Scaling Memcached at Facebook
0x00 引言
这篇Paper是很值得读的一篇关于KVS的Paper。它的关注点不是KVS具体的实现,而是Memcached在Facebook中的应用。主要设计到Facebook关于通信协议、负载优化、复制以及一致性方面的内容,这些可能比具体的KVS的技术更加有用,
... Facebook leverages memcached as a building block to construct and scale a distributed key-value store that supports the world’s largest social network. Our system handles billions of requests per second and holds trillions of items to deliver a rich experience for over a billion users around the world.
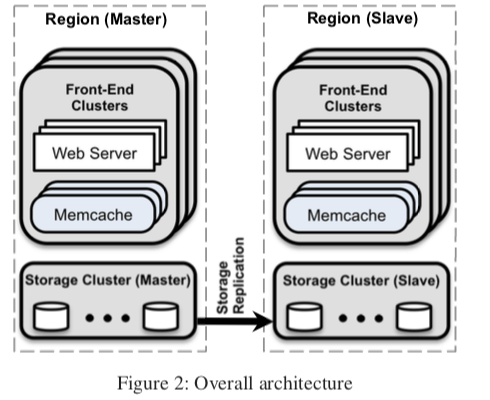
0x01 Cluster
减少延迟
Facebook使用几种方式来减少处理的延迟,
- 并行请求,通过对数据之间的依赖关系构建DAG图,找出可以最大并发请求的数据。在Facebook的数据中,平均一次批量处理24个左右的Keys;
- 通信协议,Memcached是同时支持TCP协议和UDP协议的。通过对get操作使用UDP协议,而其它操作使用TCP协议,可以使用约20%的延迟减低。UDP丢包的时候被视为缓存缺失,在Facebook的应用,UDP丢包的概率是很小的。
- Incast优化,Incast问题在一些应用是常见的问题。客户端一次需要请求大量的Key的时候,如果一次性请求,则可以造成由于Incase造成的拥塞。在这里的解决方式是采用类似TCP中的滑动窗口式的方法。
Reducing Load
这里的负载优化主要就是如何减少从数据库中获取数据的次数,
- 租约。这里就是在缓存未命中的时候,减少访问数据库的次数。这里的场景就是一个Key缺失的时候,可能会导致多次的数据库访问,但是实际上这里只需要一次即可。缓存缺失的时候Memcached赋予客户端一个Token,服务器也可以限制返回Token的频率,从而限制Key缺失的时候多余的无效的数据库访问。通过这个改进,Facebook的一个数据库访问的数据峰值由17K/s下降到1.3K/s。
- 另外一个就是处理不同的Key访问的频率不一样的问题。也可以看作是一个负载均衡的问题。这里会收集一些访问的信息,根据这些信息可以让一个服务区处理较大数据的不是热点的Key,或者是处理较少数据的热点的Key。
- 另外一个优化就是复制了。负载过大的问题可以通过更多的分区解决,也可以通过副本来解决。这里采用的方式是使用副本,因为这样更好的处理热点的Keys,将这些热点的访问分散到不同的机器上面。
- 另外Facebook还采用预留一些备用机器的方式解决一些机器故障的问题。
0x02 Region
在上面的架构图中,Facebook将系统划分为Region,
- 这样的话带来的问题就是数据更新的时候需要将多个Rregion里面的数据处理为失效。Facebook认为这个 直接有Web Servers处理会带来不少的问题。这里就是由存储层来解决的。基本的架构如下面的图所示。
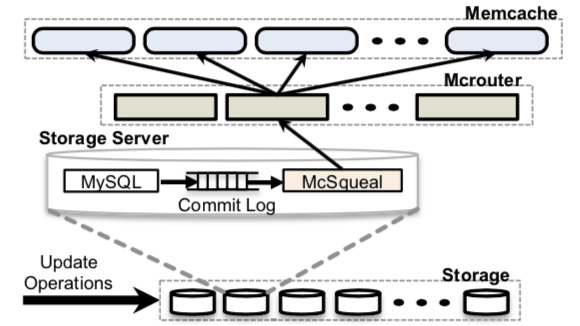
-
另外的一个优化是区分冷热数据。对于不是热点的数据,在不同的Region保存多个副本就可能带来比较多的资源消耗,而且能够获取到的收益比较小。这里将一部分的服务器设置为一个不同Region共享的Pool。一些冷数据可以放到这里。这里的另外一个问题就是如何区分冷热数据。
-
冷启动的优化,在新添加的缓存机器的时候。机器突然的加入就可能导致总是缺失,造成数据库访问次数突增。这里的方法就是先预热一下,先根据来的查询添加数据,过一段时间之后才提高服务。
-
对于跨Region的一些情况,就还有一致性的问题要处理。如果和数据库主从中的主位于同一个Region的话,按照一般的流程处理即可。另外如果Memcached位于数据库主从的从去,就可能在从数据库没有更新之前读取了,并保存到了数据里面,这样就可能导致Memcached里面保存的是过时的数据。这里解决的方法是采用了一种叫做remote marker的方法。存在这个Marker的时候请求会转发给主区处理,
When a web server wishes to update data that affects a key k, that server (1) sets a remote marker rk in the region, (2) performs the write to the master embedding k and rk to be invalidated in the SQL statement, and (3) deletes k in the local cluster. On a subsequent request for k, a web server will be unable to find the cached data, check whether rk exists, and direct its query to the master or local region depending on the presence of rk.
0x03 评估
这里的具体信息可以参看[1],
HiKV: A Hybrid Index Key-Value Store for DRAM-NVM Memory Systems
0x10 引言
这篇Paper的设计是关于一种混合索引的KVS的设计。现在关于KVS的Paper层出不穷,不少的想法就是将之前的idea组合起来形成新的idea。这篇Paper也是这样的一个思路,它将B-tree以及Hash索引组合到一起,应用到DRAM+NVM的环境,形成了一种新的KVS的设计,
For single-threaded performance, HiKV outperforms the state-of-the-art NVM-based key-value stores by reducing latency up to 86.6%, and for multi-threaded performance, HiKV increases the throughput by up to 6.4x under YCSB workloads.
0x11 基本思路
HiKV的基本思路就是在内存中维护一个全局的B+-Tree的一个索引结构,然后数据分区保存到NVM上面,再在NVM上面的分区构建Hash索引。单点的查询直接利用分区的Hash索引即可,可以实现更加好的性能,而B+Tree的索引主要就是为了范围查询时候的使用。
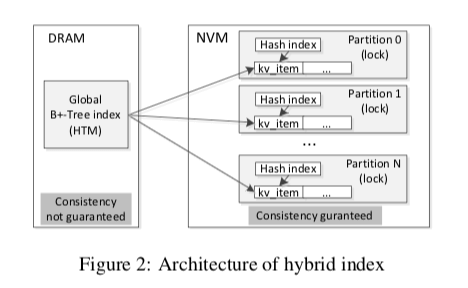
这样主要有这样的几点问题,
-
索引更新,在HiKV中,添加or删除数据之后需要更新两个索引,这样可能带来更大的开销。HIKV采用的方式是对于NVM中的Hash索引就使用同步更新的方式,而对于内存中的B+-Tree索引,有它更新的代价更大,则采用了异步更新的方式。这样带来的另外一个问题就是根据B+-Tree操作的时候可能存在的数据不一致的情况。HiKV的解决方式是在内存中添加了一个更新队列,根据B+-Tree进行操作的时候会也会查看这个更新队列里面的数据。
-
分区的方式。这里可以根据Key的范围分区 or 根据Key的Hash值来分区,这样分别对B+-Tree索引的实现和对Hash索引的实现有利。而HiKV采用的是根据Key的Hash分区的策略,
... However, we argue that none can efficiently support Scan due to extra efforts. With unordered multi-B+-Tree indexes, we need to issue the scan request to all indexes, and then return the matching key-values from the result. Such approach increases the concurrency overhead.
其它的就没有什么特别的地方。
0x12 评估
这里具体的信息可以参看[2],
Be Fast, Cheap and in Control with SwitchKV
0x20 引言
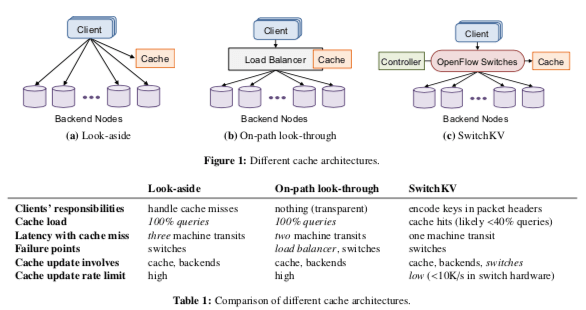
这篇Paper关于利用SDN做的一个Cache。它的一个基本的模型如下所示,
... Our evaluation results demonstrate that SwitchKV can achieve up to 5× throughput and 3× latency improvements over traditional system designs.
0x21 基本思路
SwitchKV的基本思路是利用SDN来做作为Cache系统的一个部分,主要作用就是将客户端的get请求转发Cache的服务器,这里就有下面的一些问题需要处理,
-
交换机如何转发这些get请求的数据。在SwitchKV的模型中,它使用UDP协议作为get请求通信的方式。它利用了SDN。对数据包中的Mac地址。相关的Mac地址会以一个特点的Prefix开头,后面是这个Key的Hash值。可编程的交换机在发现了特定的Prefix开头的Mac地址的数据包之后,就可以根据情况转发这些数据包到Cache的服务器。另外,交换机负责可能被Cache的Key的鉴别,
... In most cases, queries sent to the cache node will hit the cache, because queries for keys not in the cache were filtered out by the switches. However, it is possible for a cache node to receive a get query but not find the key in its local in-memory store. -
Cache的节点在收到这样的请求之后。如果缓存命中,则可以直接返回客户端数据。如果发生了缓存不命中的情况,Cache节点就需要将这些数据包转发到后面的存储节点来处理。
-
而对于客户端会更改数据类似的请求,则交换机直接会将这些数据包转发到存储节点。后面的存储节点在回复客户端节点之前,会给Cache节点发送信息来将其Cache到的数据置为无效。这样对主要为读操作的场景比较适用;
SwitchKV要处理的另外的一个问题就是如何去更新这些缓存。在这里使用多种的策略和对个组件的支持,
-
周期性的更新热点Key,后端的存储节点会记录它认为的K个最热的数据,使用一种Time-segmented的方式来追踪最热的K个数据。这里”热度“的一个更新方式类似于TCP中的RTT的测量, \(\\ L_x = \alpha \cdot f_x + (1 - \alpha) \cdot L_x^{'}, \\ \text{Suppose the frequency of key x in the new segment is f_x , and the current load of x is L′x, then the new load of x is}.\) 这些信息会叫Cache节点用于更新缓存的数据。
-
处理突然变“热”的数据。上面的方法应对数据的突然变化的时候可以显得有些太迟钝了。存储服务器会使用一个很小的环形Log来记录少量Key的最佳的访问记录,根据这个里面的记录来分析突然变热的数据,
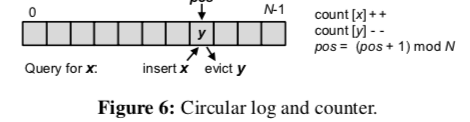
-
…
0x22 评估
这里的具体信息可以参看[3],

参考
- Scaling Memcache at Facebook, NSDI ‘13.
- HiKV: A Hybrid Index Key-Value Store for DRAM-NVM Memory Systems, ATC ‘17.
- Be Fast, Cheap and in Control with SwitchKV, NSDI ‘16.
