Calvin: Fast Distributed Transactions for Partitioned Database Systems
0x00 引言
Calvin是分布式数据库的一种设计,发表的年份和Spanner的相同。Calcin也有一个开源的实现。Calvin和Spanner是一种完全不同的设计。Calvin是一种的确定性的数据库(deterministic database)。在传统的数据库实现中,简单地复制事务的输入并不能保证不同的副本最终达到一个完全一致的状态(可能由于操作系统、网络以及硬件等带来的不确定性)。而类似Calvin的数据库通过在并发控制中达成一个一致的请求锁的顺序,则可以保证副本之间达到一个一致的状态,
... if the concur- rency control layer of the database is modified to acquire locks in the order of the agreed upon transactional input (and several other minor modifications to the database are made ), all replicas can be made to emulate the same serial execution order, and database state can be guaranteed not to diverge3.
0x01 基本架构
Calvin为一个3层的设计,
- Sequencing层,为事务安排一个全局的顺序,并会将这些事务及其顺序的信息复制到不同的副本上面。
- Scheduling等,使用一个deterministic locking的模式来保证事务的执行满足Sequening安排的顺序时,还能够多线程处理。
- Storage层,这一层并不是Calvin设计的重点,提供基本的CRUD接口的存储系统都可以应用到Calcin的这一层。
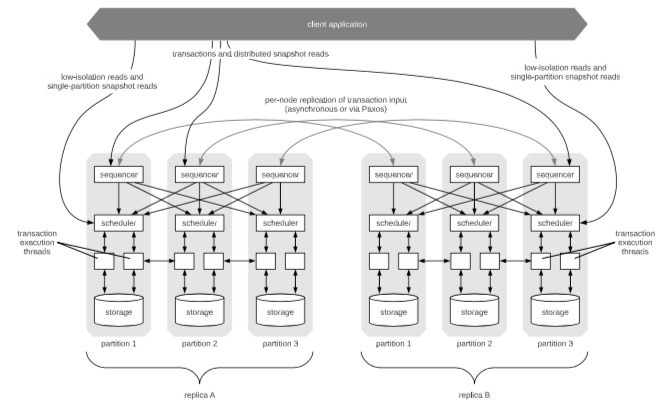
Sequencer和复制
Calvin的Sequencing层也是一个有多个副本、分区的设计。Calvin将时间划分为10ms的Epoch。一个Sequencer节点在一个Epoch里面请求的事务处理为一个Batch。之后这个Batch会被复制。这里Batch里面还会包含唯一表示这个Sequencer的ID、Epoch Number以及事务的输入。之后这些数据会被复制到其它的副本上面,这里可以选择异步复制或者是基于Paxos的复制方法,
Scheduler和并发控制
为了提高一个节点上面事务处理的速度的同时有保证Calvin的deterministic的特性,Calvin使用量一种deterministic lock的方式。既是事务会访问不同节点上面的数据,单个节点上面的Scheduler也只会负责处理这个节点上面数据记录的锁。Calvin的deterministic的lock protocol类似于严格的两阶段锁协议,但是有两个变化,
- 如果两个事务A、B请求同一个记录的锁,而且A出现在B之前,那么A必须在B之前请求这个记录上面的锁。在Calvin的实现中,这里就是使用单线程请求锁的方式实现的。
- Lock管理器必须保证授予一个锁的时候满足事务请求锁的顺序。同样的A和B的例子,也就是说B被授予一个锁的时候必须保证A以及请求了这个锁而且已经释放了。
由于Calvin每一个节点只会处理自身节点上面数据的锁,所以这个Lock管理器应该就是Sschduler层的一部分,每个节点都会有这个一个管理器。在Calvin中,一个事务的执行分为5个步骤,
- 分析读/写的数据集合,事务开始处理的阶段就是分析事务会读取/写入那些数据。根据会参与到这个事务中的节点是否是会写入数据还是只会读取数据将节点分为active participants和passive participants。
- 执行本地读取,即读取本地节点上面这个事务进行的时候需要读取的数据。
- 处理远程读取,本地读取的数据会发送给其它的参与到这个事务中的active participants。
- 收集远程读取结果,如果一个节点是active participants,它也还是等到其它节点上面的读取的结果发送过来。
- 事务处理以及数据写入,在收到了所有的读取数据之后,这个active participants就可以处理事务的逻辑了。事务处理的结果之后将要保存到本地的数据写入,非保存到本地的数据会直接忽略。即每个节点只需要保存自己的即可。
另外,为了处理依赖事务的问题,Calvin使用了一种Optimistic Lock Location Prediction (OLLP)的方法,即在事务处理之前,只写一个reconnaissance query,用于发现事务会read/write记录的集合。由于这两个集合可能在之后被修改,所有在后面会重新检查。Calvin的Failover的处理由于两点变得简单:1. Calvin中,一个节点故障之后,客户端可以直接转向另外一个副本来处理,2. 事务的输入有在前面被logged了,这样写入的时候就必须要physical REDO logging。同样地,Calvin也会引入数据库常见的Chaeckpointing方法,
... Calvin supports three checkpointing modes: naive synchronous checkpointing, an asynchronous variation of Cao et al.’s Zig-Zag algorithm, and an asynchronous snapshot mode that is supported only when the storage layer supports full multiversioning.
0x02 评估
这里的具体的信息可以参看[1],
CalvinFS: Consistent WAN Replication and Scalable Metadata Management for Distributed File Systems
0x10 引言
CalvinFS也是一个利用NewSQL保存元数据的一个分布式文件系统。CavvinFS的基本架构和GFS的架构类似,主要不同在于CalvinFS的文件系统保存到一个Calvin数据库的一个实例中。
0x11 基本设计
Block Store
CalvinFS也是将文件拆分为Block保存,不同的是CalvinFS中,Block的大小是变长的,可以有1bytes到10M bytes。同样地,CalvinFS中的Block也是不可变的。CalvinFS中的Block也会赋予一个唯一的ID,会保存到类似GFS中ChunkServers中的节点中,这些块和保存Block节点之间的映射关系保存到一个基于Paxos算法的系统中。Block Store的设计不是CalvinFS设计的重点。
源数据管理
Calvin文件的元数据也是包含了文件类型(文件夹、文件)、权限和文件Block等的信息。由于Calvin的Block的大小是变化的,元数据中Block的信息还会保含这个块为这个文件的那个区间。这些数据保存到一个分布式的数据库中解决了HDFS中元数据保存到内存中的一些限制。可大可小的数据块也优化了在小文件上的一些表现。元数据层的操作和一般的文件系统的操作没有很大的区别,
• Read(path)
• Create{File,Dir}(path)
• Resize(path, size)
• Write(path, file offset, source, source offset, num bytes)
• Delete(path)
• Edit permissions(path, permissions)
CalvinFS中目录上面的递归式的处理利用了Calvin中的OLLP的机制。对一个文件创建并写入少量数据的操作,在CalvinFS中,
-
客户端会首先写入文件的数据。客户端先从一个Block Server请求一个全局为一个ID,之后根据这些ID找到所属的Bucket。但写入足够数据的副本的时候,这个操作可以视为完成了。
-
在CalvinFS中,一个文件创建的操作会分为3步,
• create file /home/calvin/fly.py • resize the file to Len bytes. • writeβ:[0,Len)to byte range [0,Len) of the file这些操作必须包含在一个事务中处理。在应用这些操作前,CalvinFS会将其写入到Log中。
0x13 评估
这里的具体的信息可以参看[2],
参考
- Calvin: Fast Distributed Transactions for Partitioned Database Systems, SIGMOD’12.
- CalvinFS: Consistent WAN Replication and Scalable Metadata Management for Distributed File Systems, FAST ‘15.
