Canopy: An End-to-End Performance Tracing And Analysis System
0x00 引言
Canopy是Facebook使用的一个分布式追踪的基础设施。这篇Paper发表在SOSP ‘17上面。在前面的OSDI ‘14上面,Facebook也发表了The Mystery Machine的论文,也是类似的分布式追踪系统。这个Canopy应该就是The Mystery Machine系统的继续演进,Canopy实现了更加丰富强大的功能,
Canopy addresses three challenges we have encountered in scaling performance analysis: supporting the range of execution and performance models used by different components of the Facebook stack; supporting interactive ad-hoc analysis of performance data; and enabling deep customization by users, from sampling traces to extracting and visualizing features.
0x01 案例
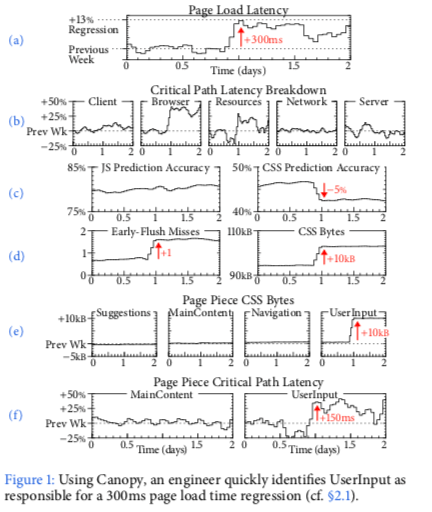
Paper中讲了一个Facebook页面的响应时间突然增加了300ms为例子,通过Canopy最终找到其原因。在Facebook的应用,一个页面通常有很多的部分组成,这些组件称之为page pieces,这个组件由不同的部分开发。这些响应时间的监控会有Canopy实时监控,这些监控数据包含页面响应时间在那的诸多的参数。在图b中,Canopy利用了Critical Path的概念监控了这些部分资源加载用的时间。Canopy可以支持 threads, events, continuations, queues和RPCs多种的执行模型。在图b来看,浏览器上耗费的时间和资源加载的时间出现了明显的增产,而其它部分的耗费的时间没有出现明显的变化,这样就缩小了排查的范围。在图c和图d中更加精确地说明了情况,JS资源没有变化,但CSS Predicate准确率。不过Early-Flush Miss增加了一次,从而引起多加载了10KB的CSS资源。这里确定了资源方面的性能信息,为了定位问题,这里有显示了图e的page pieces的信息,发现资源加载的增产增加在User Input的page pieces,从而发现了这个是由于User Input这个模型新增加的功能但是没有被Early Flush加入从而导致的。这里的Early Flush值Facebook使用的一种信念优化策略,通过讲客户端想要的资源批量发送给客户端,从今提高性能,这里新增加的资源没有被识别到客户端想要的资源集合中去,从而想要另外单独加载,就导致了页面加载延迟增加的问题。
0x02 基本架构
Canopy的基本思路还是沿用了Dapper中利用TraceID追踪调用链,利用Span的概念来策略一个操作的耗时等。Canopu工作的流程一般如下,
- 工程师使用Canopy提供的instrument API来使用Canopy,来记录其所需要的性能信息。在系统运行的时候,用户的请求会经过这些添加了instrument操作的系统。Canopy会赋予每一个请求一个唯一的ID,这个ID会一直随着这个用户请求传播,这里的基本的思路和方式和Google的Dapper是一样的。在一个instrumentation被触发的时候,Canopy产生一个事件,来记录其获得到的性能信息,也会记录前后事务的因果关系。
- Canopy讲这些事件路由发送到称之为tailer的组件,这些记录的数据会根据traceID来分片。在接受到这些信息之后,tailor讲这些信息聚合到其内存之中,也会持久化保存这些信息。这里的过程如下面的图a表示。在确定接受到一个请求的所有event之后,这些数据就会排队进行处理。这些trace的数据会被转化为trace model。这个model是一个trace信息的high level的表示(具体是什么表示???)。接下来这些数据会被应用到用户提供到的一个feature lambda上面,这里应该就是一些用户提供的简单的计算逻辑。之后这些形成的dataset会被保存到Scuba中,之后用户可以对其进行查询。
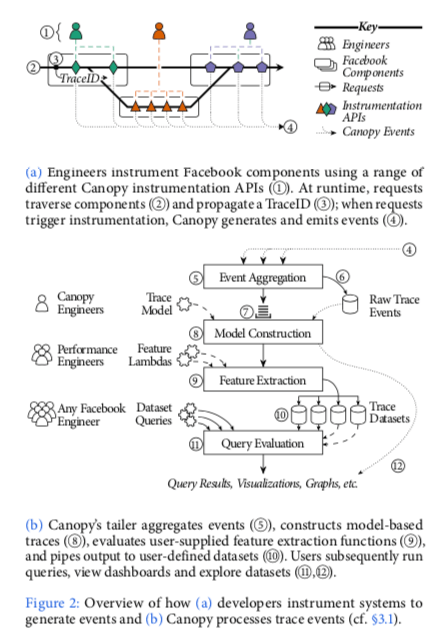
从上面Canopy执行的基本流程来看,这里涉及到了Canopy中基本组件or概念,
-
Instrument APIs为用户直接使用的部分,它主要负责三个功能,一个在运行时传递traceID,这个ID把不同部分的性能数据联系起来。另外一个是记录请求的一些信息,包括那里,什么时候执行了这个请求,线程、组件以及网络通信之间的因果先后关系。最后一个就是记录需要的性能数据。Canopy为不同的编程语言开发了Instrument的API,不同的编程语言也存在一些差别,这些差别主要值编程语言不同的特性造成的。一个段程序逻辑可以有一个开始标记和一个结束标记,
// Java try (Block b = Canopy.block(“Doing some work”)) { . . . } // PHP Canopy()->inform(‘Evicting Cache Entry’); Canopy()->measure(‘Evicting’, $evictFunction); -
为了支持多种的Trace Model,这里Canopy引入了一个更加基础概念event。在一个instrumentation触发的时候,它会产生和发送一个event,利用会记录一些数据,包含性能数据,因果关系的数据等。一个event的thrift的IDL表示如下,
struct Event { 1: required string traceID; 2: required string type; 3: required string id1; 4: optional string id2; 5: optional i64 sequenceNumber; 6: required i64 timestamp; 7: optional map<string,string> annotations; }记录一些数据,instrumentation库可能产生多个event的数据,这些数据可以被组合起来。Canopy在一个线程or进程之内,使用sequnence number和时间戳来确定不同事件之间的先后关系。另外Canopy在使用一个随机的random ID来关联同样概念的event。这里举了一个例子,为了追踪进程间操作的因果关系,会在发送端产生EventID,即RandomID,EventID会被记录下来,这些数据会被和请求一起发送到接受方,接收方也会记录这个EventID。Event中的type字段是一个可以拓展的字段,这里定义了不同Event的类型。以后可以随时添加用于功能拓展,
New instrumentation libraries can reuse existing com- mon event types or define new ones; we currently define 22 event types. This loose coupling is important for compatibility, since a single trace will cross through multiple services that must inter-operate across different instrumentation library versions. -
Modeled Traces。Modeled Traces是Canopy中更高层次的性能数据表示,这个表示隐藏了底层使用的Events之间的差异,这些差别可能是不同的组件or不同的版本造成的。这些Models目前有这样的一些类型,1. execution units,一个计算任务的高层次抽象的一个表示,大致相当于一个执行的线程,2. Block,一个execution unit中的一段,3. points表示一个block中一个发生的一件事情,4. edges用于表示point之间关系。
-
Trace-derived datasets是Canopy的高层次表示的数据输出。Dataset中的每一行有一个trace中的数据元素组成,
one high level dataset has a row per trace and aggregates statistics such as overall latency, country of origin, browser type, etc; conversely, a dataset for deeper analysis of web requests has one row for each page piece generated by each request, i.e. it is keyed by (TraceID, PagePieceID).Dataset的每一列代表了一个数据指标or其它的一些结构关系。统计计算等操作一般都是在列基本上进行操作的。Canopy使用一个extraction 函数对dataset进行一些操作,这个函数的基本表示:f : Trace -> Collection<Row<Feature»。
0x03 实现
Canopy中的Tailer是进行数据处理的主要场所,基本架构如下图所示。
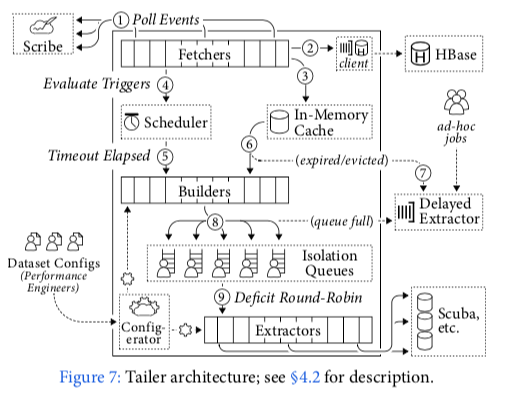
这里很多实现的细节以后在补充
0x04 评估
这里的具体信息可以参看[1],
参考
- Canopy: An End-to-End Performance Tracing And Analysis System, SOSP ’17.
