DFTL: A Flash Translation Layer Employing Demand-based Selective Caching of Page-level Address Mappings
0x00 引言
前面看过的一些关于FTL的Paper都是Hybrid模式。基本的思路就是使用Block和Page两个层面的映射,这么做的原因是随着SSD容量的不断增长,FTL占用的空越来越多,Block/Page的设计就类似于Page Table的多层的设计。而Hybrif的方法也有一些缺点。一般认为Page-Level的能够实现更加好的性能,容易区分冷热数据以及没有Merge操作。Demand-Based FTL (DFTL) 就是这样的一个Pagel-Level的FTL的设计,
For example, a predominantly random-write dominant I/O trace from an OLTP application running at a large financial institution shows a 78% improvement in average response time (due to a 3-fold reduction in operations of the garbage collector), compared to a state-of-the-art FTL scheme.
0x01 基本思路
DFTL的思路是比较简单的。SSD容量增长之后,整个的Mapping Table不能保存到SSD中的SRAM中。Hybrid的做法是将Mapping Table减小,而DFTL的想法是将放在SRAM中的部分减小。DFTL将大部分的Mapping Table的数据都保存在SSD上面,而只将最频繁被使用的放到DRAM里面。这样看来,DFTL就类似于一个SSD中TLB。而TLB这个已经被研究了很久了(应该可以将TLB中的很多思路应用到这里)。DFTL的基本架构如下图所示。DFTL将SSD中的Page分为保存数据的Page和保存Mapping Table的Page。DFTL将整个的Mapping Table称之为Global Mapping Table,缓存在SDRAM中的称之为Cached Mapping Table (CMT),另外那些保存映射关系的Translation Pages的映射关系保存到一个Global Translation Directory (GTD),GTD一直保存在SRAM中,它占用的空间比较小。这样设计DFTL要解决的问题就是TLB、Cache之类要解决的问题是很类似的:1. 怎么样保证SRAM里面保存的都是热点的映射,2. “脏”数据的写会策略,3. SRAM中的数据替换策略等。
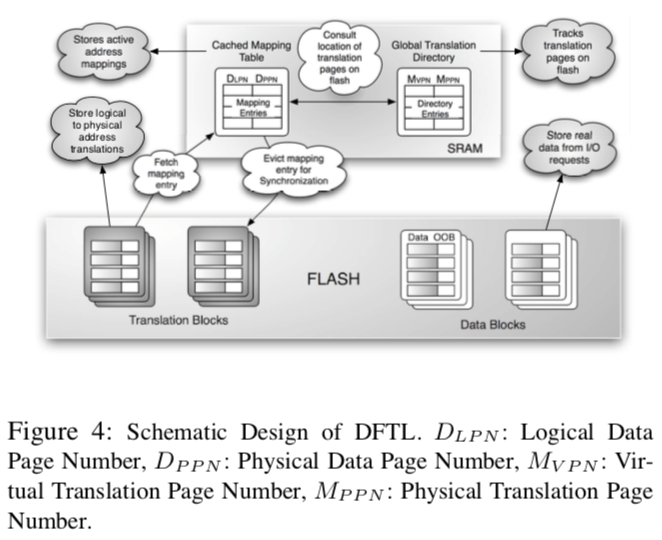
这里DFTL的实现也没有什么和现在的一些类似问题的解决有什么很大不同的地方。一些DFTL中的地址转换操作可以引起三次的Page读写,一次读Mapping Table的数据,获取映射关系,一次为读取数据,另外一次就是写入更新之后的Mapping Table的数据。在垃圾回收方面,它采用了一种基于一个GC-threshold阈值的策略,即可写Page和失效Page之间的一个比例,超过了这个阈值之后,会引发GC操作。对于数据Page的回收操作只要拷贝没有实现的Page,更新Mapping Table,擦除Block即可。而对于Translation Block,还要更新GTD。DFTL使用一些优化的来减少GC的Overhead,比如lazy-copying,即选择已经Cache在SDRAM中的映射部分更新,选择批量操作的方式。
0x02 评估
这里的具体信息可以参看[1].
LazyFTL: A Page-level Flash Translation Layer Optimized for NAND Flash Memory
0x10 引言
在前面的DFTL中,一个映射关系的更新可能要导致多个地方的数据更新,主要的额外开销就来自映射关系page的更新和误区。LazyFTL这里就引入了另外的机制来缓解这个问题。LazyFTL这里的设计比前面的DFTL来得更加精细。除了热点数据Cache在SRAM的做法,LazyFTL将Mapping Table划分为更多的部分,每个部分对应不同访问特点的数据,从而获取到更高的性能,
... LazyFTL that exhibits low response latency and high scalability, and at the same time, eliminates the overhead of merge operations completely. Experimental results show that LazyFTL outperforms all the typical existing FTL schemes and is very close to the theoretically optimal solution.
0x11 基本思路
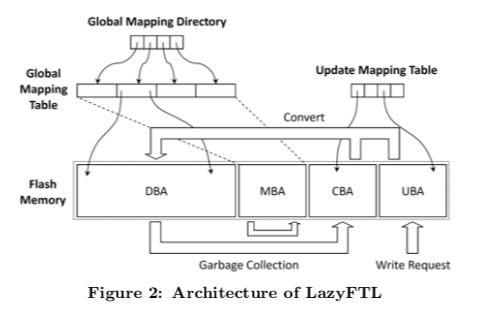
LazyFTL的基本思路如下。总体上讲Flash的存储空间分为4个部分,分为为data block area (DBA), mapping block area (MBA), cold block area (CBA), 和 update block area (UBA)。处理MBA用于存储FTL的数据之外,其它的三个区域都用来保存数据。DBA区域中的数从Page的层面记录映射关系。所以这里称LazyFTL是一个Page-Level的FTL。这个映射表称之为GMT,而GMT本身又以Page为单位组织数据,这些数据被保存到MBA区域。一部分GMT的数据以LRU的方式被缓存在SSD的SDRAM中。GMD则作用于追踪GMT的数据Page保存在哪里,GMT的大小一般都不大,也就将其直接保存在SDRAM中。前面提到的设计和很多一般的Page-Level的FTL的设计没有很大的区别,这里基本上和前面的DFTL是一样的。LazyFTL不同的地方引入了另外的两个区域,一个CBA区域和一个UBA区域。CBA和UBA的目的就是为了延迟对GMT的更新操作,这些操作一般由数据写入和合法的数据Page移动造成的。在合适的时候,两个的区域的数据页会转移到DBA区域。这两个区域页比较小,其映射表UMT页保存在SDRAM中。而它则是以Hash Table或者是查找树之类的结构实现。
- UBA,一个UBA中的Block用于处理写入请求,在这个Block被写满了之后,切换到另外一个空闲的Block。
- CBA,这里的写入发生在垃圾回收的时候,从前面的图中可以看出。处理的逻辑和UBA是一样的,只是这里的数据源来自BABA区域GC的时候移动的数据Page。
LazyFTL的主要的思路就是通过引入这两个额外来减少多GMT和MBA的操作次数。在合适的时候,这两个区域的Block会被转化到DBA区域中去,转换操作的基本流程如下:1. 从CBA和UBA中选择一个转发成本最低的,这里主要就是根据需要更新GMT中页的数量,2. 收集相关页的信息,更新映射表,3. 移除UMT中的映射数据项。
Input: P: new data to be written
1: if the CUB is filled up then
2: if the UBA & CBA are filled up then
3: select a victim block and convert it
4: end if
5: allocate a new block for the CUB
6: end if
7: write P in the UBA
/* Set the update flag */
8: the update flag of P ← 1
/* Inherit or set the invalidate flag */
9: if LPNP can be found in the UMT then
10: P′ ← UMT[LPNP ]
11: the invalidate flag of P ← the invalidate flag of P′
12: invalidate P′
13: the update flag of P′←0
14: the invalidate flag of P′ ← 0
15: else
16: the invalidate flag of P ← 1
17: end if
18: add <LPNP, PPNP> to the UMT
这样有意思的一个问题就是UMT如何在故障之后恢复。这里虽然讲一些数据保存到UMT中,减少了GMT可能的操作次数。本身也是保存在SDRAM中操作的速度页很快,不过它是没有持久化的。丢失这些也会造成不可恢复的故障。这里LazyFTL提出了几种解决的办法,
-
使用结合NAND和NOR的方法。利用NOR可以从Byte级别读写的能力。缺点就是对硬件有要求,可行性不高。
-
另外一个就是讲这些信息保存到MBA,但是会带来额外的开销。
-
另外一个更好的办法是利用生产厂商预留的一点的out-of-band (OOB)来保存相关数据[2],
... Each flash chip consists of a constant number of blocks that are basic units of erase operations. And each block consists of a constant number of pages that are basic units of read and write operations. Most flash memories also pro- vide a spare area for each page to store out-of-band (OOB) data, such as the error correction code (ECC), the logical page number, and the state flag for the page.
0x12 评估
这里的详细信息可以参看[2].
An Efficient Page-level FTL to Optimize Address Translation in Flash Memory
0x20 引言
和前面两篇Paper一样,这篇Paper 提出的也是一个Page Level的FTL的设计。在前面DFTL的基础知识,这篇Paper一开始通过以很大的一个篇幅来说明Page Level的FTL的一个Performance Modek和Write Amplification Model。总结出最有价值的是这样的一点:在DFTL的设计中,FTL的映射信息保存到一些Flash的Page(trianslation pages)上面持久化。一个这样的Page上面大概会保存几百到几千个映射关系。在这篇Paper的统计信息同发现大约有53%到71%的translation page保存了一个以上的dirty enry。这样导致的一个结果就是有些translation page会被频繁刷新,写入,
... a cached translation page will be updated repeatedly, when the dirty entries in the page are successively evicted. This drawback is due to the inefficiency of the replacement policy of DFTL, which writes back only one dirty entry when evicting a dirty entry, regardless of the other more than 14 dirty entries, on average, that share the same translation page with the evicted one.
这里的TPFTL为了解决这个问题,引入了一个2-level的LRU设计,优化为了刷入一个dirty entry就得刷入这个translation page的问题。
0x21 基本思路
和前面的LazyFTL一样,TPFTL也是优化DFTL存在的一些问题。不过两者出发的思路不同。在TPFTL中,translation page中Cache在SRAM中的被组织了一个page-level的LRU list。在每个Page下面,组织的是保存在这个translation page下面的entry的LRU list。
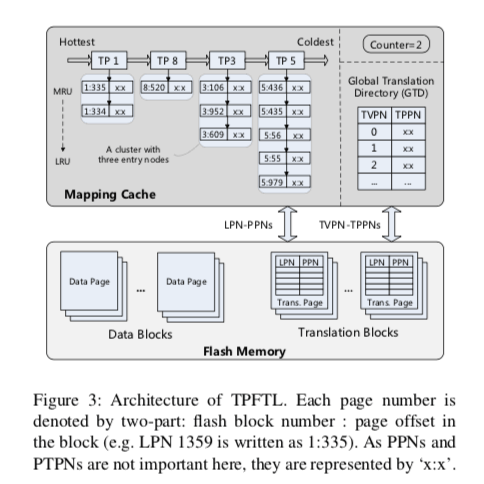
在这样的设计下面,TPFTL引入了几个替换策略,
- batch-update replaceme,这个策略在DFTL中也有使用。TPFTL在这里优化了一下。一个TP node下面一般存在多个ditry entry,TPFTL这样的组织方式就可以一次性将所有的全部更新。
- clean-first replacement,这里的基本思路就是需要淘汰Cache 里面的数据的时候,将没有dirty entry的TP node先考虑,因为这类node不需要进行刷新到Flash上面的操作,节省了时间。另外的优化就是可以为后面的刷入积累更多的dirty entry,从而实现更高的效率。
在FTL加载策略上面,TP-FTL也提出了两种不同的策略,分别适应不同的工作情况,
- request-level prefetching,在一些较大的请求中,即设计到的Page比较多。在这样的情况下面,很可能比较多的Cache Miss。TPFTL这里的优化策略就是在第一次Cache Miss的时候,就将所有相关的映射信息加载到Cache中,而不是等到后面Cache Miss的时候再次被动加载。这种策略在顺序访问的时候有着很好的效率;
- selective prefetching。这里的策略只会预期需要的部分。在顺序访问发生的时候,Cache中TP node的数量会减少。相反地,较少的顺序访问和较多的随机访问会导致Cache中的TP node增多。TPFTL通过设置一个阈值来决定使用equest-level prefetching还是selective prefetching。
0x22 评估
这里的具体信息可以参看[3],
参考
- DFTL: A Flash Translation Layer Employing Demand-based Selective Caching of Page-level Address Mappings, ASPLOS ’09.
- LazyFTL: A Page-level Flash Translation Layer Optimized for NAND Flash Memory, SIGMOD ’11.
- An Efficient Page-level FTL to Optimize Address Translation in Flash Memory, EuroSys ‘15.
