GearDB: A GC-free Key-Value Store on HM-SMR Drives with Gear Compaction
0x00 引言
这篇Paper是关于在SMR(叠瓦是磁记录)磁盘上面的优化。SMR磁盘的特点虽然容量更大,但是几乎没有什么随机写的性能,个人用户非常不推荐购买这类磁盘。之前FAST上面有篇Paper就是消除ext4文件系统上面的一个更新文件元数据的随机写操作来提高性能。而GearDB则提出针对LSM-Tree在SMR的环境下面的几个优化策略,
We implement and evaluate GearDB with LevelDB on a real HM-SMR drive. Our extensive experiments have shown that GearDB achieves both good performance and space efficiency, i.e., on average 1.71× faster than LevelDB in random write with a space efficiency of 89.9%.
0x01 基本思路
Data Layout
在SMR磁盘上面,它将磁盘的存储空间分为若干的zone,每一个zone的大小多为256MB,而在这个zone里面数据只能顺序写入,就类似于一个磁带。另外SMR也存在一些可以随机写的区域,HM-SMR磁盘提高了一些接口来交给软件来管理。之前的在SMR磁盘上面的一个改进就是将SST的文件放大到一个zone的大小,不过这样的确定到来的另外一个问题就是随机读性能的下降,以及Compaction操作的时候文件过大带来的延迟的问题。GearDB的第一个改进首先就是改变LSM-Tree的SST文件保存安排的位置是随机的情况。在GearDB中,它会安排在一个zone中保存属于同一个level的文件。这样做的原因就是不同Level的Compaction操作执行频率是不同的,这样可以减少zones里面的数据。比如下图中的zone 1中L0,如果L0执行Compaction操作,zone 1中两个L0的文件就变成碎片不能使用,如果需要使用这个部分的文件则需要对整个的zone进行整理。而如果是同一个level的文件,则可以有可能可以整理。

Compaction Windows
另外为了进一步优化这个问题,GearDB还将一层中Compaction操作的范围限制在一个 Compaction Window之内, \(\\ S_{cwi} = \frac{1}{k} \cdot L_{L_i}, 1 \leq k \leq AF\) 即为一次尺寸最大限制值L_{L_i}的1/k。在一个Compaction Window里面的zones的Compaction操作完成之后,这些zones就可以被释放,然后这些zones就可以作为一个空的zone接受后面的写入操作。
Gear Compaction
LevelDB中的一些实现就是Li层Compaction到Li+1的时候,就是直接合并进去。而Gear Compaction则将合并之后的数据分为3个部分,一个是在Li+2的Compaction Windows之外的部分,一个是在Li+2包含的Key范围之外的部分,另外一个就是在Li+2的Compaction Windows之内的部分。分为做:1. 写入到Li+1,2. 直接dump到Li+2,3. 有这个Compaction操作引起的被动Compaction处理。直接Dump 的操作优化了会被又被重写写入下一层的写放大的问题,另外GearDB不会一路dump下去,而是有一个限制。Gear Compaction设计也会在Cimpaction操作之后适当的时机可以直接回收一个Compaction Windows里面的zones,而不同做一个GC的一个操作(论文中GC-free的来源),
1) compactions and fragments are limited to the compaction window of each level;
2) compaction windows are reclaimed automatically during gear compactions, thereby eliminating the expensive on-disk garbage collections since compaction windows filled with invalid SSTables can be reused as free space; and
3) gear compaction compacts SSTables to a higher level with fewer reads and writes and no additional overhead.
0x02 评估
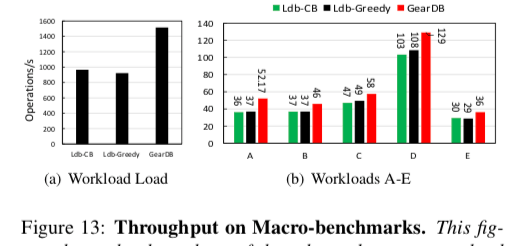
这里的详细信息可以参看[1],
SLM-DB: Single-Level Key-Value Store with Persistent Memory
0x10 引言
SLM-DB同样是一种将不同的idea组合到一起形成的心的idea。与前面的HiKV不同,SLM-DB是将Btree和LSM-Tree结合到一起,
In SLM-DB, we exploit persistent memory to maintain a B+-tree index and adopt an LSM-tree approach to stage inserted KV pairs in a PM resident memory buffer... in our default setup, compared to LevelDB, SLM-DB provides 1.07 - 1.96 and 1.56 - 2.22 times higher read and write throughput, respectively, as well as comparable range query performance.
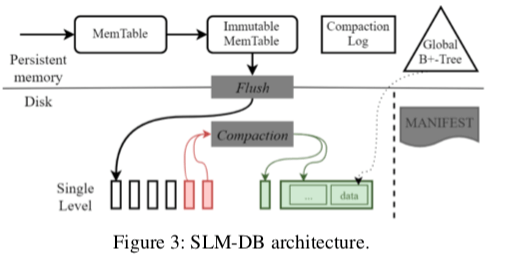
0x11 基本思路
SLM-DB可以看作是是添加了Memetable的B+-Tree。SLM-DB的基本架构如上面的图所示。SLM-DB中,数据都是保存在PM or 磁盘上面的,及时Memtable也是保存到PM上面。由于Memtable保存到内存中,也需要写WAL,这样不一定能够带来性能的提升,
-
在SLM-DB中,Memtable部分的工作流程和一般的LSM-Tree实现的方式是一样的。SLM-DB这里使用了一个实现在NVM中的一个持久化保存的SkipList。在尺寸增长到一定程度的时候,这个Memtable会变为Immutable的,之后又会被Flush到一般的磁盘上面。
-
Flush到磁盘上面的Memtable会被后面的Compaction操作合并。在Flush操作的时候,SLM-DB使用两个后台的线程来处理,一个是执行Flush到磁盘上面的操作,另外一个负责将这些数据添加到B+-Tree里面。SLM-DB中的合并操作是一种选择性的合并,选择能够获取更高效益的SST文件合并。这里的合并的操作和LSM-Tree的很多事类似的,不过SLM-DB只会存在一层,合并也是在一层中进行,
To select candidate SSTables for compaction, SLM-DB implements three selection schemes based on the live-key ratio of an SSTable, the leaf node scans in the B+-tree, and the degree of sequentiality per range query. -
SLM-DB一些操作实现的逻辑,
- Put操作,SLM-DB中Put操作就是直接添加到Memtable中,随着系统的运行,会被转移到Immutable Memtable以及后面的SST文件。
- Get操作,SLM-DB中的点查找操作会先查找Memtable中的数据。如果没有发现,就回去从B+-Tree中查找。如果B+Tree中存在这个Key的信息,会得到这个Key-Value在磁盘上面的位置信息。这些信息保存到一个SST文件之中,然后从这个文件中读出这个Key-Value即可。
- 范围查询。这里主要要处理的问题就是要合并Memtable中的数据和B+-Tree中的数据。
0x12 评估
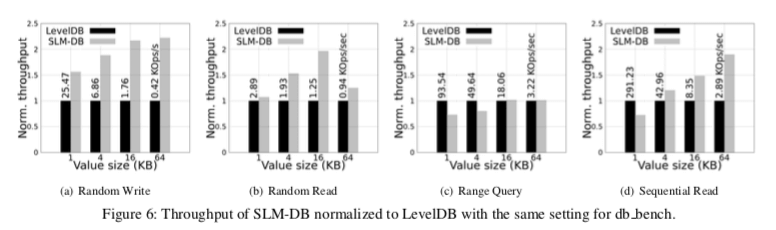
这里的具体信息可以参见[2],
参考
- GearDB: A GC-free Key-Value Store on HM-SMR Drives with Gear Compaction, FAST ‘19.
- SLM-DB: Single-Level Key-Value Store with Persistent Memory, FAST ‘19.
