SifrDB: A Unified Solution for Write-Optimized Key-Value Stores in Large Datacenter
0x00 引言
这篇是很有意思的一篇Paper。SifrDB本质上还是一种在LSM-tree的优化,优化的重点在Compaction的方式上面。之前在LSM-tree上面存在多种的Compaction的方式,最常见的方式是Level-Style的方式,在LelvelDB和RocksDB中使用,这种方式的优化点事读取性能相对好一些。这种方式下面LSM-tree的每层的SST文件彼此Key不重叠,而对应的Tier的方式在每层的SST文件的Key事可能重叠的,Tier的方式写入性能更好一些,而读取性能更差一些,因为在一层读取的时候,每个SST文件都可能存在想要的Key。而SifrDB这里时提出了一种新的Compaction的思路。
0x01 基本思路
这里将Level-Style的方式称之为Tree-Model,而将Tier的方式称之为Forest-Model。Forst Model中,一个Key可能存在这一层的任意的SST文件中,这样的缺点就是很低的读取的性能。LSM-tree的设计本身就是针对写优化的一种,Forest-Model的设计更是加剧了读性能的恶化。针对这个缺点,这里的一种优化如PebblesDB一样,PebblesDB的优化实际上就是避免了一个Key可以存在一层的任意的SST文件中,而是限制在其中的一个范围内。这里的SifrDB实际上也是一种优化Tier Compaction方式的思路,只是优化的思路和前面的方式有些区别。
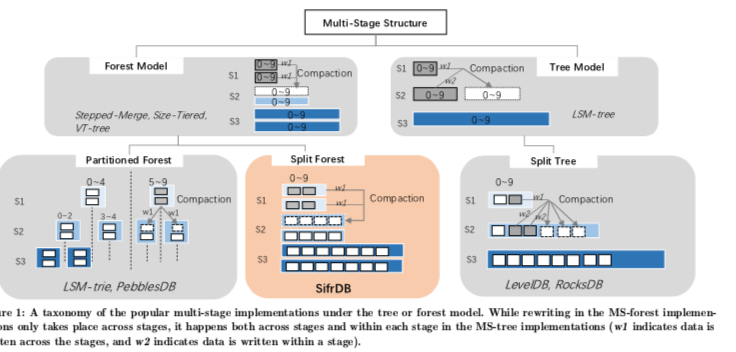
在SifrDB中Compaction思路可以从上图中看出来,可以看出来SifrDB归类到Forest-Model下面。这里将其称之为Split Forest Model。PebblesDB在这里被称之为Partitioned Forest Model。这里可以看作为在Forst Model中一层的一个部分有重新被划分了,方便更快的速度查找。在SifrDB中,每个Tree由一组没有重叠的固定大小的subtree组成,subtree的元数据信息保存到另外的一个全局的索引中。这样实际上就是组成了一个forest,也就是为什么称之为Foest Model的原因,PebblesDB和SifrDB的区别类似于一个事冲纵向上划分,而SifrDB是从横向上划分的。在这样的Model下面,Compaction操作思路如下图,
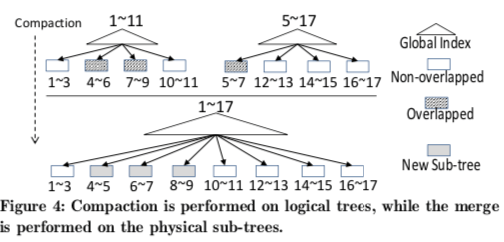
除了基本的思路之外,这里还提出了其它的一些优化思路,
-
early-cleaning优化思路,在Compaction的时候,常见的优化方式是在一个Compaction完成的时候才将原来的数据删除。这里的一个优化的思路是如何实现在一个数据Merge到新的Tree的时候,就马上将原来的数据删除。这样可以减少一些存储空间的消耗。这里的方式有带来两个问题要解决,1. 这样的方式在Compaction过程中的时候Crash了如何恢复,2. 这个过程中读取操作的时候如何处理读取的数据,因为一个Tree的数据可能位于新旧不同的位置。
-
上面的两个问题中,对于第一个问题,这里使用解决方式是Compaction Journal方式。在Merge操作的时候,会周期性地删除以及合并的数据。这个进度的信息会被写入到Compaction Journal中,在Crash恢复的时候可以根据这些信息恢复,根据Crash之前的记录的进度继续进行Compaction的操作,
In the recovery process, SifrDB reads the latest merge state information from the compaction journal and continues the compaction merge by seeking to the correct positions of the active input sub-trees, instead of the conventional approaches that simply discard the work that had been done before the crash. The correct positions are determined by the biggest key of the last newly persisted sub-tree. -
上面的第二个问题是使用Search Request Redirection解决,在Compaction操作的时候,在一个compaction journal提交的时候,更新一个redirection map中的信息。在这个map中记录了哪些数据被Merge到新的tree的信息。这种情况下,读取操作先检查这个redirection map。这里有一种情况需要处理,如果检查了这个redirection map之后,决定要去访问原来的tree,但是在去这个访问的过程中redirection map被更新,原来tree的中数据被删除。为了解决这个问题,这里使用的方式是twice check方式。在第一次查询redirection map的时候,决定去访问原来的tree,会先去标记这个sub-tree,然后再次检查redirection map,删除操作的时候不会讲打上tag的删除,
After the second check, if the search process is instead redirected by the promptly updated map to access the new sub-tree, the original sub-tree can be un-tagged and deleted without trouble. Otherwise, since the search process still decides to access the original sub-tree according to the redirection map,... -
Parallel Search for Read,这里就是一种并行查询各个tree的优化,这里在一些情况下吗可能可以提高性能,但是会消耗更多的资源,
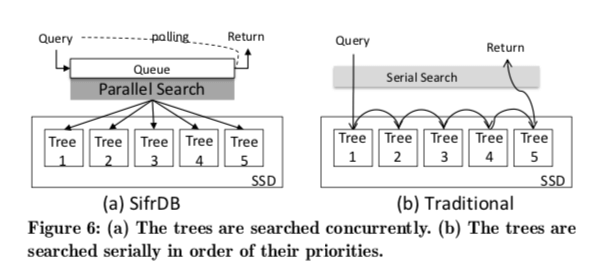
0x02 评估
这里的具体信息可以参看[1].
##Mutant: Balancing Storage Cost and Latency in LSM-Tree Data Stores
0x10 引言
这篇Paper讲的也是关于LSM-tree的一些优化。和前面的Paper的思路不同,这里的出发点是优化LSM-tree的使用成本。在LSM-tree,数据存储在SST文件之中,在实际的Workload中,数据访问都是很不均匀的。SSD、HDD以及新型的非易失性的内存的价格差距很大,如果将访问频繁的数据放到更快的存储介质中,将访问不频繁的数据放到速度慢一些但是价格更低的存储介质中,可以获得更好的性价比。这篇Paper的核心内容就是如何实现这样的功能。
0x11 基本思路
在这篇Paper之前,基于数据访问不均衡来优化LSM-tree性能和成本的思路也有一些。比如,1. 将更小的Level放到更快的存储介质上面,因为更小Level的数据一般范围的频率更加高,2. 类似于Splay Tree的思路,将最近访问的数据转移到到内存Memtable中,转移到其它更快的存储介质中也是可以的。第一个思路的缺点是粒度太粗了,这能从Level基本去控制,第二个的就是类似于一个缓存的功能。这里的思路是冲SST文件的粒度出发。将Pf定义为快速存储介质的价格,Ps定义为慢速存储介质的价格,当然这里引入更多类型的存储介质也不是很困难的。Sf和Ss分别对应保存在快速存储介质和慢速存储介质上面的SST文件的分别的总的大小。Cmax代码const buget,对于给定的Sf,这里需要求解(3), $$
- P_fS_f+P_sS_s \leq C_{max}, 2. S_f+S_s=S \
- S_f \lt \frac{C_{max}-P_SS}{P_f-P_s} = S_{f,max}
\(使用Ai表示访问SST文件i的次数,Si表示SST文件i的大小,xi表示SST文件i是否保存在快速存储介质中。这里的问题可以表示为下吗的数值优化问题,\)
\max \sum_{i∈SSTables}A_ix_i
s.t. \sum_{i∈SSTables}S_ix_i\le S_{f,max} \ and \ x_i∈{0,1}. \(这里这样就可以看作是优化一个0/1背包的问题。0/1背包是一个NP问题,但是解决这个问题/近似解决这个问题的算法也很多。关于如何解决0/1背包问题的算法可以参看相关的文章。SSTable Temperature是这里用来形容一个SST文件热点的一个概念,这里先简单的使用一个计数器来记录访问的次数,但是这样的一个问题是收到一些其它因素的影响到判断SST文件到Temperature: 不同大小的SST文件、访问频率的波动。这里使用一种 exponential average,指数平均?的方式来定义Temperature。Temperature定义为单位大小内过去的一段时间的访问情况,访问统计会随着时间指数递减,这里和其它的很多算法中的思路类似,\) T_t = \left{ \begin{array}{ll} (1-\alpha)\cdot\frac{A_{(t-1,t]}}{S} + \alpha\cdot T_{t-1}, & t>1
\frac{A_{(t-1,t]}}{S}, & t = 1. \end{array} \right. $$ 这里T_t表示t时刻的Temperature,A(t−1,t]表示(t−1,t]时间内的访问情况,S为SST文件的大小,α为(0,1]范围内的一个值。在API上面,统计了不同存储介质类型以及成本的选项。在实现的时候如何减少数据迁移给系统带来的影响估计比较重要。
Options opt; opt.storages.Add(
"/mnt/local−ssd1/mu−rocks−stg", 0.528,
"/mnt/ebs−st1/mu−rocks−stg", 0.045); DB::Open(opt);
DB::SetCost(0.2);
// Mutant API:
// Initialization
void Open(Options);
void SetCost(target_cost);
// SSTable temperature monitor void Register(sstable);
void Unregister(sstable);
void Accessed(sstable);
// SSTable organization
void SchedMigr ();
sstable PickSstToMigr (); sstable GetTargetDev();
0x12 评估
这里的具体信息可以参看[2].
##TRIAD: Creating Synergies Between Memory, Disk and Log in Log Structured Key-Value Stores
0x20 引言
这篇Paper也是在LSM-tree上面的一些优化操作。和前面的两篇Paper不同,这篇Paper上面的优化在实际中得到了应用,所以这篇Paper中描述的优化策略可能有更大的应用价值。TRIAD涉及到的一些优化措施主要包括:Memtable Flush的时候的一些优化,L0和L1 Compaction的一些优化,以及将Log当作SST文件的一些优化方式等,
... With these workloads, TRIAD yields up to 193% improvement in throughput. It reduces write amplification by a factor of up to 4x, and decreases the amount of I/O by an order of magnitude.
0x21 基本思路
Paper中先分析了目前的Key-Value Store中存在的一些问题,1. 实际的很多应用场景中,数据之间的访问频率相差是很大的。在LSM-tree中,频繁地更新少量的热点数据集合造成的一个问题是增加内存中数据的Flush操作,而且Flush之后由于数据位置改变,对性能造成不利的影响。2. 不合适的L0设计造成太频繁的L0写入操作,这里主要涉及到如何在合适的时候进行L0和L1的Compaction操作。3. 写Log和写Memtable操作的重复写入。
-
TRIAD-MEM,这里主要是优化上面提到的第一个问题。这里将内存中的数据分配hot和cold的两个部分。在Memtable Flush到磁盘上面的时候,只会将Cold的部分刷入到磁盘上面,而hot的部分会继续保存到内存中。这里选择的策略是选择其中的top-K个。设计到这部分的优化的伪代码如下。这里cold数据和cold数据分为不同的路径处理,hot数据也不会完全不会写入到磁盘,而是写入到new log中,这里和后面的将log作为SST范围的优化也对应。
Memtable hotMem = new Memtable() Memtable coldMem = new Memtable() separateKeys(mem, hotMem, coldMem) setCurrentMemtable(hotMem) CommitLog newLog = new CommitLog() // Write back hotMem entries to the new log populateLog(newLog, hotMem) // hot数据在new log中也会保存一份 setCurrentCommitLog(newLog) // Update hotMem with offsets from new CL CLUpdateOffset(newLog, hotMem) // Extract index corresponding to cold keys CLIndex index = getKeysAndOffsets(coldMem) //Flush only index and link it to old CL flushToDisk(index, log) -
TRIAD-DISK,这里发出L0、L1的Compaction操作的时候,只会在L0和L1有足够数量的overlap的Key的情况下。否则就是延迟触发Compaction操作。这里使用HyperLogLog (HLL) 的数据结构来策略两个Level之间的overlap ratio,这里将其定义为(UniqueKeys( file-1, file-2, . . . file-n)) / sum(Keys( file-i)),
Assuming we have n files on L0, the overlap ratio is defined as 1 - (UniqueKeys( file-1, file-2, . . . file-n)) / sum(Keys( file-i)), where Keys( file-i ) is the number of keys of the i-th SSTable and UniqueKeys is the number of unique keys after merging the n files. UniqueKeys and Key( file-i ) are approximated using HLL.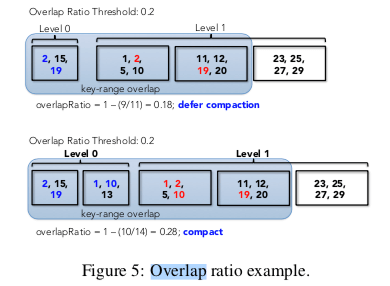
-
TRIAD-LOG,这个是一个比较有意思的一个优化方式。一般的LSM-tree实现中,Memtable刷入到磁盘之后,对应的WAL部分就可以舍弃了。这个是很通用的一个方法,但是带来的问题就是数据的重复写入。这里的策略就是将LOG作为一种特殊类型的SST文件,CL-SSTable。在刷入Memtable的时候,就不需要将整个的Memtable刷到磁盘上面,只需要对Log进行转化操作,添加Index等信息。这里要处理的一个问题是Log中的数据是无序的,这样在查找的时候可能带来一些性能的降低。
0x22 评估
这里的具体信息可以参看[4].
参考
- SifrDB: A Unified Solution for Write-Optimized Key-Value Stores in Large Datacenter, SoCC ’18.
- Mutant: Balancing Storage Cost and Latency in LSM-Tree Data Stores, SoCC ‘18.
- Scaling Concurrent Log-Structured Data Stores, EuroSys ’15.
- TRIAD: Creating Synergies Between Memory, Disk and Log in Log Structured Key-Value Stores, ATC ‘17.
