Sparrow: Distributed, Low Latency Scheduling
0x00 引言
Sparrow的一个最大的特点就是她是一个分布式的集群调度器,采用了去中心化的设计。Sparrow的目标是实现毫秒级的调度延迟。Sparrow架构和Borg这类的中心化的调度器差别是很大的,它里面的Scheduler会发布在多个集群中的节点上面,独立执行调度任务,关于调度器的架构,Firmament的作者有一篇很好的介绍的文章。这样的设计有可能操作一些问题,比如调度冲突的问题等等。Sparrow解决分布式调度器存在的这些问题主要采用的是基于取样的方法以及延迟绑定技术。另外,Sparrow一个prototype在Github上面有开源,总体上来说这个开源的实现还是比较简单的,
We demonstrate that a decentralized, randomized sampling approach provides near-optimal performance while avoiding the throughput and availability limitations of a centralized design. We implement and deploy our scheduler, Sparrow, on a 110-machine cluster and demonstrate that Sparrow performs within 12% of an ideal scheduler.
0x01 基本架构
下面是Sparrow调度器大概的一个架构。在Borg之类的中心化的调度器中,调度器是拥有集群整体的一个view,也就是说调度器可以知道集群的关于调度的所有信息。但是在Sprrow中没有这样的全局的View,如下图所示,Sparrow中是多个的调度器并行处理。在Sprrow里面并不会保存集群负载的一些信息,而是在调度Job的时候,即时查询一些机器的运行情况,从而决定Job运行的位置。
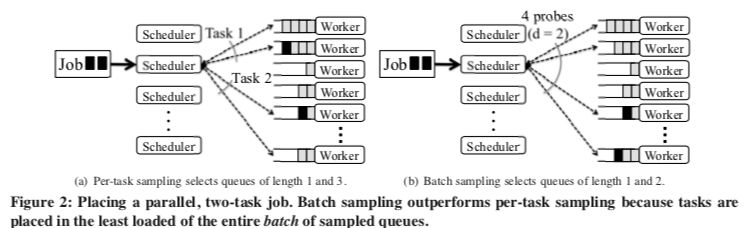
从Sprrow这样的一个工作模式来看,Sprrow就抽象为了一个多个Dispatcher分发任务的一个模型,这个模型就和很多的负载均衡的模型是一样的。Sprrow这里也是使用了类似于power of two choices的在负载均衡中使用的方法。在需要调度一个Task的时候,Sprrow会利用RPC探测一台Worker机器的情况,在Sprrow中称之为per-task sampling。Power of two choices可以获取比随机明显更好的效果。由于等待调度的任务队列里很多时候不止一个任务,正对批量任务来批量采样能够获取更加好效果,
To schedule using batch sampling, a scheduler randomly selects dm worker machines (for d ≥ 1). The scheduler sends a probe to each of the dm workers; as with per-task sampling, each worker replies with the number of queued tasks. The scheduler places one of the job’s m tasks on each of the m least loaded workers.
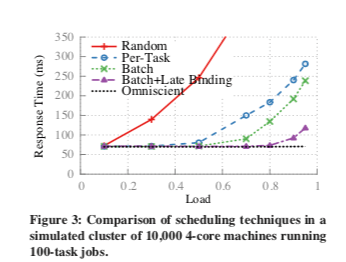
这种基于采样的方式也存在一些问题,从上图中可以看出来,在集群的负载超过了0.7左右之后,响应时间增长得非常明显。Paper中也分析只是基于采用的方法带来的一些缺点,1. 调度器放置Job只是根据Worker中等待队列的长度来决定的,但是用这个等待队列的长度推测实际的运行时候往往存在不小的差异,2. 另外的一个问题就是不同的调度器调度冲突的问题,当多个调度器尝试将任务调度到一台空闲的机器上面的时候,就可能导致一些不佳的调度情况,这个情况在集群负载比较高的时候会显得更加严重。
为了解决这些问题,Sprrow引入来延迟绑定的测量,基本的思路就是在调度器探测的时候,Worker机器并不会立即回复探测请求信息,而是等待之后回复。基本的方式是Worker会在队列中为探测的任务预留一个位置,当这个预留的位置运行到调度队列的最前面的时候,Worker机器就会想调度器发送信息。基本方式是对d给任务,是 porwe-of-m的方式时,调度器会想d * m个Worker发送探测的信息,调度器使用最先回复的d个Worker来运行任务。从上图来看,这种方式的效果很好。
In this manner, the scheduler guarantees that the tasks will be placed on the m probed workers where they will be launched soonest. For exponentially-distributed task durations at 80% load, late binding provides response times 0.55× those with batch sampling, bringing response time to within 5% (4ms) of an omniscient scheduler (as shown in Figure 3).
另外的一个要处理的地方就是这个余下的机器调度器会主动取消。
调度测量 & 限制
不同的任务可能对Worker有一些特殊的要求,比如有些任务需要用到GPU。这样的任务就必须调度到有符合要求的硬件的Worker上面去。Sprrow同样支持带限制条件的调度策略。这个在Sprrow中处理起来是很简单的,
Per-job constraints (e.g., all tasks should be run on a worker with a GPU) are trivially handled at a Sparrow scheduler. Sparrow randomly selects the dm candidate workers from the subset of workers that satisfy the constraint.
对于资源分配的策略,Sprrow同样支持多种策略,
Sparrow supports two types of policies: strict priorities and weighted fair sharing ... Sparrow supports all such policies by maintaining multiple queues on worker nodes. FIFO, earliest deadline first, and shortest job first all reduce to assign- ing a priority to each job, and running the highest priority jobs first. ...
另外一个问题,Sprrow这篇Paper没有提到关于资源利用率的一些信息,估计这样的设计并不会带来很高的利用率。Sparrow本身也没有得到实际的使用,很多数据都是模拟的。开源的实现也只是一个prototype。
0x02 实现
Sparrow在实现上采用的流程如下,Github上面的开源的代码使用Java来实现,RPC使用的是Thrift。
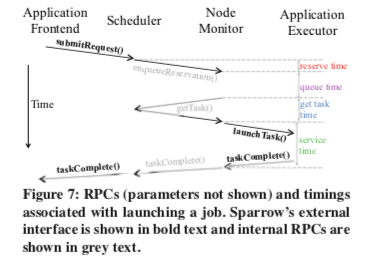
开源的prototype整体也是比较简单的,比如其中的getTask[2],
public List<TTaskLaunchSpec> getTask(
String requestId, THostPort nodeMonitorAddress) {
/* TODO: Consider making this synchronized to avoid the need for synchronization in
* the task placers (although then we'd lose the ability to parallelize over task placers). */
LOG.debug(Logging.functionCall(requestId, nodeMonitorAddress));
TaskPlacer taskPlacer = requestTaskPlacers.get(requestId);
if (taskPlacer == null) {
LOG.debug("Received getTask() request for request " + requestId + ", which had no more " +
"unplaced tasks");
return Lists.newArrayList();
}
synchronized(taskPlacer) {
List<TTaskLaunchSpec> taskLaunchSpecs = taskPlacer.assignTask(nodeMonitorAddress);
if (taskLaunchSpecs == null || taskLaunchSpecs.size() > 1) {
LOG.error("Received invalid task placement for request " + requestId + ": " +
taskLaunchSpecs.toString());
return Lists.newArrayList();
} else if (taskLaunchSpecs.size() == 1) {
AUDIT_LOG.info(Logging.auditEventString("scheduler_assigned_task", requestId,
taskLaunchSpecs.get(0).taskId,
nodeMonitorAddress.getHost()));
} else {
AUDIT_LOG.info(Logging.auditEventString("scheduler_get_task_no_task", requestId,
nodeMonitorAddress.getHost()));
}
if (taskPlacer.allTasksPlaced()) {
LOG.debug("All tasks placed for request " + requestId);
requestTaskPlacers.remove(requestId);
if (useCancellation) {
Set<THostPort> outstandingNodeMonitors =
taskPlacer.getOutstandingNodeMonitorsForCancellation();
for (THostPort nodeMonitorToCancel : outstandingNodeMonitors) {
cancellationService.addCancellation(requestId, nodeMonitorToCancel);
}
}
}
return taskLaunchSpecs;
}
}
其中核心的就是taskPlacer.assignTask,这个函数逻辑也是比较简单的。在这个实现中这部分的逻辑基本上和Paper的思路一致,
public List<TTaskLaunchSpec> assignTask(THostPort nodeMonitorAddress) {
Integer numOutstandingReservations = outstandingReservations.get(nodeMonitorAddress);
if (numOutstandingReservations == null) {
LOG.error("Node monitor " + nodeMonitorAddress +
" not in list of outstanding reservations");
return Lists.newArrayList();
}
if (numOutstandingReservations == 1) {
outstandingReservations.remove(nodeMonitorAddress);
} else {
outstandingReservations.put(nodeMonitorAddress, numOutstandingReservations - 1);
}
if (unlaunchedTasks.isEmpty()) {
LOG.debug("Request " + requestId + ", node monitor " + nodeMonitorAddress.toString() +
": Not assigning a task (no remaining unlaunched tasks).");
return Lists.newArrayList();
} else {
TTaskLaunchSpec launchSpec = unlaunchedTasks.get(0);
unlaunchedTasks.remove(0);
LOG.debug("Request " + requestId + ", node monitor " + nodeMonitorAddress.toString() +
": Assigning task");
return Lists.newArrayList(launchSpec);
}
}
0x03 评估
这里的具体信息可以参看[1],
参考
- Sparrow: Distributed, Low Latency Scheduling, SOSP’13.
- https://github.com/radlab/sparrow. Github.
