Building Consistent Transactions with Inconsistent Replication
0x00 引言
分布式系统中,多副本的策略是一个实现高可用的基本的策略。一旦有副本,就会设计到数据一致性的问题。常见的解决方式有例如主从复制的方式,比如MySQL、Redis中的主从复制。另外的一些复杂一些的例如Paxos、Raft等,也在很多系统中采用。这篇Paper提出了一种在Inconsistent Replication上构建Consistent Transaction系统的方式。基本的思路是提出了一种Inconsistent Replication(IR)协议,这种协议可以满足1. Fault tolerance,2. Visibility,3. Consensus results等的基本保障。在IR协议的基础之上,还需要使用方解决一些执行冲突的策略,实现最终的分布式系统。Paper中构建了一个KVS原型tapir-kv,
Our experiments found that tapir-kv had: (1) 50% lower commit latency, (2) more than 3× better throughput compared to systems using conventional transaction protocols, including an implementation of Spanner’s transaction protocol, and (3) comparable performance to MongoDB and Redis, widely used eventual consistency systems.
0x01 Inconsistent Protocol
IR协议中,应用可以通过两种模式来通过IR进行操作,1. inconsistent模式,这种模式下,在任意副本上面,IR可能以任意的顺序执行应用发起的操作,IR保障操作执行成功之后是持久化的。在发生故障恢复的时候,重新执行这些操作的顺序也是任意的。2.consensus模式,在这种模式下面,同样地,在任意副本上面,IR可能以任意的顺序执行应用发起的操作。不同的地方在于consensus mode下面的操作必须返回一个一致的结果(a single consensus result)。这个一致的结构可以时多数副本返回的相同的结构,也可以是通过一个应用提供的一个decide function,这个函数用于在一些情况下决定出一个consensus result。
- 在这里inconsistent操作类似于weak consistency的复制协议,操作可能在不同的副本上面有不同的执行顺序。而可能导致的不同的结构必须有应用的协议来处理。每个副本独立操作产生自己的结果,客户端接受到的是一个result的集合。
- 相反的consensus操作要求满足下面两个条件中的一个,1. 在副本副本上的可能的不同顺序的操作都返回了相同的结果,2. 不同结果的冲突通过应用提供的decide function解决了。
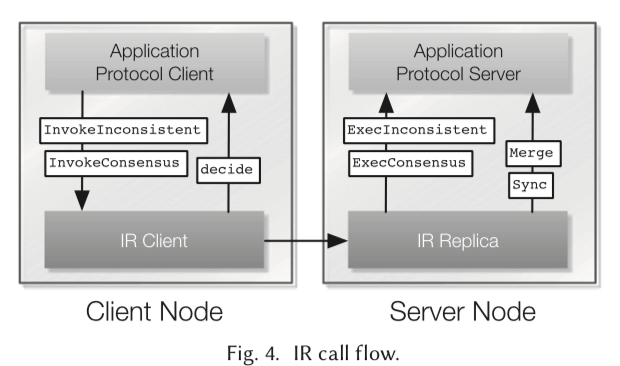
客户端通过Invoke**的两个接口和IR Client交互,最终会请求到IR Replica上。IR Repilca会通过ExecInconsistent(op) ExecConsensus(op)接口调用Application Protocol Server。另外的Merge和Sync两个结果用于决定处理不同结果的冲突,是的Application Protocol Server达到一个一致的状态。基本的组织逻辑如下图所示。IR这里就是作为一个复制协议,在2f+1个副本的情况下,可以实现f个副本故障的情况下仍然正常工作,不能给容忍Byzantine类型的故障。
Client Interface
InvokeInconsistent(op)
InvokeConsensus(op, decide(results)) → result
Replica Upcalls
ExecInconsistent(op) ExecConsensus(op) → result
Sync(R) Merge(d, u) → record
Client State
• client id - unique identifier for the client
• operation counter - # of sent operations
Replica State
• state - current replica state; either NORMAL or VIEW-CHANGING • record - unordered set of operations and consensus results
以一个在IR协议上面构建一个Lock Server为例,这个必须保证一个lock只能由一个client持有。在实现的时候,可以使用consensus实现Lock操作,而利用inconsistent操作来实现Unlock操作。由于客户端请求的操作可能在不同的副本上面有不同的执行顺序,Client使用一个unique ids(a tuple of client id and a sequence number)标记对用的Lock和Unlock操作。而且只有在Lock操作首先成功的情况下,才会进行Unlock操作,这样可以保证Lock和Unlock操作之间的顺序要求。由于操作不同的操作顺序可能导致的在某些副本上面的不正常的状态,这里会使用lock server’s decide function来解决。如果在f+1个副本返回OK的情况下就可以解决这个问题。IR Protocol中,包含了4个子部分的Protocol,1. operation processing, 2. replica recovery / synchronization, 3. client recovery, 以及 4. group membership change。后面两个subprotocol采用和Viewstamped Replication中相同的机制。
-
Operation Processing,正常情况下insonsistant的操作如下,
1. 客户端通过<PROPOSE, id, op>发送请求给所有的副本,id为操作id,op表示操作; 2. 每个副本记录下这个id和op,标记为TENTATIVE; 3. 客户端在收到f+1个回应之后(必要的时候可以重试),返回给application protocol,并异步发送<FINALIZE, id>给所有副本; 4. 在接收到FINALIZE消息之后,副本通过ExecInconsistent(op)接口请求application protocol server,并标记这个op为FINALIZED。通过上面的机制,IR可以在f+1个副本的single round-trip之内完成操作。对于consensus操作,当满足3/2 f + 1个副本返回matching results的时候,可以使用快速路径,这个副本的数量和一些Paxos中变种使用的副本数量类似。这样可以保证最终可以得到一个一致的结果。在fast path没有成功的时候,slow path比较麻烦,
1. 客户端通过<PROPOSE, id, op>发送请求给所有的副本,id为操作id,op表示操作; 2. 每个副本通过ExecConsensus(op)接口请求application protocol server,记录下这个id和op,标记为TENTATIVE; 3. 如果客户端收到3/2f+1个副本的matching results,则进入fast path,将结果返回给application protocol,并异步发送<FINALIZE, id, result>消息给所有的副本; 4.否则进入slow path,客户端在收到了f+1个回复之后,发送<FINALIZE, id, result>给所有的副本,这里result需要通过decide function从收到的result集合中决定出来; 5. 在收到FINALIZE消息之后,标记为操作FINALIZED,如果接受到result不同,需要更新记录。然后将<CONFIRM, id>发送给client; 6. 在接收到f + 1个CONFIRM消息之后,客户端返回结果给application protocol。slow path需要f+1个副本的两个RTT才能完成操作,而fast path需要3/2f + 1个副本的一个RTT。
-
Replica Recovery and Synchronization,IR使用一个协议同时处理Replica Recovery 和 Synchronization的问题。因为在副本故障之后回复的过程中,对应的副本也要同步在故障的过程中错误的操作,这里就可以使用和Synchronization同样的协议来处理。view changes这里也是要处理的一个问题,不过这里直接就使用了Viewstamped Replication协议中对应的部分的subprotocol,还有另外的一些protocol改动。
关于Protocol的正确性证明可以参看[1].
0x02 TAPIR
TAPIR是建立在IR之上的一个支持事务的分布式存储系统。TAPIR设计主要涉及到transaction processing protocol, IR functions, 以及 a coordinator recovery protocol。TAPIR涉及到的接口如下,
Client Interface
Begin()
Read(key) -> object
Abort()
Commit()→TRUE/FALSE
Write(key, object)
Client State
• client id - unique client identifier
• transaction - ongoing transaction id, read set, write set
Replica Interface
Read(key)→object,version
Commit(txn, timestamp)
Abort(txn, timestamp)
Prepare(txn,timestamp)→PREPARE-OK/ABSTAIN/ABORT/(RETRY, t)
Replica State
• prepared list - list of transactions replica is prepared to commit
• transaction log - log of committed and aborted transactions
• store - versioned data store
在TAPIR中执行一个事务,对于写入请求,客户端会先将先暂存在Client Buffer中,直到Commit的时候把这个Write Set提交。对于读取请求,如果object存在Write Set 中,则直接返回这个Write Set中的数据,如果读取的是已经缓存的数据就直接从cache中读取,否则才会直接读取请求。对于读取请求,副本会返回对象和一个版本信息,version一般为写入这个object version的时间戳。这样的话如何Commit时一个核心的操作,
- TAPIR的Client选择一个proposed timestamp,这个时间戳必须时唯一的。可以选择本地时间戳加上client id的方式组合为唯一的proposed timestamp。然后TAPIR Client通过Prepare(txn,timestamp)调用作为一个consensus 操作,请求中会包含时间戳、事务ID以及读写集合等的信息。这里会向所有的participants发送这个请求。TAPIR Replica在收到这个请求之后,首先检查transaction log中的txn.id的信息。如果发现了,根据事务是否已经Commit or Abort返回对应的信息,PREPARE-OK or Abort。这个是为了处理客户端的重复请求。否则检查prepare-list,如果存在其中则返回PREPARE-OK;
- 上面的操作都没有返回的情况下,执行一个OCC Validation检查的操作,主要是利用时间戳检查事务之间的冲突。TAPIR Client在收到了所有的shards的回复之后。如果所有的Shards为PREPARE-OK,则Client在请求一个Commit,否则请求一个Abort。在任何一个shards返回RETRY的情况下。客户端会重试请求。
- 在收到了Commit的请求之后,TAPIR Replica,1. 将事务写入到transaction log中,2. 更新保存对象的版本信息,3. 从prepare list中移除这个事务的信息,4. 然后返回给客户端。在收到了abort请求的时候,同样会log下这个abort的信息,2. 从prepare list中移除这个事务的信息,3. 然后返回给客户端。这个时间就是一个2PC的操作。
这里的实际上还没有什么很特别的,IR中一个很特殊的一个事情就是应用的提供处理结果冲突的逻辑。一个client-side decide function是这里的核心。

0x03 评估
这里的具体信息可以参看[1].
参考
- Building Consistent Transactions with Inconsistent Replication, TOCS ‘18.
