cache和IO-TLB实效的代价、访问远程内存带来的额外的延迟等。写了之后读相同地址的方式也给了解如DDIO之类的技术提供方便。
-
带宽,带宽的测量就是完成一定量的工作使用的时间完成的。读写分别记为BW_RD 和 BW_WR。交替写和读的测量到的带宽记为BW_RDWR。这样的测量方式中,小数据和随机访问的方式会带来明显的开支。
上面的测量方式的原理是很简单的,但是具体去实现一个能够精确测量的工具远比理论上的描述难得多。关于这个工具具体是如何实现的内容[1],
0x03 一些测量数据
基本的带宽和延迟
无论是那种类型的操作,基本的特点都是在数据量较小的时候,带宽的性能随着每次传输的大小快速增加。在增长到256bytes时候,一般就保持一个max的值。
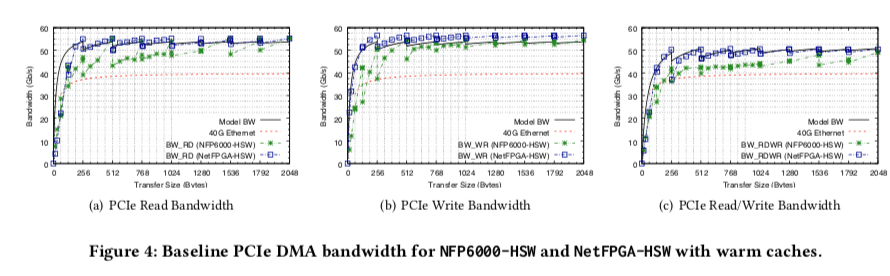
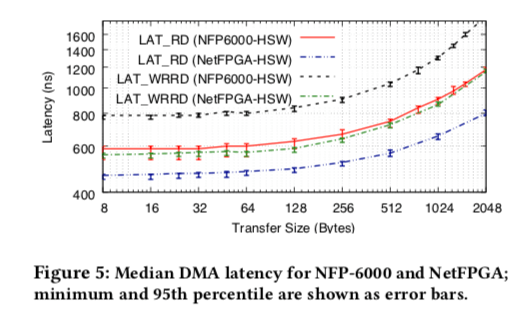
对于延迟就有点像相反的情况了,。在数据小于128bytes时候一般为 很接近的值。在256bytes之前都增长得比较慢。在增加就增长就类似于线性增长了。前面的带宽的数据和这里的延迟的数据都表明在64bytes之前,传输的成本都不怎么是传输数据本身,而是其它的额外的开销。在数据量增长时,传输数据本身就成为了主要的部分了。
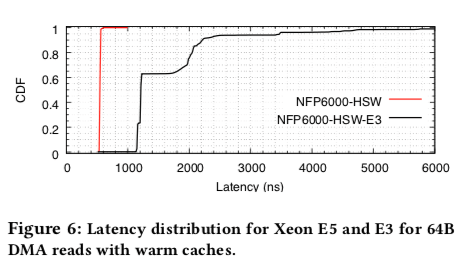
不同架构的对比
这里的不同架构的对比是E3和E5之间的对比,处理器是同一代的。性能的表现存在不小的差异,intel还是给更加高端的CPU更好的性能表现,包括在PCIe这些一般人不会去关注的方面。
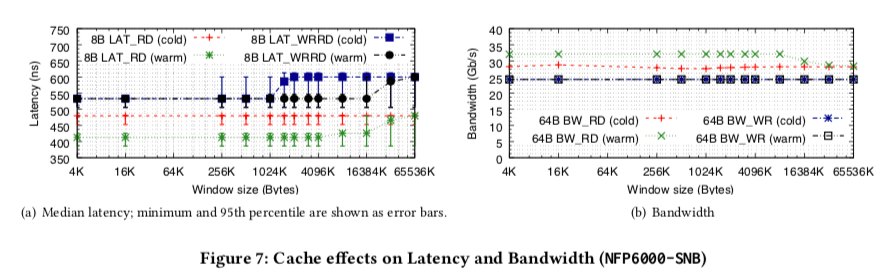
缓存 和 DDIO的影响
在8B大小情况下,读操作在没有预热缓存的时候和windows size没有什么关系,在预热了缓存的时候,windows size不超过LLC大小的时候比没有预热低了大约70ns,在超过了LLC的大小时就和没有预热的差不多了。对于写后读的基本的模式也和读操作类似。在带宽(右边)的数据中,写操作还是能从缓存中获益的,但是数量比较大时就不明显了。对于写的操作,缓存没有什么效果。
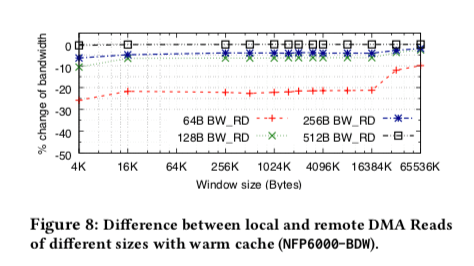
NUMA的影响
NUMA带来的影响是负面的。特别是在数据量比较小的时候,对于64B DMA reads操作,吞吐降低又20%,在128B or 256B的情况下,这个损失降低到 5-7%,再大的数据量就不怎么明显了。写入操作的吞吐则没有明显的影响。
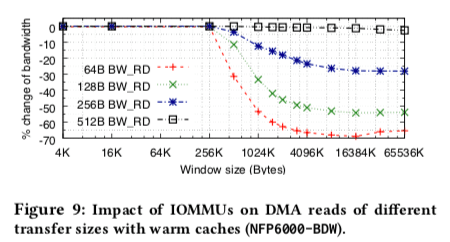
IOMMU的影响
在Paper中的实验数据中,window size尺寸对性能的影响很大,具体细节如下图,
几点结论以及问题的可以的解决方案:

参考
- Understanding PCIe performance for end host networking. SIGCOMM ’18.
