Using One-Sided RDMA Reads to Build a Fast, CPU-Efficient Key-Value Store
0x00 引言
Pilaf是一个基于RDMA的KVS,它的基本的设计思路就是get操作使用bypass的方式,直接访问serber的内存,而对于put操作,则交给server来处理。由于get操作和put操作实际上是不同的机器在处理,这里就还要处理get数据的时候数据被修改的问题,
Our experiments show that Pilaf achieves low latency and high throughput while consuming few CPU resources. Specifically, Pilaf can surpass 1.3 million ops/sec (90% gets) using a single CPU core compared with 55K for Memcached and 59K for Redis.
0x01 基本思路
一般认为RDMA的two-side的操作会有更大的开销,接口更加容易使用。而对于one-sided的操作则刚好相反。Pilaf认为对于KVS中的get这样的只读的操作,直接by-pass的操作能够实现更加高的性能。而put操作一个写类型的操作,处理的逻辑更加负载,如果这里也使用by-pass的方式,则系统难以处理。
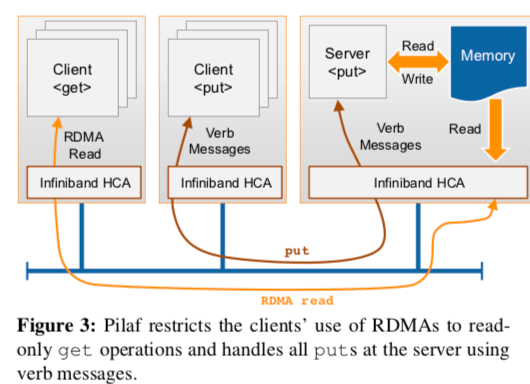
Palif中使用了一个Cuckoo Hash Table作为Key-Value存储的实现。虽然Palif的get操作使用one-sided的操作实现,但是并不代表它的get操作可以在一次one-sided操作中完成。实际上最理想的情况应该是两次,根据Hash Table中数据保存的情况,这个次数可能会更加多。
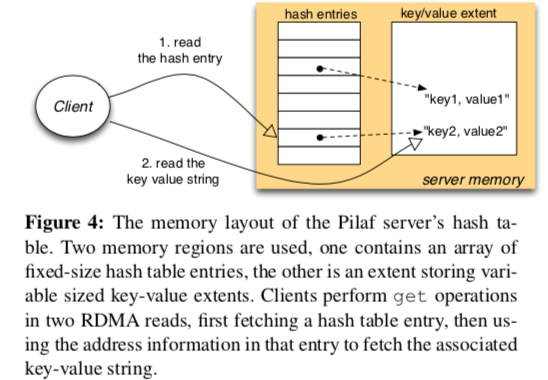
由于get操作是Client在处理,by-pass了Server。而Clientget操作的时候Sever也可能正在修改这个数据,这样就会产生已经race condition的问题。Palif这样使用在Hash Table的Enty中加入Checksum来检查这种情况。
0x02 评估
这里的具体的信息可以参看[1].
Using RDMA Efficiently for Key-Value Services
0x10 基本思路
HERD的设计则考虑使用基于Unreliable Connection (UC)的Write操作来将要写入的数据写入到Server中的一个指定的区域。而Server会轮询这个区域,当发现这里有新的请求的时候,处理请求。数据的返回使用Unreliable Datagram(UD)的SEND Messages操作。
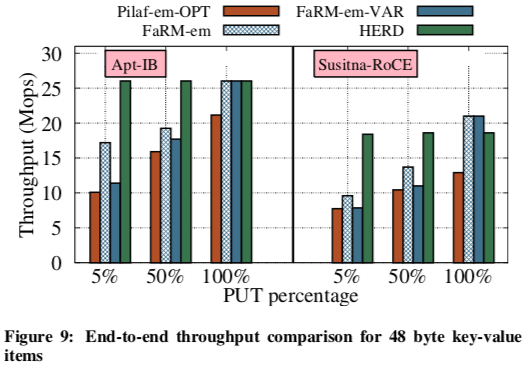
This design uses a single round trip for all requests and supports up to 26 million key-value operations per second with 5 μs average latency. Notably, for small key-value items, our full system throughput is similar to native RDMA read throughput and is over 2X higher than recent RDMA-based key-value systems. We believe that HERD further serves as an effective template for the construction of RDMA-based datacenter services.
HERD在测试数据中表明,WRITEs操作比READs操作有更小的延迟和更高的带宽。HERD的Key-Value的部分基本上就是借鉴了MICA。为了优化性能,HERD直接使用一个16bytes的keyhash来表示Key,一个GET请求中只包含了一个16bytes的keyhash,而一个put请求里面包含了一个16bytes的keyhash,2bytes的长度信息以及一个最长1000bytes的value。这里HERD的设计还是有不少的缺陷的。
0x12 评估
这里的具体信息可以参看[2],
RFP: When RPC is Faster than Server-Bypass with RDMA
0x20 引言
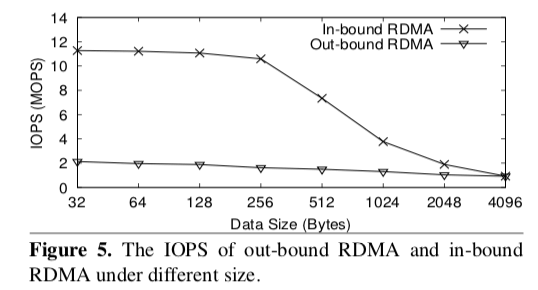
RFP虽然强调的是RPC,但是实际上处理的问题和前面的KVS要处理的问题是一致的。RFP观察到RDMA In-Bound的IOPS会明显高于Out-Bound的能够到达的IOPS,因为In-Bound的操作比Out-Bound要更加复杂一些。另外RFP认为,虽然Server-Bypass的操作方式虽然早RDMA操作本身能够实现更加高性能的操作,但是会带来其它的开销,不同的客户端直接操作内存直接的协调也很难处理,对性能有不小的影响,在很多的情况下比不能实现理论上面更加高的性能。另外,RFP还观察到,虽然In-Bound在很多情况下能够实现比Out-Bound实现更加高的IOPS,但是随着线程数量的增加超过一个阈值之后,性能下降明显。
0x21 基本思路
RFP的基本思路是为了减少系统的复杂度,能够实现预期的性能,Server应该直接参与到数据的处理中。所以RFP中的请求操作并不会Bypass Server。这样设计明显地简化了操作的实现,
// Using RFP
int GET(int server_id, void *key, int key_size, void *value_buf) {
r_buf = prepare_request(key, key_size, GET_MODE);
client_send(s_id, r_buf, sizeof(r_buf));
size = client_recv(s_id, value_buf);
return size;
}
// Using Server-Bypass
int GET(int server_id, void *key, int key_size, void *data_buf) {
while (true) {
md = probe_metadata(server_id);
while(true) {
data = get_data(s_id, md, data_buf);
if checksum of data_buf is ok:
break;
}
get key_size’ and value_size;
if equal(key, key_size, data_buf, key_size’)
break
}
return value_size;
}
RFP又考虑的Out-Bound和In-Bound操作之间的性能差距。RFP选在客户端主动器服务器读取RPC处理的结果,而不是服务器给客户端发送。这里服务器要处理的只是处理请求的时候的In-Bound的操作,而Out-Bound的操作由客户端完成。
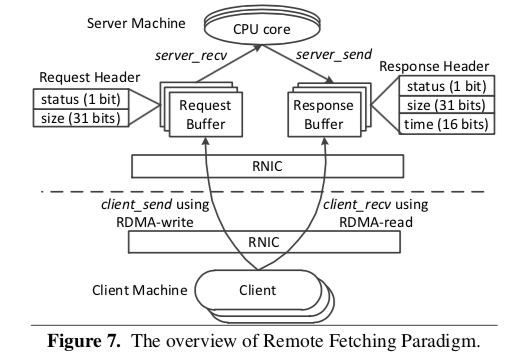
这里RFP还有两个主要的问题要处理:
- 上面时候客户端决定去从服务器获取RPC处理的结果。频繁的获取结果可能导致比较多的无效的操作,反之则可能导致比较大的延迟。RFP使用了一种混合的策略,在开始的几次(R次,一个阈值)尝试,客户端使用频繁轮询的方式,在尝试的次数超过了R次之后,就转表为服务器处理的方式(即非Client Fetch)。
- 因为客户端没有提前知道结果的带下,那么客户端应该决定一次从服务器获取多少数据。太少则会导致多次的RDMA的操作,而太多可能导致读取多余的数据(设为F)。
参数R和F的选择和实际接口强相关[3]。最好能有一种方法动态调整,类似TCP测量RTT的方式一样。
0x22 评估
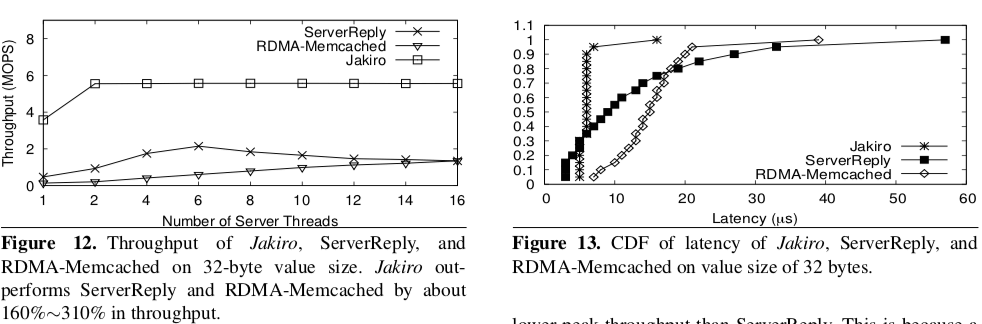
这里具体的内容可以参看[3],
参考
- Using One-Sided RDMA Reads to Build a Fast, CPU-Efficient Key-Value Store, ATC ‘13.
- Using RDMA Efficiently for Key-Value Service, SIGCOMM’14.
- RFP: When RPC is Faster than Server-Bypass with RDMA, EuroSys ’17.
