BP-Wrapper: A System Framework Making Any Replacement Algorithms (Almost) Lock Contention Free
0x00 基本思路
这篇Paper的思路还是比较简单的。在java著名的本地缓存库caffeine中也得到了应用。这里不是提出一种新的缓存替换算法,而是在Buffer Pool替换Page的操作中如何降低锁冲突。一些数据的系统中的思路是将其拆分为多个Buffer Pool实例,这里的思路是引入Queue,将需要对Buffer Pool内部数据结构更新的操作先累积在线程局部的FIFO Queue中,然后再处理啊。通过这样的方式实现操作的批量处理,加上预取的机制,来优化性能,
In BP-Wrapper, we use batching and prefetching techniques to reduce lock contention and to retain high hit ratio. The implementation of BP-Wrapper in PostgreSQL version 8.2 adds only about 300 lines of C code. It can increase the throughput up to two folds compared with the replacement algorithms with lock contention when running TPC-C-like and TPC-W-like workloads.
0x01 基本思路
BP-Wrapper可以适用于一般的缓存替换算法。基本的思路是使用一个FIFO的Queue来累积需要处理访问学习。基本的结构如下图所示。这个FIFO Queue为每个工作线程一个,这样这里实际上就是完全没有锁的冲突。每次查询的时候,为了满足Buffer Pool使用的缓存替换算法的一些要求,会对其中的一些数据结构进行修改,比如一些数据库Buffer Pool的LRU List。这个是多线程操作的时候锁冲突的主要来源之一。这里不会立即就是更新Buffer Pool内部的数据结构,当Page命中的时候,会讲访问这个Page的学习记录在这个FIFO Queue中。当这个Queue中的数量达到一个阈值的时候,才会申请加锁,安装使用的缓存替换算法更新内部的数据结构,这个操作称之为committing the recorded accesses.。
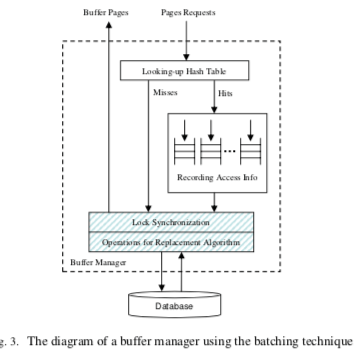
0x02 评估
这里的具体信息可以参看[1]
Turbocharging DBMS Buffer Pool Using SSDs
0x10 引言
这篇Paper是SQL Server中如何利用SSD作为Buffer Pool的一个拓展的设计。之前是SSD,现在的一些系统也有类似的思路,不过使用的存储介质变成了NVMM,无论是SSD作为HDD的加速,还是NVMM作为SSD加速,其基本的思路还是有很多类似的地方。
... ran experiments using a variety of benchmarks (TPC-C, E and H) at multiple scale factors. Our empirical evaluation shows significant performance improvements of our methods over the default HDD configuration (up to 9.4X), and up to a 6.8X speedup over TAC.
0x11 基本设计
将SSD作为内存Buffer Pool的一个拓展,可以有多种实现思路。Paper中讨论了下图中的几种思路,以及和另外一篇Paper中的一种思路的对比,
- The Clean-Write (CW) Design,CW思路中,SSD只会保存Clean Page。从内存中Buffer Pool驱逐的Page会写入到磁盘中。SSD中的Page保存和磁盘上面的Page一致。这样的好处就是可以不用修改现在的Checkpoint和Recovery的逻辑。这种设计适合很少更新的workload。这种方式是实现最简单的,但是一般情况下也是性能最差的。
- The Dual-Write (DW) Design,从内存中驱逐的Dirty Page会同时写入磁盘和SSD。这里SSD的角色就类似于一个write-through的Cache。这里同样地SSD中的数据和磁盘中的数据保持一致,也不同修改现在的Checkpoint和Recovery的逻辑。
- The Lazy-Cleaning (LC) Design,这种策略中,SSD的角色就类似于一个write-back的Cache。Dirty Page先写入SSD中,在合适的时候再写入到磁盘中。这里很多时候能够获取更好的性能,但是需要修改现在的Checkpoint和Recovery的逻辑。
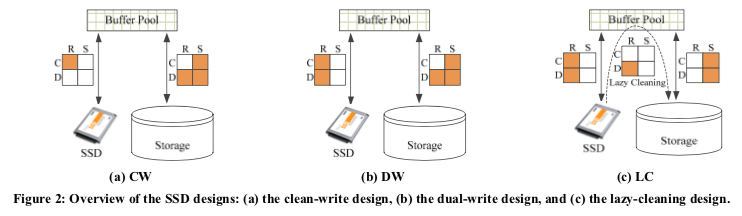
在另外一篇Paper中,提出的TAC思路如下:1. Page Miss的时候,去查找SSD Buffer Pool,如果找到了则直接返回,否则从磁盘中读取,2. 从磁盘读取了一个Page之后,如果认为这个Page适合Cache在SSD中,则往其中写入一份。3. 如果Buffer Pool中的Page被更新,则设置SSD中对应的Page为无效。4. 从Buffer Pool驱逐一个Dirty Page的时候,写入磁盘的逻辑和一般的一样,另外如何有一个被设置为无效的SSD版本,则也更新SSD上面的数据。这里的设计有这样的一些考虑,1. 这里在SSD上面的Page失效之后,会立即回收,而TAC的策略不会。在更新频繁的负载中TAC的方式会浪费一些空间。2. TAC从磁盘读取一个Page的时候,如果这个Page适合写入SSD,TAC会立即写入。这里认为这种方式可能导致一些latch冲突的问题,因为这个操作延长了读取Page操作需要处理的时间。这里是从Buffer Pool中驱逐出去的时候写入。
0x12 实现
这里使用的基本的数据结构如下图,主要包含下面几个部分,1. SSD Buffer Pool,这个就是一个安装Page大小划分的一个文件,每个单元称之为SSD Frame,2. SSD Buffer Table,这个保存在内存中,保证关于SSD Frame的一些信息,每个单元称之为SSD Record。这里包含了Page ID、Dirty标识位、最近两次的访问时间、Latch已经一些用于管理这些结构的指针,比如Free List的指针,3. 在这个Buffer Table的基础之后,构建了一个SSD Hash Table用于加速查找操作,4. 为了可以对SSD中的Pag进行驱逐操作,这里使用的结构是SSD Heap Array,这个Heap中每个entry有一个指向SSD Record的指针,用于处理缓存替换的问题。这里被划分为clean 和 dirty heaps 两个部分。
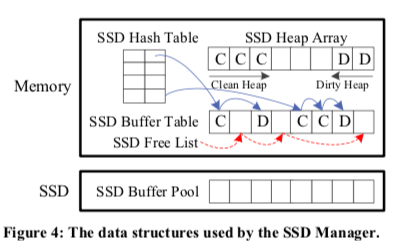
在sharp checkpoint的机制下面,如果使用LC的方式,所有SSD中的Dirty Page会在checkpoint操作的时候刷入磁盘,而且在这个过程中SSD Buffer Pool也不会接受新的Page写入。处理基本的思路之外,这里还使用了一些优化措施,1. 其冷启动的时候,为了快速使用起SSD Buffer Pool,所有从内存驱逐的Page都会写入SSD,直到到达一个占用率的阈值。到达这个阈值的时候,会对驱逐的Page进行判断,只有认为有价值的才会写入到SSD。2. 在需要的时候控制SSD的IO占用。3. 在合适的时候使用Multi-page I/*的方式。4. 通过分区的方式降低多线程操作的冲突,和一些内存中Buffer Pool的优化的方式相同。4. LC的方式中,合并操作连续的Page。
0x13 评估
这里的具体信息可以参看[3].
Multi-Tier Buffer Management and Storage System Design for Non-Volatile Memory
0x20 引言
这篇Paper应该是估计是被某数据库会议拒了,目前的版本在arXiv上。讨论的是利用NVM,在DRAM和SSD的基础之上构建多层的Buffer Management。前面的多层是DRAM和HDD的基础之上添加一个SSD来加速,SSD普及之后,这里变成了NVMM。很多基础的思路是一致的,因为NVMM的特点也可以有另外一些优化,
0x21 基本设计
这里的基本设计如下图,箭头表示了数据流。这里总的来说是作为一个Multi-Tier的设计。所以这里读取的时候会,先从SSD中读取,然后转移到NVM中,最后再到内存中。一个规规矩矩的多层的设计。这样其实可以发现可以有不少优化的地方。这个也是这篇Paper会讨论的一些内容。默认的写入路径是将内存中的数据写入到NVM,最后写入SSD中。另外的7、8、9和10的路径是为优化而存在的。
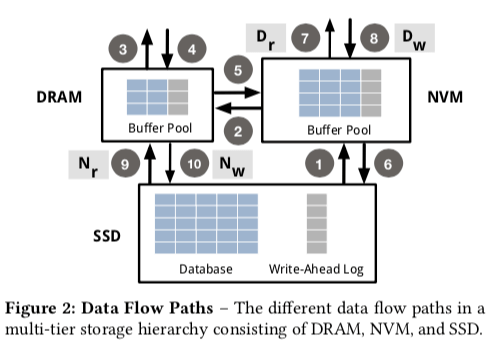
- 读取时Bypass DRAM,路径7,这里利用了NVM可以字节寻址的特性。路径7可以使得数据库选择一个lazy migration的思路,即可以判断一个数据是否得立即读取到内存中,在做处理。一些情况下,直接从NVM读取就可以了,不同在将数据读取到内存中,这样的节省了一些内存和NVM之间的数据转移操作。这样的策略在内存的大小显著小于NVM的时候更加有效果,可以保持最热的数据在内存中。这里使用Dr表示读取操作的时候数据拷贝到内存的概率。
- 同样地,写入数据的时候也可以选择Bypass内存。在使用NVM的时候,不用像现在的数据库系统将要写入的日志、数据积累到一定的量之后在写入SSD。NVM可以直接写入需要持久化的数据,这个称之为synchronous persistence,这样可以避免一些额外的内存数据的操作,也可以使得内存中保持的数据为热度最高的。这里使用Dw表示写数据的时候写入内存的概率。
- 读取时Bypass NVM,当读取的一个Page的时候,数据只存在SSD中,这里就可以考虑直接将数据读取到内存中,而不是在从NVM中走一圈。如果被读取的时候之后没有被修改,可能会被缓存替换算法直接舍弃,如果之后有修改,可以选择驱逐到NVM中。使用Nr表示从SSD中拷贝数据到NVM的概率。
- 写入时Bypass NVM,同样地可以考虑在写入操作的时候Bypass NVM。这里的优化可以使得“暖”一些的数据保存到NVM中,而一些比较冷的数据就保存到SSD中。这里使用Nw表示写入操作的时候从内存拷贝数据到NVM的概率。
然后就是讨论怎么决定使用这些策略,这里使用的是一个基于搜索的方法,给定一个cost function,从一个初始值出发,改变参数不断搜索,直到到达终止条件,
Require: temperature reduction parameter α,
threshold for number of accepted transitions γ ,
initial data policy configuration C0,
initial temperature T0,
final temperature Tmin
function UPDATE-CONFIGURATION(α,γ,C0,T0,Tmin)
# Initialization
current configuration C = C0
energy E = cost(C)
temperature T =T0
# Iterative Search
while T > Tmin do
while number of accepted transitions < γ do
new configuration C′ = neighbor(C)
energy E′ = cost(C′)
energy delta ∆E = E′ -E
Boltzmann acceptance probability P = e T
if ∆E < 0 or with acceptance probability P then
# Accept new policy configuration
C =C′
end if
end while
# Reduce temperature
T=T*α
end while
end function
0x22 评估
这里的具体信息可以参看[4].
参考
- BP-Wrapper: A System Framework Making Any Replacement Algorithms (Almost) Lock Contention Free, ICDE ‘09.
- A New Approach to Dynamic Self-Tuning of Database Buffers, TOS ‘08.
- Turbocharging DBMS Buffer Pool Using SSDs, SIGMOD ‘11.
- Multi-Tier Buffer Management and Storage System Design for Non-Volatile Memory, arXiv.
- Adaptive Self-Tuning Memory in DB2, VLDB ‘06.
- Sharing Buffer Pool Memory in Multi-Tenant Relational Database-as-a-Service, VLDB ‘15.
- Operation-Aware Buffer Management in Flash-based Systems, SIGMOD ‘11.
