Ananta: Cloud Scale Load Balancing
0x00 引言
Ananta是一个Layer-4负载均衡器的设计,
... Multiple instances of Ananta have been deployed in the Windows Azure public cloud with combined bandwidth capacity exceeding 1Tbps. It is serving traffic needs of a diverse set of tenants, including the blob, table and relational storage services. With its scale-out data plane we can easily achieve more than 100Gbps throughput for a single public IP address.
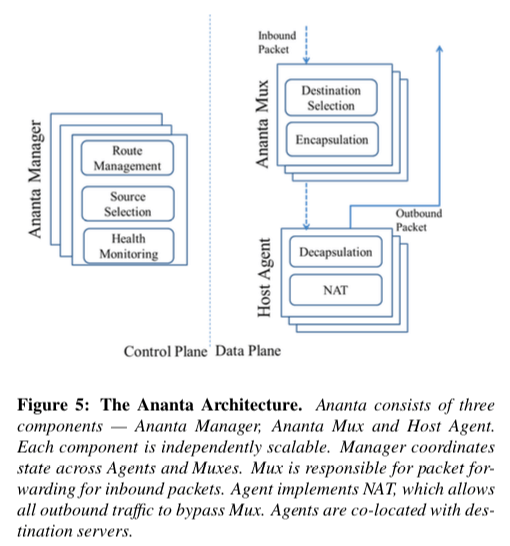
0x01 基本架构
Ananta的架构也是有Control Plane和Data Plane两个主要的部分,有3个主要的组件,Ananta Manager (AM), Multi- plexer (Mux) 和 Host Agent (HA)。在Ananta中,对外使用的都是虚拟IP(VIP),会对应到实际的若干的服务器(使用实际的IP,DIP)。对于来自外部的网络连接,路由器根据ECMP分发这些数据包,之后这些数据包会到达Ananta的Mux,Mux根据使用负载均衡的算法选择一个DIP,然后将这个数据包封装为一个IP数据包(IP-in-IP,目的地址为选择的DIP),之后就可以按照一般的数据包转发。HA在接受到数据包的时候,它会重写目的地址和端口(HA这步实现了一个NAT的功能),并会记住其NAT的状态信息,然后将数据包转发给虚拟机(VM)。当VM发送回复数据包的时候,HA根据之前的NAT的信息执行相反的动作,这里重写之后的数据包不会被发送到Mux,而是直接发送到前面的交换机,这个是一个很常用的方法,称之为Direct Server Return (DSR)。
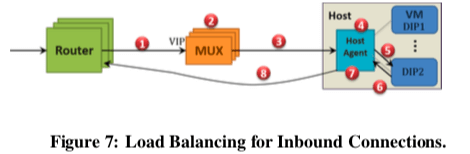
Ananta不仅仅处理来自外部的连接,还要处理内部向外面的主动连接。Outbound的连接需要Source NAT(SNAT)的机制 来处理。HA在收到需要这样处理的数据包的时候,会先将这些数据包放到一个队列里面,然后向AM申请一个VIP和一个端口,AM将分配的VIP和端口的信息回复HA,然后HA就可以利用这些信息重写这个数据包,之后就可以直接将这个福报转发给交换机了,这里也不需要经过Mux。外部回复的数据包安装前面的处理Inboud连接的方法处理即可。
微软在之间的使用中总结出的数据显示,数据中心内部的流行也占了很大的一个部分。为了优化intra-datacenter的流量,Ananta这里使用了Fastpath的机制。核心的思路就是数据中心内部的连接直接去使用DIP而不是经过VIP这样一个间接地处理。在数据中心内部的一个连接建立之后,转发数据到HA的Mux会使用重定向的消息通知源的VIP(设为VIP1),告诉它这个连接被分配到了一个DIP(设为DIP2)。接受到这个重定向消息的Mux会发送消息通知两个DIP,之后HA处理的时候就可以直接使用DIP来转发处理。
0x02 另外几点
关于Ananta的3个主要的组件,
-
Mux处理VIP向DIP的转发。每一个Ananta的实例会有一组的Mux,称为Mux Pool,一个Mux Pool的里面的机器的硬件和配置都是一样的。Mux利用了BGP的路由协议,它是一个BGP的Speaker。路由器转发数据的时候使用ECMP来平均分配流量。Mux中保存了两个对VIP到DIP转发至关重要的表:一个是VIP map,保存了一个(VIP, IP protocol, port)到DIP列表的映射,这些表的消息是AM产生的,Mux Pool中的每一个Mux会保存一份。另外一个是Flow Table,保存了每一个连接转发到了哪一个DIP,这个连接后续的数据包转发的时候要使用这里的信息。这里还要处理SYN泛洪攻击的问题,Mux将连接分为两类,一类是已经发送了多个数据包的连接,一类是还只发送了一个数据包的连接,前者连接超时的时间长于后者,后者超时的时间比较短。Mux容错的机制利用了BGP的一些功能,另外也可以使用一个Mux副本的方式,但是在这篇Paper中认为使用一个副本的方式成本和系统复杂度都会提高很多,而没有采用,客户端可以很容易使用重新连接的方式处理一个Mux故障之后的问题。
-
Host Agent处理转发数据包之外的两个关键作用就是实现DSR和SNAT。对NAT的处理主要就是处理 (VIP,protocol-v,port-v) 到(DIP,protocol-v,port-d)到映射的关系。除此之外,HA还有监控DIP的状态,HA会将本地虚拟机的情况报告给AM,前面的Mux会从AM获取这些信息,以便于作出处理。
-
AM就是Ananta的Control Plane,本身通过基于Paxos算法的多副本机制。如前面所言,AM要处理的一个问题就是SNAT端口的管理,
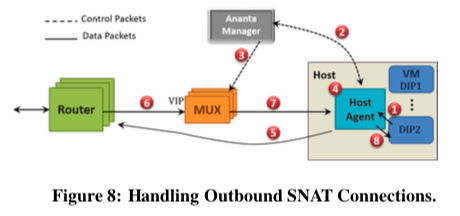
When an HA makes a new port request on behalf of a DIP, AM allocates a free port for the VIP, replicates the allocation to other AM replicas, creates a stateless VIP map entry mapping the port to the requesting DIP, configures the entry on the Mux Pool and then sends the allocation to the HA. There are two main challenges in serving SNAT requests — latency and availability.由于Ananta面向的是云的环境,多租户隔离性也是Ananta要处理的一个问题。为了保证QoS,Ananta会根据租户的权重来分配CPU、内存和网络等的资源。另外对于SNAT和Packet处理的公平性,
0x03 评估
这里的详细信息可以参看[1],
Duet: Cloud Scale Load Balancing with Hardware and Software
0x10 引言
Duet负载均衡器的设计是前面的Ananta的优化。Duet认为,Ananta基于软件实现的Mux在处理数据的时候会带来比较大的开销。Duet的一个核心是利用现在的交换机来实现一个Mux,Duet称之为HMux(Hardware Mux),
Our evaluation shows that DUET provides 10x more capacity than a software load balancer, at a fraction of a cost, while reducing latency by a factor of 10 or more, and is able to quickly adapt to network dynamics including failures.
0x11 基本架构
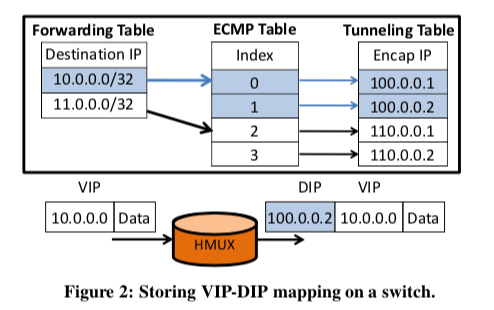
前面的Ananta中的SMux的两个主要的功能,一个是对于每一个VIP,将其流量分配给每一个的DIP,另外一个是使用IP-in-IP的封装的方式使得数据包可以正确地转发到指定的DIP。这些功能其实都可以在现在的商用的交换机上实现。Duet这里的一个核心的设计就是基于交换机的Mux的设计。下面的图是HMux的一个示意图,一个包到达HMux之后,使用流水线处理的方式,这里的核心就是三个表,在下面的图有表示。包转发的时候根据最前面的Forwarding Table找到对个ECMP的下一跳,后面的Tunneling Table用于实现IP-in-IP的封装。HMux可以实现很高的性能,但是比起SMux,在灵活性方面有一些的不足,所有这里Duet使用HMux和SMux组合工作的方式。另外,交换机上面的内存的空间是很有效的,就可能出现需要的数据无法全部保存到交换机里面。
为了解决交换机内存有限的问题,Duet使用的分区的方式,这里主要就是两种方式,一个是将VIP到DIP的映射分割保存到多台的交换机上面,每一个交换机只会保存保存一小部分的VIP,且这部分VIP对应的的DIP都会保存。另外一个就是使用BGP协议来声明那些VIP被赋予到了一个交换机,这些的话其它的交换机就可以将这些VIP的数据包转发到对应的交换机。这样分区的一个好处就是良好的可拓展性,可以很好地应对流量的快速增长。HMux的一个主要的缺点也是这样分区的方式导致的灵活性的不足。
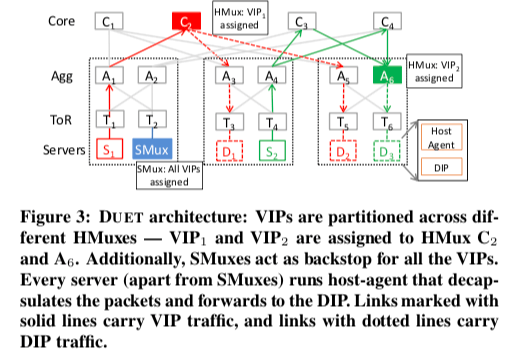
所以Duet处理部署了HMux之外,还在一些普通的服务器上面部署SMux。与HMux不同,由于SMux不同担心内存空间太少的问题,它会关联到所有的VIP,这里和Ananta是一样的。在某个HMux故障之后,相关流量会被分配到SMux。HMux和SMux使用相同的方法选择DIP。
0x12 VIP分配
由于Duet中的VIP是存在分配的,怎么样分配这些VIP能得到更加好的效果是这个分配算法主要考虑的。为了衡量资源利用率,Duet提出了Maximum Resource Utilization (MRU)的概念, 主要涉及到交换机和链路的利用率。系统根据流量从大到小排序,然后从大到下分配这些VIP。在可以的分配方案中,会选择使得MRU最小的方法,如果分配导致MRU超过100%,之后的就会让SMux来处理,算法结束, \(\\ 设第v个VIP分配给第s个交换机,在第i条链接上面增加的利用率为: \\ L_{i,s,v} = \frac{t_{i,s,v}}{C_i}, 其中t_{i,s,v}是根据系统状况计算出来的Load。\\ 增加的交换机内存利用率为L_{s,s,v} = \frac{|d_c|}{C_s}, \\ \text{i.e., the number Cs of DIPs for that VIP over the switch memory capacity.} \\ 总的利用率就是前面的相加,即U_{i,s,v} = U_{i,v-1} + L_{i,s,v}, 则MRU_{s,v} = \max(U_{i,s,v}), ∀i ∈ R.\) 另外要处理的问题就是由于各种原因导致的需要的VIP迁移的问题。系统的状态是动态,前面的分配可能已经不能很好的在现在的网络环境下面实现很好的利用率,另外就是网络、设备等出现的故障。为了处理在迁移的时候可能出现的问题,Duet使用了的方法,即实际迁移前向声明。为了处理Transitional Memory Deadlock和可能导致了较大的流量重新分配的问题,Duet还借助了SMux来实现迁移,
... DUET circumvents transitional memory deadlocks by using SMux as a stepping stone. We first withdraw the VIPs that need to be moved from their currently assigned switches and let their traffic hit the SMux. We then announce the VIPs from their newly assigned switches, and let the traffic move to the new switches.
另外,Duet还要处理HMux、Smux、链路和DIP故障的问题。另外的实际的系统中,支持VIP、DIP添加移除也是很有用的功能[2].
0x13 评估
这里的详细信息可以参看[2],
SilkRoad: Making Stateful Layer-4 Load Balancing Fast and Cheap Using Switching ASICs
0x20 引言
SilkRoad是前面Duet的优化。Duet基于硬件实现的Mux在很大程度上优化来Ananta的性能表现,但是SilkRoad认为Duet 优化得还不够彻底,SilkRoad则将可能地将逻辑放到服务器上实现。SilkRoad认为现在的交换机中内存已经有了很大的增长,可以保存更加多的内容,它将VIPTable(即VIP到DIP的映射)和ConnTable(即连接信息)都保存到交换机上面。这样SilkRoad就要解决两个问题,一个是将保存了数百万连接信息的ConnTable保存到几十MB的内存中,另外一个就是在可能频繁有DIP更新的情况下实现Per-Connection Consistency(PCC)。SilkRoad的一个基本的架构如下图,
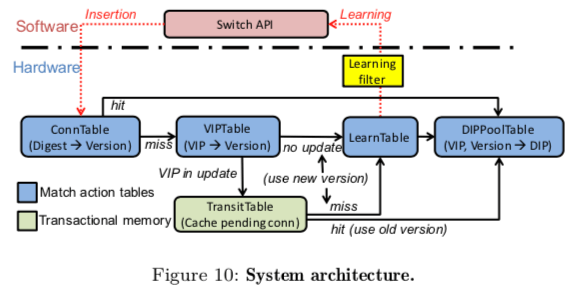
0x21 Scaling to Millions of Connections
为了将数百万的连接的信息保存到几十MB的内存中,下面的图中表示了SilkRoad的这部分的一个设计。ConnTable中不会实际保存连接信息的5-Tuple,而是只保存了一个16bits的Hash值。这样就可以将几十bytes的信息压缩到2bytes。这样带来一个问题就是会存在的Hash冲突,这里Hash冲突的可能性大约为0.01%。SilkRoad使用多级匹配的方式来处理Hash冲突。为了识别存在Hash冲突,SilkRoad利用了连接的SYN包,在收到了一个SYN包的时候,如果发现对应位置的Hash槽以及存在了数据,就得将这个数据和之前存的数据都移入到下一个Stage,然后使用不同的Hash函数来消解这里的冲突。如果发生冲突,会增加几个毫秒的时间来处理。
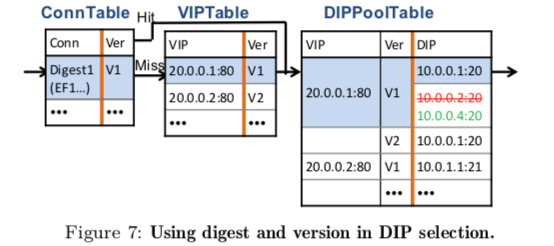
另外一个压缩空间的就是VIP到DIP的映射,这里使用带版本信息的DIP Pool来保存映射关系,而不是直接保存DIP,用于减少需要保存数据的数量。每次这个DIP Pool更新的时候,都是创建一个新的Pool,前面的Pool在没有连接使用的时候就可以回收。SilkRaod认为这里使用一个6bit的版本信息就可以满足要求,
.. Since we introduce another level of indirection (pool version between connections and DIPs), we maintain the version-to-pool mappings in a new table called DIPPoolTable. DIPPoolTable incurs an extra memory consumption to maintain a set of multiple (active) DIP pools for each VIP.
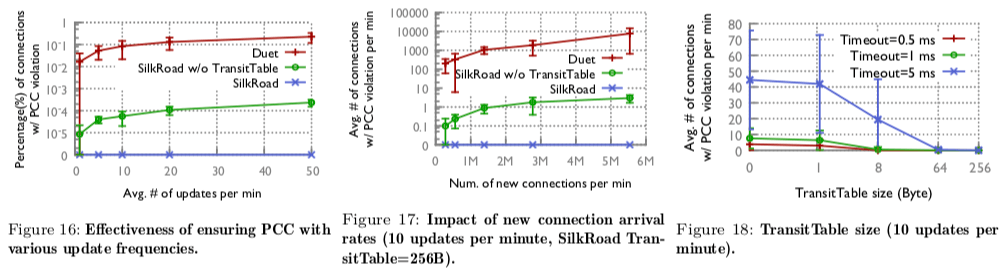
0x22 Ensuring Per-Connection Consistency
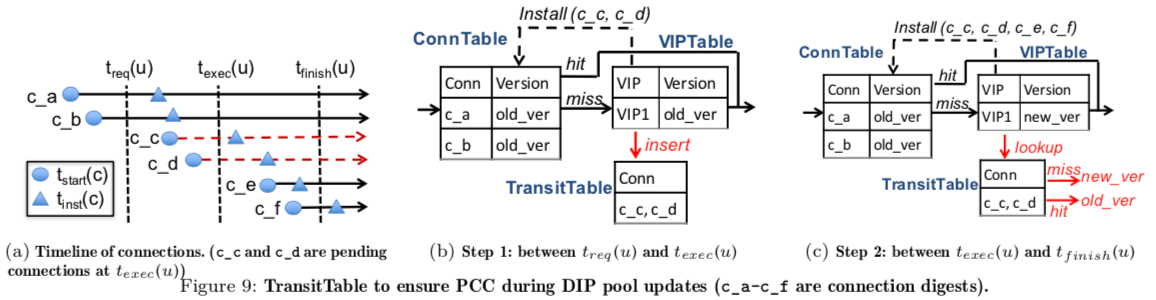
这里要处理的问题就是在更新ConnTable的是,还没有等更新完成,新连接的已经达到了几个数据包。SilkRoad这里使用一个TransitTable来处理这个问题。TransitTable实际上就是一个Bloom Filter。这里的操作分为3步:
-
交换机在收到了一个DIP Pool更新的请求之后,将新的连接记录到TransitTable的Bloom Filter中,
-
在 t_req (u)(下面的图)之前到达的所有连接都添加到了ConnTable中之后, SilkRoad停止更新TransitTable, 并在 VIPTable 上执行update(texec (u))。这个操作完成之后, 在ConnTable中查找缺失的数据包来根据TransitTable中的信息决定使用旧的版本还是新的版本,
.. When all the connections that arrive before t_req(u) get inserted in ConnTable, we stop updating the bloom filter and execute the update(texec(u)) on VIPTable. After the update, all the packets that miss ConnTable retrieve both old and new versions from VIPTable and then are checked by TransitTable to see if the packets hit the bloom filter. If hit, they use the old version; if miss they use the new version. Note that the bloom filter is read-only in this step while it was write-only in the first step (Figure 9c). -
TransitTable中的连接信息都添加到ConnTable之后,清除TransitTable,结束操作。
0x23 评估
这里的详细信息可以参看[3],
参考
- Ananta: Cloud Scale Load Balancing, SIGCOMM’ 13.
- Duet: Cloud Scale Load Balancing with Hardware and Software, SIGCOMM’ 14.
- SilkRoad: Making Stateful Layer-4 Load Balancing Fast and Cheap Using Switching ASICs, SIGCOMM’ 17.
