Firmament: Fast, Centralized Cluster Scheduling at Scale
0x00 引言
Firmament也是一个集群调度器的设计,FIrmament的基本思路是对集群的情况进行图建模。在这个图上使用基于最小费用最大流的策略来计算调度方案。中心化的调度器一般能够取得更加好的资源利用率,不过代价就是调度的延迟一般也会相对大一些。基于最小费用最大流的调度思想在SOSP ‘09上面就有一篇Paper,不过这篇SOSP Paper中的实现延迟比较高。这篇Paper提出的Firmament调度器在基本的最小费用最大流的基础之上做了不少的改进,实现了比Quincy高几十倍性能(延迟效果)的效果,
... Experiments with a Google workload trace from a 12,500-machine cluster show that Firmament improves placement latency by 20× over Quincy [22], a prior centralized scheduler using the same MCMF optimization. Moreover, even though Firmament is centralized, it matches the placement latency of distributed schedulers for workloads of short tasks.
常见的集群调度器的架构有三种,
- 中心化的调度器,比如这里的Firmament,以Borg等中心化调度器的优点能够得到更有的调度决策,但是相对地,其调度延迟也会比较高;
- 分布式调度器,比如Sparrow,其基本的特点就是调度的延迟相对很低,但是由于分布式调度器的决策都是基于集群的部分信息来做的,在调度的效果上相对就差一些;
- 混合调度器,结合了前两者的思路,有中心的策略和分布式的策略。根据任务的不同类型来做决策;
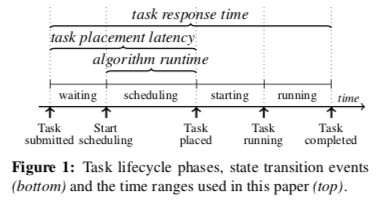
上图表示来一个任务调度过程。常见的调度方式任务的调度是一个个地调度。一个个地调度方缺点是前面的先调度可能导致影响到后面的调度,总体上由于先后而得到了一个不是最佳的调结果,另外一个就是每次都得走全部操作,不能平摊开心。这鞋缺点的一个解决方式就是使用批量的方式,当然批量的方式也有缺点,比如提高延迟等。另外在这个基本的Task的Lifecycle中,Paper有总结了常见的基于队列的调度器和基于Flow的调度器的不同点,

常见的一般为基于队列的方式,而这篇Paper提出的Firmament是基于Flow的方式。
0x01 基本思路
Firmament的基本架构如下图。在有了最小费用最大流的基本思路之后,之后最主要的问题就是如何对集群的情况进行图的建模,并将调度的问题抽象问最小费用最大流求解的问题。
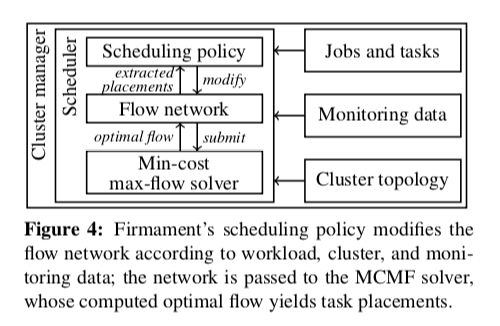
Firmament中一个建模的例子如下图。在Firmament中,一个flow网络是一个有向图。一条边由一个原点直线一个目的点,并拥有一个容量和一个费用值。在下面的图中,有这样的基本节点,1. Ti,j代表了第j个job的第i个task,是这个图中的一个源,2. 一个特殊的节点S,称之为Seek Node,最终沿着这些有向边都会到达S节点。这样的话调度问题就是抽象为从Ti,j出发,以最小费用最大流的方式得到节点S。3. M类型的节点代表了机器,4. U节点则是aggregator node,类似于一个队列,保存暂时没有调度的任务。
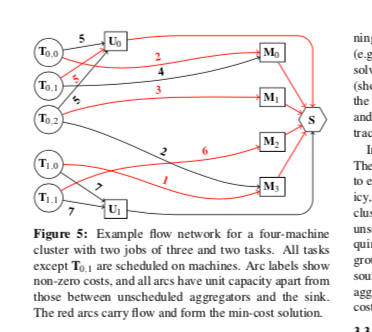
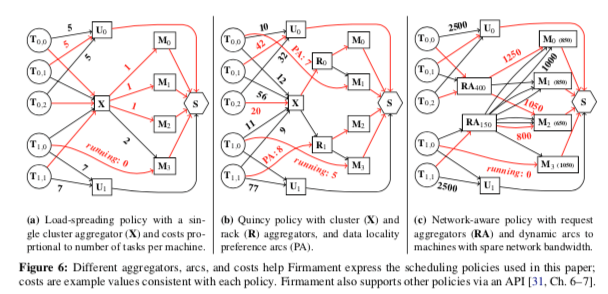
容量和费用都是Firmament来定义,另外加上aggregator node这样的节点。 在这样的基本模型上面,可以抽象出非常大有非常灵活的调度策略,Paper中举了几个例子,
-
Load-Spreading策略,这种策略的基本思路是使用一个整个集群范围的一个aggregator node,即下面左图中的X。每一个task都有一条边和这个X节点连接,另外它和其它的M节点也都有边来连接。边的费用可以根据已经在运行的任务定义。在下左图中,一个任务Ti,0已经在M3上面运行了,然后X到M3的费用就提高了,这样的话后面的任务就更加可能被调度到其它的机器上面,达到了一个类似负载均衡的效果。
-
Quincy策略,来源于前面的论文[2]。在Load-Spreading的基础上面假设了R类型的节点,这里的R表示了机架的意思。这种策略的基本的出发点是将任务调度到靠近数据的地方。这样策略一般适用于批量任务。在存在局部性特点的路径上面(Data Locality),会给这个路一个更低的费用值,
... Tasks have low-cost preference arcs to machines and racks on which they have local data, but fall back to scheduling via the cluster aggregator if their preferences are unavailable (e.g., T0,2). -
Network-aware策略,在这种策略中,映入了称之为request aggregator (RA)的节点。每一个任务都与某个RA节点连接。这个RA节点代表了一种资源的限制,比如网络。通过这样的方式,很好地限制了一个资源的分配,避免了超量分配一些资源。Paper中任务,这样的策略存在做出高质量的决策,但是在实际的资源类型很多的情况下会很复杂,比较难以拓展,
Costs on the arcs to machines are the sum of the request and the currently used bandwidth, which incentivizes balanced utilization. We use this policy to illustrate Firmament’s potential to make highquality decisions, but a production policy would be more complex and extend it with a priority notion and additional resource dimensions
0x02 MCMF算法 和 对于调度和系统实现
在Paper中对比了4中不同的MCMF的求解算法,这个算法在ICPC之类的算法竞赛中也是一个常见的问题。这里就不去具体讨论求解MCMF的算法本身了,
| Algorithm | Worst-case complexity |
|---|---|
| Relaxation | O(M^3CU^2) |
| Cycle canceling | O(NM^2CU) |
| Cost scaling | O(N^2Mlog(NC)) |
| Successive shortest path | O(N^2U log(N)) |
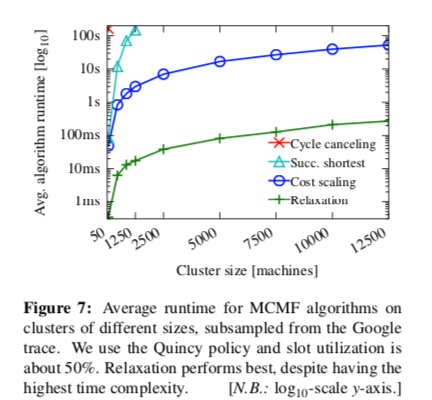
从Paper中测试数据来看,只有第一种和第三种还实际使用的意思,其它的两种实际表现都非常差。在实际的环境中,算法的理论上面的没有很大的参看价值,因为MCMF的算法受图具体的实例影响很大,Paper汇总采用的评估算法在你的方法就是实际测量。另外MCMF的性能受实际输入的具体case影响很大的特点带来的一个问题就是能以决策具体使用哪一个算法。比如在很对情况下都是relaxation有更好的性能,但是在随着集群复杂地增高,这个算法的性能会急剧下降。这里Paper中采用了一种简单粗暴的方式来解决,即上面可行的两种方法并行计算。哪一种方法先计算出结果就使用谁的,
Firmament’s MCMF solver always speculatively executes cost scaling and relaxation, and picks the solution offered by whichever algorithm finishes first. In the common case, this is relaxation; having cost scaling as well guarantees that Firmament’s placement latency does not grow unreasonably large in challenging situations.
处理基本的MCMF算法之外,Paper中还提出了在集群调度这样的环境中,对这样的一些MCMF算法的优化策略,
- Approximate min-cost max-flow,上面的MCMF计算出来的结果都是在模型上面的最优解,但是这种环境下面,不一定就要求解最优解。这里可以使用只求解一些近似最优的解来提高算法的性能。如果算法运行太长的时间,可以提前终止算法的运算。
- Incremental min-cost max-flow,这里的基本思路就是想办法避免每一次都跑一次完整的MCMF算法。通过利用前面的运行能减少这次计算的运算亮。思路虽然简单,不过要具体讨论的话,还是仔细研究算法和这个Firmament的开源代码。
- Problem-specific heuristics,启发式的方法。基本的思路有两个,一个是Arc prioritization,即通过一些额外的信息提示算法应该选择哪条边。这样的话可以剪掉一些边的计算。另外一个就是Efficient task removal,移除task node,这些task node一般由于任务结束、被抢占后者是失败等原因停止运行。通过一处节点减少图的大小。
0x04 评估
这里的具体信息可以参看[1],
参考
- Firmament: Fast, Centralized Cluster Scheduling at Scale, OSDI’16.
- Quincy: fair scheduling for distributed computing clusters, SOSP ‘09.
