Large-Scale Cluster Management at Google with Borg
0x00 引言
Google的Borg是很有名的集群调度系统。Borg在Google内部应用应该是有很长的一段时间了,而这篇Paper发表在2015年。Borg虽然是一个很著名的集群调度系统,本身也是十分出色,但是这篇文章看起是平平无奇的,Borg中估计还有很多关键的东西没有写出来,这里只是一个总体上面的表述而已,
It supports high-availability applications with runtime features that minimize fault-recovery time, and scheduling policies that reduce the probability of correlated failures. Borg simplifies life for its users by offering a declarative job specification language, name service integration, real-time job monitoring, and tools to analyze and simulate system behavior.
0x01 用户角度
Borg的用户就是开发者和SRE这群人了。在他们的眼里,Borg就是一个提高了一些接口的一个机器的集群,这里将一个Borg部署的一个实例称之为一个Cell。他们要关系的是关于Borg的这样的一些东西,
-
工作负载。Borg作为Google使用的大型的集群管理系统,当然就会在其至少运行各种各样的负载(heterogeneous)。包括运行时间很长or很短、多消耗CPU or 网络 or 磁盘等。这些不同特点的工作负责也是Borg处理它们优先级的一个核心的参考依据。比如Borg会将长时间运行的服务赋予一个高的优先级,而对于后台批处理的任务赋予一个较低的优先级。
-
Jobs and Tasks。Job是用户要进行一系列的操作,有Task组成。在Borg中,Task为最小的调度单位,一个Task会对应到一组的Linux进程,运行在一个Contrainer或者是一个虚拟机中。它的特性包含了对内存,CPU,网络和磁盘上面的需求。这些特性一般有这个Job的一些特性定义,但是用户也可以指定某个任务的一些特性,
Most task properties are the same across all tasks in a job, but can be overridden – e.g., to provide task-specific command-line flags. Each resource dimension (CPU cores, RAM, disk space, disk access rate, TCP ports,2 etc.) is specified independently at fine granularity; we don’t impose fixed-sized buckets or slots.一个Job、Task会尽力一个提交、等待然后运行最后完成操作(或者是被kill、机制故障等其它的原因)之后死亡的过程。运行处于运行中的操作可以被evit,重新回到等待的状态。另外由于某些原因无法正常执行的操作可以被系统重新执行。
-
Alloc。Alloc是一种Borg中预留资源的一种概率,为未来的任务预留,而Alloc Set和Alloc之间的的关系和Job和Task之间的关系是一样的。
-
没一个任务都会有一个优先级。在需要的时候,高优先级的任务可以强制低优先级的资源,即使可会造成这个低优先级的任务执行失败。另外的一个相关的概念就是Quota,即表示分配给一个任务的各种资源,包含CPU、内存和磁盘网络等等。如何实现这些资源的最大化使用也是Borg一个核心的内容之一,
... We respond to this by over-selling quota at lower-priority levels: every user has infinite quota at priority zero, although this is frequently hard to exercise because resources are over- subscribed. A low-priority job may be admitted but remain pending (unscheduled) due to insufficient resources. -
另外,为了很好地追踪一个Job的运行或者是找到一个运行中的任务,Borg提供了Naming 和 Monitoring的机制。
0x02 基本架构
Borg是一个中心化的架构,这个中心不放就是BorgMaster。Google的很多系统都喜欢采用这样的一个架构。BorgMaster的组成可以从下图中看出,它有两个部分,一个是负责处理用户请求、管理运行中的Job和Task的Borgmaster部分,另外一个就是Scheduler,这两个部分在运行的时候作为一个单独的进行。BorgMasster在逻辑是单个的,为了保证可用性,这里会使用一个基于Paxos协议的5副本保存的方式。另外BorgMaster还会checkpoint的机制来保证系统的快速恢复以及实现一个快照的功能。
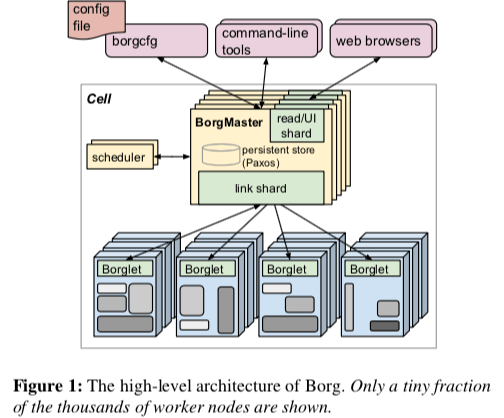
Scheduling
Scheduler是决定一个集群调度器好坏的一个很核心的一个东西,Scheduler决定了一个Task会在哪里运行。一个客户端提交的任务会被BorgMaster保存到一个等待队列中,Scheduler会异步扫描这个队列。Scheduler的操作主要分为两步,feasibility checking用于查找那一台机器提供的资源可以满足这个任务运行资源的要求,这里的资源也会考虑到比这个任务低优先级的可以被这个任务驱逐而获取的部分,另外一个操作就是scoring,挑选其中一个可行的机器来运行。这里的策略对一个Scheduler的好坏写的十分重要,Borg论文这里只是简单地描述了这里的策略。
Borg在之前使用的是一种E-PVM的策略,基本的思路是根据不同的资源情况打出一个分,任务放置的时候尝试使得开销最小话。这种策略类似于内存分配中的最差适配的策略,这样的缺点也是这个内存分配策略一样,会导致很多的“小资源”无法被充分利用。另外一个对应的策略就是最佳适应的方法。这个策略的缺点是不利于负载突增的问题,另外就是批处理任务不适和的问题。Borg这里使用的实际上是一种混合的策略,
Our current scoring model is a hybrid one that tries to reduce the amount of stranded resources – ones that cannot be used because another resource on the machine is fully allocated. It provides about 3–5% better packing efficiency than best fit for our workloads.
另外关于Borg的另外的几点,
-
另外,在执行任务的服务器上面运行的叫做Borglet,它负责运行机器上面的一些问题,比如启动和终止Tasks,在需要的时候重启Task。
-
关于BorgMaster的可用性,在Paper中说可以实现99.99%的可用性,
Borgmaster uses a combination of techniques that enable it to achieve 99.99% availability in practice: replication for machine failures; admission control to avoid overload; and deploying instances using simple, low-level tools to minimize external dependencies. -
Borg提高资源利用率的一些策略也是很有意思。包含,1. Cell共享使用,运行不同类型策略,2. 使用更大的Cell,3. 细粒度优化资源的分配,4. 回收某些资源等等。
-
在隔离性上,Google自己对Linux也做了很多优化。另外Google好像有一篇关于性能隔离的一篇Paper。
0x04 评估
这里的具体信息可以参看[1],
参考
- Large-scale cluster management at Google with Borg, EuroSys’15.
