CONGA: Distributed Congestion-Aware Load Balancing for Datacenters
0x00 引言
CONGA是数据中心内的一个负载均衡方法。CONGA基于去中心化的设计,也不基于主机的一些操作,而是完全在网络中完成。CONGA任务基于每个流后者是每个数据包都存在不少的问题,前者灵活性太差,后者可能导致一些包重拍序二降低传输的性能,因此CONGA使用了基于Flowlet的方式,
... In testbed experiments, CONGA has 5× better flow completion times than ECMP even with a single link failure and achieves 2–8× better throughput than MPTCP in Incast scenarios.
0x01 基本思路
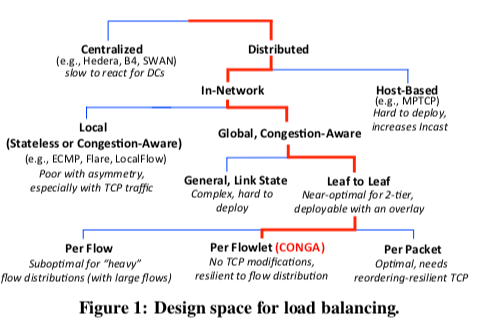
CONGA的设计思路体现在下面的这张图中,
-
使用分布式的架构师CONGA任务中心化的设计难以快速响应数据中心网络内流量的快速变化,另外数据中心网络的拓扑是很规整的,分布式的决策就能获取非常好的效果。
-
In-Network。在使用了分布式的架构后,CONGA选择在网络中实现这个负载均衡的逻辑,CONGA认为网络中心内主机系统的多样性给在Host上面实现带来不便。
-
Global Congestion Awareness,意识到全局的拥塞信息能够带来更好的负载均衡的效果。只利用局部的信息,加上局部贪心的算法在一些情况下做作出不合理的决策。
-
Leaf-to-Leaf Feedback,Lead-to-Leaf指的就是一个Leaf的交换机另外一个交换机反馈网络的一些信息。
-
Flowlet的设计,是在Flow和Packet中间的一个折中的设计,能够避免一些包重拍序的情况下能够比较好的灵活性。
实现
CONGA的实现需要一些硬件层面的支持,
-
CONGA利用了VXLAN来实现它的包格式,相关一些主要字段包括,1. LBTag,用于决定这个包的上行路线,另外就是接受方用于收集拥塞的信息;2. CE,用于交换机在这里带上拥塞的信息;3. FB_LBTag and FB_Metric,用于接受方的Leaf交换机反馈拥塞的信息。
-
CONGA使用Discounting Rate Estimator (DRE)算法估计链路的负载。它保存一个值X,这个值会随着经过数据的比特数来增加,会随着时间周期性的以一个比例减少。然后根据这个是和链路的速度情况来估算拥塞的情况,
... more precisely, if the traffic rate is R,then X ≈ R·τ, where τ = T_dre/α. The DRE algorithm is essentially a first-order low pass filter applied to packet arrivals, with a (1 − e^−1) rise time of τ. The congestion metric for the link is obtained by quantizing X/Cτ to 3 bits (C is the link speed). -
拥塞信息会有目的端Lead的交换机反馈给源端的交换机。这里通过前面提到的包里面的字段。到这里可以看出CONGA的工作模式和DCTCP的模式类似。
-
负载均衡的决策是在一个Flowlet的第一个的包就决定了的。Flowlet的信息会保存在Leaf交换机内。
... For a new flowlet, we pick the uplink port that minimizes the maximum of the local metric (from the local DREs) and the remote metric (from the Congestion-To-Leaf Table). If multiple uplinks are equally good, one is chosen at random with preference given to the port cached in the (invalid) entry in the Flowlet Table; -
在CONGA的一些参数设置中,在Paper中的测试环境下吗选择了,
Overall, we have found CONGA’s performance to be fairly robustwith: Q = 3 to 6,τ = 100μs to 500μs,and T_fl = 300μs to 1ms. The default parameter values for our implementation are: Q=3,τ =160μs, and T_fl =500μs.
0x02 评估
这里的具体信息可以参看[1],
Presto: Edge-based Load Balancing for Fast Datacenter Networks
0x10 引言
Presto同样是数据中心内部的一个负载均衡的机制。Presto主要包含了两点,1. 将负载均衡的逻辑导致soft network edge(不知道怎么翻译才好),比如虚拟交换机如OpenvSwtich之类的,这样就是不需要对网络本身以及主机部分进行修改了,2. 另外一个就是负载均衡的粒度为flowcells。
0x11 基本思路
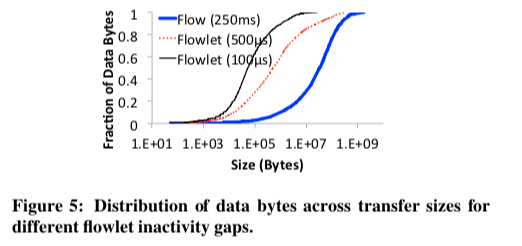
Presto一个关键的idea就是将负载均衡的逻辑放到了类似vSwitch之类的软件之中。另外在负载均衡的粒度上面,Presto选择了一种flowcell的概念。在之前的一些类似的系统中,基于Packet or Flowlet是常见的策略。基于Packet的缺点就是重新排序的问题,另外在Presto认为每个Packet都需要进行某些操作是不利于性能的。在另外的一种基于Flowlet的方式中,它使用了一段时间的粒度。Presto认为这样的策略单来的问题就是Flowlet传输的实际的数据相差比较大,
... Using a smaller inactivity timer, such 100μs, helps (90% of flowlet sizes are 114KB or less), but does not prevent a long tail: 0.1% of flowlets are larger than 1 MB, with the largest ranging from 2.1-20.5 MB. Collisions on large flowlet sizes can lead to congestion.
Presto这里提出了使用Flowcell的方式,基本思路就是将流划分为一定大小的数据单元,比如64KB。这样做有几个优点,一个是TCP Segment Offload(TSO)机制在NIC和主机之间传输数据的Segment大小也是大概是64KB,这样能更好地利用硬件的这些特性。另外就是能够保证避免重拍序。在另外的一些设计策略中,比如选择每一条的层面做负载均衡还是端到端的级别上面做负载均衡,Presto选择了后者。
设计
Presto使用一个中心化的设计,存在一个中心的Controller收集网络的拓扑的信息和负载的信息,这个Controller会将这个信息发送给vSwitch之类的Soft Edge用于作出负载均衡的决策。这个Controller会将网络划分为若干的Spanning Tree,
TODO…….
0x12 评估
这里的具体信息可以参看[2],
HULA: Scalable Load Balancing Using Programmable Data Planes
0x20 引言
HULA的对比的对象就是前面的CONGA。HULA在CONGA的基础做了以下的几点优化,1. 使用每一个交换机选择到目的最佳的路线取代CONGA有Leaf交换机的方式,2. 使用可编程交换机和P4之类的编程语言来实现,这样就不需要特殊的硬件,
... We evaluate HULA extensively in simulation, showing that it outperforms a scalable extension to CONGA in average flow completion time (1.6× at 50% load, 3× at 90% load).
0x21 基本思路
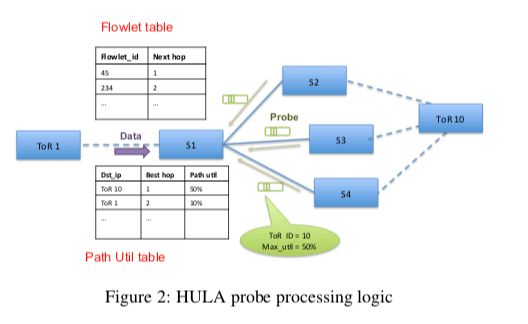
HULA通过类似广播的一种方式来发送一种探针来获取链路利用率的信息。下图中是Paper举的一个例子。这个Probe的数据包会有ToR交换机发送,比如下图中的T1, 汇聚层的交换机接受到这些数据包之后,会广播这个Probe到其它的与它相连的ToR交换机以及上面的Spine交换机,Spine交换机会将其广播到其它的地方。这个Probe数据保护的两个主要的字段是,1. torID,表明这个Probe数据包的来源,2. minUtil,数据到去这个ToR交换机最小的利用。这里HULA的基本思路就是通过一步步地选择一个最佳的路线来让其它的交换机达到某个ToR交换机的最优路径。HULA这样的设计的一个缺点就是带来的而外的Probe的流量,这里会存在这样的一个Tradeoff,Probe太频繁带来的额外的流量态度,频率太低可能造成交换机了解的链路的利用率和实际的有较大差别。
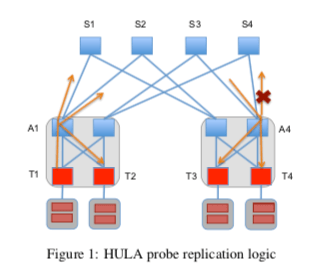
这些信息会被交换机保存,用于后面的最佳路径的选择。这样的方法可以看作是一种贪心的方法,在前面的CONGA认为这样的方法可能导致非最佳的决策,但是HULA认为这个可能性虽然存在,但是在实际的情况下,这种方式表现得非常好。
... However, we observe that this suboptimal choice can only be transient and will eventually converge to the best choice within a few windows of probe circulation. This approximation also reduces the amount of state maintained per destination from the order of number of neighboring hops to just one hop entry.
0x22 评估
这里的详细信息可以参看[3],
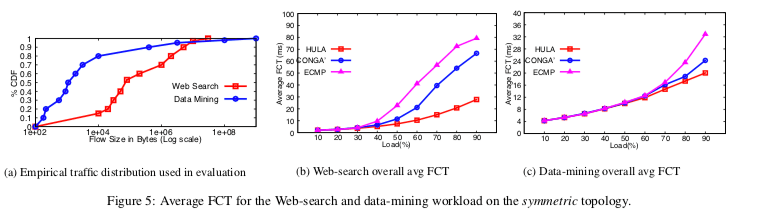
DRILL: Micro Load Balancing for Low-latency Data Center Networks
0x30 引言
DRILL也是一种数据中内部负载均衡器的一种实现。DRILL存在这样的一些特点,第一个就是它对于每一个包作出单独的决策,这个策略在前面的几篇Paper中认为基于每一个包的决策不是很好的方法,可能导致一些包乱序的问题。但是DRILL认为在现在的数据中心网络中这个不会是很严重的问题,特别是在有很好的对称性的网络拓扑中。既是在非对称的网络拓扑中,DRILL也有对应的处理策略,
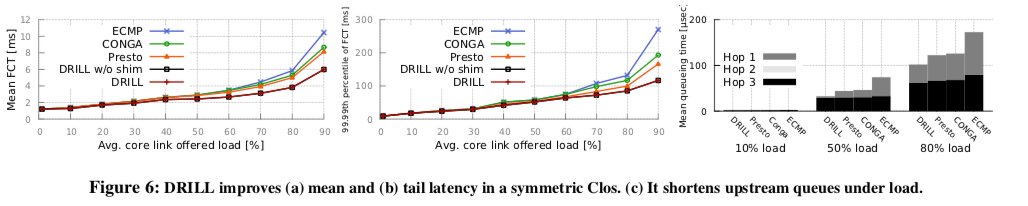
... In simulations with a detailed switch hardware model and realistic workloads, DRILL outperforms recent edge-based load balancers, particularly under heavy load. Under 80% load, for example, it achieves 1.3-1.4× lower mean flow completion time than recent proposals, primarily due to shorter upstream queues.
0x31 基本思路
DRILL的一个设计思路是Equal Split Fluid(ESF),即一个交换机存在n条到达一个目的地的线路,DRILL会尽量让每一条线程发送1/n的流量。emmm,虽然DRILL的Paper中这里讲了一大堆的东西也看不出和DRILL采用的负载均衡的策略有什么直接的联系。DRILL基本的策略是基于交换机本地队列的排队的情况和一些随机方法。也就是说它使用的是一种基于本地信息的一种方法,按照前面CONGA的思路,CONGA认为这样的方法做出的决策可能是非最佳的,这里的几篇Paper都是各自有各自的说法。
... In the spectrum of strictly load-oblivious schemes (ECMP, Presto) to globally load-aware schemes (CONGA), DRILL occupies middle ground: it retains most of the simplicity and scalability of the first class, but leverages a small amount of additional local load information and negligible amount of state independent of the number of flows to achieve better performance than the state of the art in either class.
在DRILL中,DRILL(d,m)的操作表示每个数据到达的时候,随机从N个可行的出端口选择d个,m表示从前面的m次取样中得到的负载最小的端口,DRILL就根据这些信息来决定一个包的转发。参数d和m的选择对DRILL的性能是至关重要的。
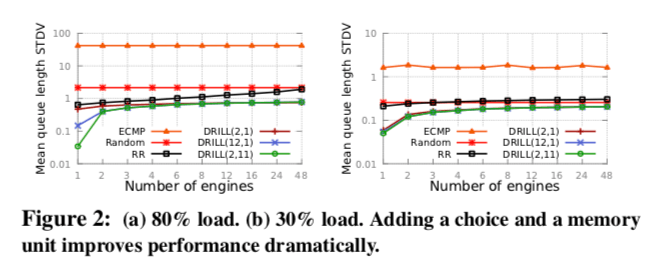
这个策略是对于对称的网络拓扑来说的,对于非对称的,DRILL还爱需要其它的一些策略。emmmmm,真佩服这些人这么会写论文。
0x32 评估
这里的信息可以参看[4],
参考
- CONGA: Distributed Congestion-Aware Load Balancing for Datacenters, SIGCOMM ‘14.
- Presto: Edge-based Load Balancing for Fast Datacenter Networks, SIGCOMM ‘15.
- HULA: Scalable Load Balancing Using Programmable Data Planes, SOSR ‘16.
- DRILL: Micro Load Balancing for Low-latency Data Center Networks, SIGCOMM ‘17.
