Reducing DRAM Footprint with NVM in Facebook
0x00 引言
这篇Paper是关于Facebook在自己的数据库中使用NVM的做法,一个叫做MyNVM的系统。虽然整体上和现在很多的在NVM上面的数据库的研究有很大的不同,Facebook这里主要利用NVM来减少数据库中DRAM的使用。基本的思路就是引入部分的Buffer Pool的数据放到NVM上面,形成了一个两层的Buffer Pool的设计。
... Our implementation reduces the size of the DRAM cache from 96 GB to 16 GB, and incurs a negligible impact on latency and queries-per-second compared to MyRocks. Finally, to the best of our knowledge, this is the first study on the usage of NVM devices in a commercial data center environment.
0x01 背景
NVM的特点使得它在数据库的上面的应用有巨大的前景。相对于针对NVM新设计的数据库系统而言,这里Facebook利用NVM改进MySQL的方法能够更快地在实际环境中得到应用。在Facebook的尝试中,通过16GB内存加140GB NVM的方法替换了96GB内存的设计,在降低了很大成本的同时,依然保存了和完全使用内存差不多的性能。

虽然NVM能够提供比一般的SSD更高的性能(虽然目前实际上应用的NVM的性能没有比高端的SSD性能高上多少,不过估计以后提升的潜力更大)。下面是DRAM、NVM和TLC Flash性能比较的一个表格。NVM的性能和DRAM之间的性能差距还是比较大的。如果要将NVM引入到MyRocks中(Facebook使用的MySQL版本)中,由于这里的目标就是保持性能、平均延迟、P99延迟和QPS基本保持和使用内存版本的系统,这里的性能“Gap”的问题必要要解决。
| 性能指标 | DRAM | NVM | TLC Flash |
|---|---|---|---|
| MaxReadBandwidth / MaxWriteBandwidt | 75 GB/s / 75 GB/s | 2.2 GB/s / 2.1 GB/s | 1.3 GB/s / 0.8GB/s |
| Min Read Latency / Min Write Latency | 75 ns / 75 ns | 10 μs / 10 μs | 100 μs / 14 μs |
| Endurance | Very High | 30 DWPD | 5 DWPD |
| Capacity | 128 GB | 375 GB | 1.6 TB |
Facebook做了一个简单的实验,将96GB的内存减少为16GB,发现平均延迟增了了2x,P99延迟增加了2.2x。Paper中总结使用NVM代替DRAM会带来的几个问题,
-
NVM目前的性能还是很明显地低于DRAN,而且它的带宽表现受Block的大小影响很大。NVM随机性能和顺序性能和DRAM随机性能和顺序性能之间的特点是不一样的。
-
减少了DRAM的容量之后,因为着更小的索引的数据可以直接保存在内存中,这里需要多索引进行改进。
-
MyNVM使用更小的Block来使用NVM的性能特点,这样带来的一个问题就是减小了数据压缩的比率,增大了实际保存数据的大小。
-
NVM虽然耐用性比SSD好上很多,但是也不是和DRAM一样几乎可以认为无限的Endurance,它还是有一个Endurance的限度了。如何和DRAM一样使用,可能很快消耗NVM的耐用度。
-
NVM的延迟比其它的块存储设备的延迟低了很多,这里如果使用中断的方式就会带来明显的开销,
Fourth, because NVM has a very low latency relative to other block devices, the operating system interrupt overhead becomes significant, adding a 20% average latency overhead.
针对上面要解决的问题,Facebook的MyNVM解决方案提出了一下的一些方法:使用更小的Block,使用分区的索引,利用Directory Compression,让只有命中率高的数据才会保存到NVM中,混合使用中断和轮询机制等。
0x01 基本思路
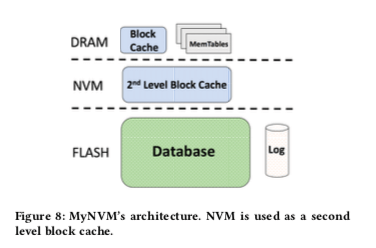
MyNVM是基于Facebook使用的MySQL版本MyRocks实现的。底层使用的存储引擎是RocksDB。在设计MyNVM之前,这里先对NVM的性能特点进行了大量的测试,这些测试的结果直接影响了MyNVM的一些设计:延迟(Latency),带宽(Bandwidth),耐久性(Durability)。MyNVM是下图一样的两层设计,NVM作为第二层的Block Cache。MyNVM使用DRAM作为一个频繁访问Block的写直达的Cache,NVM同样使用写直达的机制。不过这里容量明显大于DRAM的消息,这里DRAM的大小为16GB、NVM的大小为140GB。两层都使用LRU的缓存替换算法。
MyRocks使用的默认的Block的大小为16KB。如果一次性读取的数据比较少,较大的Block就会带来更大的读放大。而未来利用好NVM的带宽,这里将Block的大小减少为4KB,依此来达到读放大的目的。不过这样直观的做法反而使用需要的读取的带宽增大了不少,如下图说。这样的主要的原来来自于减少Block的大小之后,索引的大小显著增大。这样工作的时候需要读取更多的索引,造成了读取带宽反而增大。在底层使用的RocksDB中,原来一个SST文件中的一个Index Block作为整个SST文件的索引,读取这个这样完整的索引在很多的时候是没有必要的。这里MyNVM映入Partition索引,Partition索引上面是一个Top Level的索引,实际上就是一个两层的索引结构(这种思路也被用在使用较大的SST文件的时候索引Block比较大的问题)。
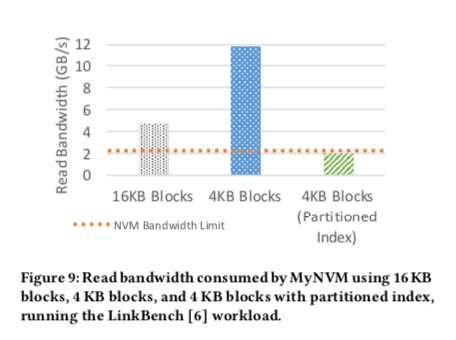
如下图所示,现在一个Partition索引之后索引一个SST文件中的部分数据,使用Top Level的索引找到对应的Partition索引。这样的结果对降低读带宽很明显,如上如所示,大概读带宽降低带来原来的1/6。

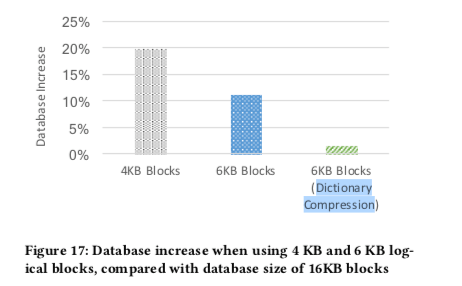
MyNVM这里使用的NVM还是使用Page为单位来管理数据。一般的Page大小都为4KB,而MyNVM在保存数据的时候会对数据进行压缩。这样的话如果直接使用4KB的Block大小,保存到NVM上面的时候,实际的的大小就不足4KB,但是保存的时候还是会消耗4KB。这里MyNVM就使用6KB的大小,这样的大小一般压缩之后大小在4KB左右。对于小于4KB的情况,就使用填充的方式。对于压缩之后数据大于4KB的情况,就跨页保存。另外的一个问题就是降低了Block的大小之后,压缩的比率降低了不少,在下图中,4KB大小比压缩速率减少了将近20%,6KB大小减少了约11%。未来缓解这个为题,MyNVM这样引入了Dictionary Compression,这样压缩率的减少就很小了,
在MyNVM中,内存中缓存的Block都是没有压缩的,而在NVM和Flash上面保存的数据都是压缩之后的Block。IO上面都是使用的Direct IO,不实用OS提供的Page Cache。在查找的数据的时候,MyNVM首先访问的是DRAM,如果DRAM中不存在,则再去查看NVM。但是在两个地方缓存缺失的时候,数据不会马上被缓存到NVM中去,这里就是为了避免非常频繁写NVM,降低其寿命。写入NVM以128KB为单位,追加到NVM中缓存的文件后面,
... Writes to NVM are done in batches of at least 128KB, because we found that smaller write sizes degrade the achieved read bandwidth. Cached blocks are appended into larger NVM files with a configurable size.
NVM中的缓存算法以其中的文件为单位,缓存驱逐的时候,就直接删除最老的文件。
0x02 优化
在MyNVM基本架构的描述下面,NVM实际上就是作为一个二级的Cache层使用。就是简单地作为一个Cache层,使用和DRAM一样的算法策略的话,会很快消耗完NVM的写入寿命。MyNVM这里的解决方式就是只将可能被频繁访问的数据才Cache到NVM上面,这样的话不要频繁地淘汰数据、写入数据。具体的做法就是在DRAM中LRU链表保存最近访问Block的一些信息,只有在最近访问了的Block才会被Cache到NVM上面。越多的Cache的数据,需要更加大的读写带宽,在NVM Cache增大到一定程度之后,继续增大能够获取的效果就很小了。在Paper中的测试数据中,这个大小大约在30 - 40GB左右。另外MyNVM还引入了其它的一些优化措施,
-
MyNVM这里还是将NVM设备作为一个块设备使用。由于NVM的高性能,传统的使用中断的方式会带来不小的开销,但是完全使用轮询的方式会带来很大的CPU负载。这里MyNVM的t讨论了一种混合中断和轮询的方式。首先的思路是没睡眠一段时间才轮询操作,采用固定的睡眠时间灵活性不高,这里就提出一种根据前面的平均的IO延迟动态设计睡眠时间的方法。但是这里的一个问题就是轮询在线程数据比较小的时候效果很好,但是线程处理比较多,比如8个以上的时候,能够获取到的效果就差了很多,
One is that as more threads are accessing the device, the individual I/O latencies start to increase,... Secondly, as more threads are running in the system, there’s a higher chance that a CPU will have pending work outside of the thread submitting I/O. ... Thirdly, as more threads are polling for IO completion, the polling overhead becomes larger.
在Paper中提到,MyNVM没有还是没有将轮询的方式采用带生产环境,但是作为未来工作计划的一部分。
0x03 评估
这里的具体信息可以参看[1].
参考
- Reducing DRAM Footprint with NVM in Facebook, EuroSys ’18.
- Memory Management Techniques for Large-Scale Persistent-Main-Memory Systems, VLDB ‘17.
