Fast In-Memory Transaction Processing Using RDMA and HTM
Fast In-Memory Transaction Processing Using RDMA and HTM
0x00 引言
DrTM是上海交大开发的一个基于RDMA和HTM的一个支持分布式内存事务的系统(不过由于DrTM使用的是RDMA,这里的发布和Calvin的分布可能存在比较大的差别,虽然DrTM在这篇paper中性能在和Calvin对比)。这里的事务只的是内存中的一种类型的事务,和一般数据库中事务的概念还是存在一些差别的。
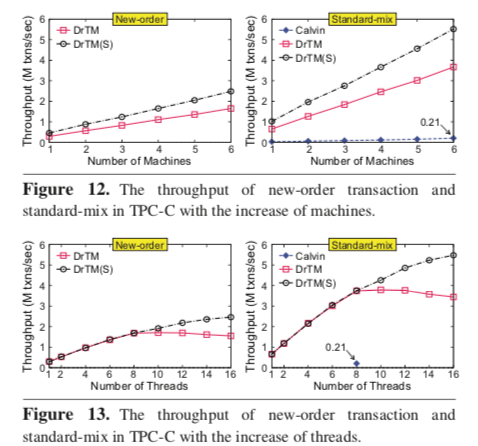
... Evaluation using typical OLTP workloads including TPC-C and SmallBank show that DrTM scales well on a 6-node cluster and achieves over 5.52 and 138 million transactions per second for TPC-C and Small- Bank respectively. This number outperforms a state-of-the-art distributed transaction system (namely Calvin) by at least 17.9X for TPC-C.
0x01 分布式事务
DrTM在单机中使用HTM来实现事务,采用两阶段的锁访问操作原创事务来实现分布式的事务。这里要处理一个问题就是一个HTM中的RDMA操作会导致这个HTM事务无条件的abort。所以这里不能在一个HTM事务中去执行RDMA的操作的。DrTM采用的基本的思路是先讲要操作的其它节点上面的记录保存到本地的一个地方,在本地的HTM执行完毕之后向其它节点提交,如果HTM abort了,则这些数据会被舍弃。因此DrTM采用的是一种HTM和2PL结合实现的方式。DrTM提供的严格可序列化的事务一般分为三步来执行,1. Start阶段,在这个阶段,事务会尝试锁住其它节点上面的记录,并将这戏记录取回来,然后开启一个HTM事务,2. LocalTX阶段,在这个阶段,在本地执行事务化的读写操作,3. Commit阶段,这个阶段首先提交HTM事务,之后更新其它节点上面的数据,然后解锁这些数据。这里DrTM和Calvin一样,也是需要能够提前知道数据的读写集合。这个逻辑伪代码如下,

这样的逻辑还会存在另外的一个问题。这个问题出现在访问其它节点使用2PL机制和本地的节点使用HTM可能出现在同一台机器上面,在一些情况下就可能导致一些数据不正确的行为。比如本地的数据访问在另外一个访问本节点系统的记录之后,这种情况可能导致违反Serializable的行为。在下图的c、d有表示,在这种情况下,本地的HTM事务不会收到其它节点处理这些记录的影响,但是这里将这些数据修改了,之后其它节点上面的事务提交的话就会导致问题。这里DrTM使用一个额外的检查的步骤来解决这个问题。
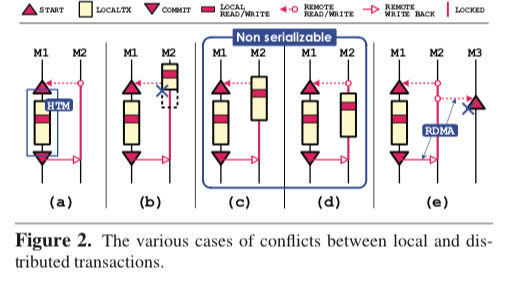
对锁的实现方面,DrTM利用来RDMA提供的一些原子操作的原语。有这些原子操作只支持8byte,DrTM将需要的信息都放入到了一个8byte的数据中,称之为State。一个排他锁会对应这个记录的State字段的一个bit,加速就是一些CAS操作。而对于共享锁,DrTM使用了一种租约的机制,这个租约机制的共享锁只会在分布式事务的时候被使用,而本地的操作就是借助HTM来完成的,但是无论是本地的事务还是远程的事务事务写操作都回去检查这个共享锁的租约,
... All local and remote transactional write will actively check the state of the shared lock and abort itself when the lease is not expired. Further, to ensure the validation of leases up to the commit point, an additional confirmation is inserted into the Commit phase before the commitment of local HTM transaction (i.e., XEND).
事务化读写
DrTM事务化的读写,如果都是远程的读写,都的依赖于记录的state字段。比如在读一个远程记录的时候会先尝试加一个共享锁,尝试加锁的结果根据:1. 加锁是否成功,2. 如果失败释放已经加了写锁,3. 是否已经被其它的事务加了共享锁,根据这些不同的Cases做出不同的处理。另外远程写的时候,也是类似的思路。

而对于本地事务的读写,则要简单不少,这里主要就是利用了HTM。每次本地的读写操作之遥检查锁的情况,如果是被加了写锁,这个事务则需要abort,负责根据读写的不同情况进行处理。对于只读事务的情况,一些只读事务如果它的read-set比较大的话,可能容易造成其它HTM事务的abort,这里DrTM的做法是先尝试对记录加共享锁,记录其中共享锁最小的end-time,在这个步骤完成之后需要对end-time进行校验。
0x02 存储层
DrTM在内存的存储选择的就是一种的Hash Table,采用了一种Cluster Chaining的方法,类似于使用了组相联的Chaining Hash,在此的基础上对RDMA的环境做了一些优化。这里就是这样的几点设计,1. 使用一个字段来表示类型,可以实现内存重用,类似C语言中Union的功能,2. Main Header和InDirect Header配合,它们之间使用偏移寻址,这样就与特定的内存区域无关,3. 使用lossy incarnation表示减少读操作的次数。 这里的Cluster Chaining的设计在另外的一篇Paper[2]中有更加详细一些的描述。Cluster Chaining总体上还是一种Chaining Hash,不过它使用了一个索引,另外索引和数据只分开保存的,这样在对应的Hash槽里面查找数据的时候可以根据索引来减少内存访问的次数。
... The main header and indirect header share the same structure of buckets, each of which contains multiple header slots. The header slot is fixed as 128 bits (16 bytes), consisting of 2-bit type, 14-bit lossy incarnation, 48-bit offset and 64-bit key. The lossy incarnation uses the 14 least significant bits of the full-size incarnation, which is used to detect the liveness of entry.
// 来自论文[2]
在DrTM-KV中,一个Get/Put操作首先通过Hash函数找到key所在的索引部分的bucket。如果在bucket中找到了key,那么可以直接从bucket中的地址读取数据的值。否则,需要遍历下一个bucket中的数据。为了减少每个查询bucket链的次数, DrTM-KV将多个键聚集到一个bucket中,这样有效地减少了链表的长度。将数据和索引分开会造成读取索引内容的不一致问 题,在查找完数据地址到数据读取内容期间,数据的地址可能会被修改。这将导致查找时读取的数据地址和实际数据的位置不对应。DrTM-KV使用一个校验机制使得Get/Put操作可以检测出数据不一致的情况。数据会记录一个额外的校验码,这个校验码也会存储在索引的bucket中。为了节省空间,bucket中只存储校验码的14个bit,通常情况下这样足够检测出不一致的情况。在插入或删除数据时, bucket和数据的校验码会被更新。这样DrTM-KV通过检测校验码是否一致来检测数据是否被删除。
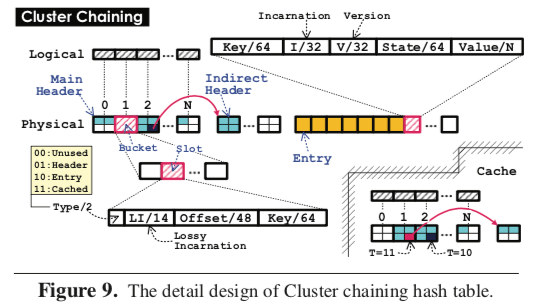
另外这里的Hash Table的设计也关联到啦DrTM Caching的设计。DrTM认为一般的缓存机制直接缓存内容的设计在这里很难保证一致性,所以DrTM采用啦缓存地址的设计。这里解决数据删除等一些问题也是利用了incarnation一些操作。
0x03 其它
另外关于DrTM的Papers还有DrTM+R和DrTM+B,其中主要将的是利用Vertical Paxos实现的一些副本的机制[3],DrTM+B则讲的是利用RDMA做在线的数据迁移的内容[4]。
0x04 评估
这里的具体信息可以参看[1],
参考
- Fast In-Memory Transaction Processing Using RDMA and HTM, TOCS’17.
- 基于RDMA高速网络的高性能分布式系统, Big Data Research,2018。
- Fast and General Distributed Transactions using RDMA and HTM, EuroSys ‘16.
- Replication-driven Live Reconfiguration for Fast Distributed Transaction Processing, ATC ‘17.
Emmmmmmm
