Memory Management Techniques for Large-Scale Persistent-Main-Memory Systems
0x00 引言
这篇Paper是关于SAP在其数据库系统中为Storage Class Memory (SCM),即一种非易失性内存,设计的内存分配器。这里设计的PAllocator是目前少数在实际系统中使用为非易失性内存分配器。这SCM的内存分配器设计中,主要要解决这样的几个问题,
- 数据一致性,这个原因在很多的NVMM系统中都是要考虑的问题,主要的原因是可能最新的数据还没有达到SCM中,还只会存在CPU的缓存中,如果这个时候发生系统Crash,就会导致系统一致性的问题。在interl的CPU中,也提交了如CLFLUSH这样的之类来解决这个问题。
- Data recovery,数据恢复是一般的内存分配器不用考虑的事情,很显然一般的DRAM在断电之后数据全部丢失,不存在Data recovery的问题。但是SCM作为非易失性的内存,则希望系统重启之后还可以恢复到重启之前的状态。
- Persistent内存泄露,SCM持久化保存数据的另外一个问题是可能导致永久性的内存泄露。
- Partial writes,不如一般的块存储设置,这些块存储设备一般可以支持一个block的原子写入。而SCM只支持8byte的原子写入or读取。如果需要原子写入超过了8byte的数据,则可能存在不会写入的问题。
- 内存碎片,Persistent内存里面的数据保存时间一般都会超过DRAM中数据保存的时间,这样的情况下吗其内存碎片的问题会变得更加严重。地址空间碎片。目前Linux 支持的用户空间的最大空间为128TB,但是可能无法满足之后要求。但是这里由于Linux新版本支持了5级的页表。这个问题问题不大。
0x01 基本设计
首先,PAllocator基于文件系统的DAX,即直接范围存储介质的空间。这样这些SCM实际上还会对应到文件。PAllocator还有这样的一些设计:1. 使用多个文件而不是单个,方便增加和减少资源。但是为了避免使用太多的问题,这里使用大文件来限制文件的数量。2. 对于small、big和huge等不同尺寸的内存块分配,使用不同的分配策略。3. 不着急释放空闲的文件,用于加速可能的未来的分配,这个策略在一些通用的内存分配器上面也使用了。4. 不实用线程局部资源池的方式,而是每个CPU物理核心一个allocator的方式。还有另外一些设计等等[1]。PAllocator不是一个通用的内存分配器,由于SCM实际上还是文件系统管理的,这里使用一种persistent pointers来寻址。PAllocator也使用下面的两个基本class,一个PPtrBase表示一个没有类型信息的地址信息,PPtr则会带有类型信息。
class alignas(16) PPtrBase {
uint64_t fileID;
ptrdiff_t offset;
void* toPtrBase(); // Swizzling function
};
template<typename T>
class PPtr : PPtrBase {
T* toPtr(); // Swizzling function
template<typename U>
PPtr<U>& as(); // Cast function
};
allocate(PPtrBase &p, size_t allocationSize);
deallocate(PPtrBase &p);
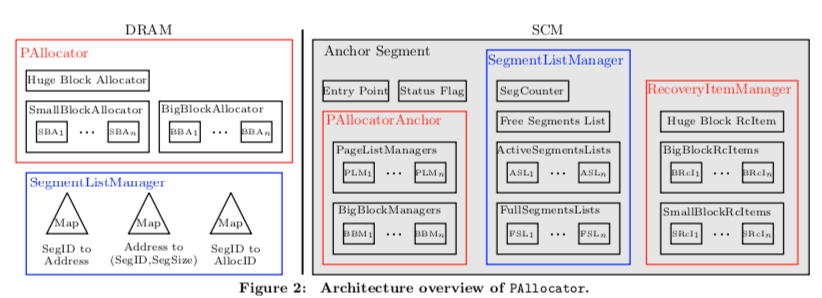
Allocator保存在DRAM中,根据分配对象的大小分为三种类型,SmallAllocator分配在[64 B, 16 KB)之间的对象,BigPAllocator分配[16 KB, 16 MB)之间大小的对象,HugePAllocator分配16MB以上的对象。为了优化多核下面的分配性能,这里对于Small和Big的分配器都是每个CPU核心一个,由于分配超大对象的频率不会很多,所以这里就使用一个的Huge分配器。每个文件这里称为一个segments,Huge对象分配会每个对象分配一个segment。另外,
- 为了可恢复,PAllocator维护来一个特殊的segment,Anchor Segment,里面保存了用于恢复的必要的一些元数据。对于每一个SmallPAllocator和BigPAllocator,在PAllocatorAnchor中维护了一个PageListManager (PLMi ) and one BigBlockManager (BBMi )。为了分配和释放内存的原子性,这里利用了micro-logs。这个micro-logs中,包含了Recovery Items。RecoveryItemManager负责管理这些数据。
- SegmentListManager用于管理Segment。一部分保存内存中个,一部分保存在SCM中。对于保存在SCM中的持久化部分,维护了一个全局的segment counter,一个空闲segment的list。对于每个SmallPAllocator,维护了一个active segments (ASLi)的list和一个full segments (FSLi)的list。对于DRAM中的部分,包含了这样的一些内容,1. SegIDToAddress,用于segment ID映射到虚拟地址,2. AddressToSegInfo,将虚拟地址对应到segment的ID和segment的大小,3. SegIDToAllocID,SegmentID到Allocator ID的映射。
SmallPAllocator
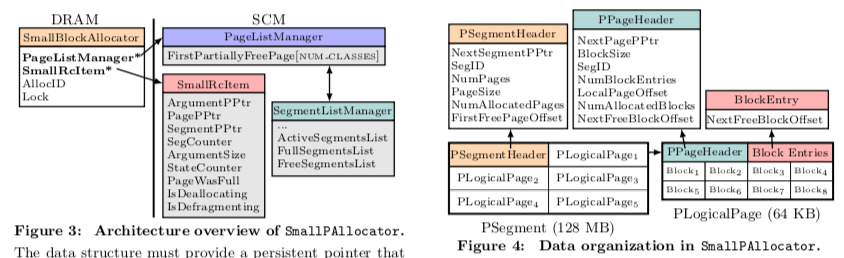
和想jemalloc中的思路一样,这样也是将分配对象按照大小分为多个种类型。这里从64 B 到 15 KB 分为了 40个等级。分配的对象从64B起步,每次分配都保持Cache-Line对其,可以避免一些伪共享的问题。特别是在SCM这样的环境中,由于经常需要刷缓存行,这个缓存行对齐的设计是很有必要的。其中有两个重要的结构PageListManager和SmallRcItem,前者包含一个指向还有没有分配空间的Page的persistent pointer的指针,每个指针指向的是一个按照对象大小分的等级。这里通过和SegmentListManager交互来获取空闲的Page和释放Page。SegmentListManager为每个SmallAllocator一个,这里会按照Segment中空间的使用情况分为ActiveSegmentsList 、 FullSegmentsList和FreeSegmentsList。SmallRcItem用于分配和释放内存的时候保证原子性。
- SmallAllocator中,每个Segment大小为128MB。Segment又被分为64KB大小的logical page。第一个Page作为 segment header,Sengment之间通过NextSegmentPPtr指针来组成一个list。分配同样大小对象的Page通过NextPagePPtr组织为list。前一个list的head保存在SegmentListManager中,而后一个list的head保存在PageListManager中。Page被划分为等大小的block,对应到前面的对象大小的等级。这里一个Page为每个block保存一个2byte大小的BlockEntry,用来追踪下一个空闲block的偏移,这样这里实际上也组织为一个list,head保存在page header的NextFreeBlockOffset中。
- 以分配一个Small对象范围内的对象为例,这里对象的大小会先把计算到大于等于这个对象大小的预定义的尺寸。然后PageListManager检查这里是否存在这个尺寸的可以用来分配的空间。这种情况下,通过NextFreeBlockOffset获取到最近的空闲block。这里实际上就会相当于一个list pop出最前面一个entry的操作。如果没有空闲的空间,就需要分配另外的一个空闲的Page,通过SegmentListManager来分配。
BigPAllocator
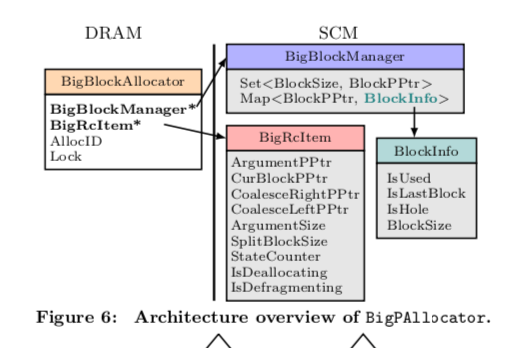
BigPAllocator的设计和Small的不同,它是一种基于树的best fit的分配策略,用于分配16 KB 到 16 MB 大小的对象。为例方便去碎片,这里分配的对象都是Page Size对齐的。其中两个主要的结构是BigBlockManager和BigRcItem,后者是一个128byte大小的对象,用于保证BigPAllocator这里操作的原子性。BigBlockManager用于维护这里的内部结构,主要是两个树结构,一个Free blocks tree,保存Block Size到其指针,另外一个BlockInfo tree负责将BlockPPtr映射到其Block的信息。
0x02 碎片化 和 Recovery
去碎片这里有不少的细节,这里只关注去碎片的主要部分。在需要进行去碎片操作的时候,在free blocks tree中找到最大的free block,这里利用了文件“打洞”的功能。在fallocate中,组合FALLOC FL PUNCH HOLE和FALLOC FL KEEP SIZE两个flag使用的时候,会释放以offset开始,后面len范围内的磁盘块。为了去碎片,这里要将分散的空闲的空间重新组织为一个大的空间。前面利用fallocate中,组合FALLOC FL PUNCH HOLE和FALLOC FL KEEP SIZE两个flag释放磁盘块的时候,会去查找其前后的Block,如果也是空闲的,会进行合并的操作。多个Free Block合并为一个大的Free Block。这些信息会在BlockInfo中记录。
Recovery
恢复的话,主要是恢复之前保存在DRAM中的一些结构,如最前面的图所示。在初始化一些信息之后,通过已知的信息重建SegmentListManager中的SegIDToAddress 和 AddressToSegInfo信息。之后重建分配器对象,并调用其recovery函数使其恢复到一个一致的状态,BigPAllocator重建的时候还需要恢复其中的tree结构。SegIDToAllocID通过如下的方式恢复,
1. 使用的segemnt在开始的时候都分配到 HugePAllocator。
2. 扫描每个SmallPAllocator的SegmentListManager中active segments list和full segments list,恢复segemnt的归属信息。
3. 通过扫描leaf node来恢复hybrid tree,
4. FreeSegmentsList不属于任何一个Allocator。
5. 没有处理完的就是HugePAllocator的。
恢复操作这里细节比较多TODO。
0x03 评估
这里的具体信息可以参看[1].
Managing Non-Volatile Memory in Database Systems
0x10 引言
NVM硬件非易失性的特性和很高的性能对数据库的设计肯定会有很大的影响。直接使用NVM代替一般的SSD、HDD之类的块存储设备很难利用好NVM自身的特性。直接使用NVM代替内存有由于NVM的性能还是比不少DRAM的,这样会导致系统性能的降低。这里为了解决这些问题,
0x11 基本思路
NVM可以支持字节寻址,而且延迟比SSD这样的存储设备低很多。直接和SSD一样使用完整的Page操作很难利用NVM的这些能力。这里提交的方法是Cache-Line粒度加载的策略。这样就不仅仅可以实现只将一个Page中热点的数据加载到内存,而且可以减少很多NVM带宽的使用。这个具体的做法如下,
-
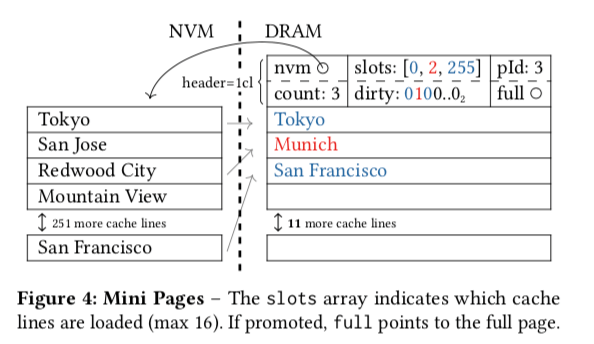
在DRAM中分配一个Page的空间的时候,不会一开始就将对应Page所有的内容都加载到内存中来。在Page的header中,维护了一个bitmap来标记这个Page中对应的Cache Line是否已经加载到内存中了。基本的结构如下图所示。同样地思路,标dirty的一个bitmap用于标记一个Cache Line数据已经被修改,但是还没有同步到持久化的存储设备上面,这里就是NVM设备。在使用16KB Page大小的时候,就是256个Cache Line。这里的bitmap加上其它字段一共使用了 nvm + pId + r + d = (8 + 8 + 1 + 1) byte = 18 byte的空间,只是很小的一点空间,整个header使用了(2 ∗ 32 + 18)byte = 82 byte,可以放入两个Cache Line中。 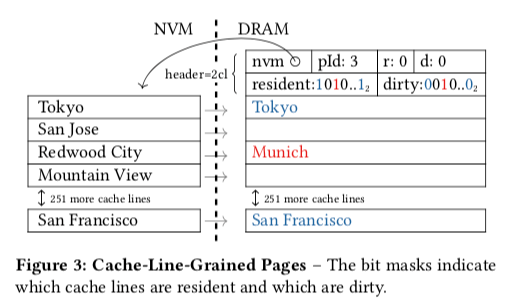
-
仅仅是使用Cache Line加载的方式,在分配内存中空间的时候,还是要分配一个完整的Page的空间。为了减少这里不必要的内存使用,提出了一个Mini Page的方式。存在这样问题的原因就是内存中Page结构和NVM中Page的结构是对应的关系。这里就使用一个slots结构来解决这个直接对应的关系,转而使用间接对应的方式。其实这里的思路就是通过一个slots数组来记录NVM中一个CacheLine的数据对应到内存中那一个Cache Line。这里还有更多的细节。
- Pointer Swizzling用来解决在查找一个Page的时候,一般的方法是使用Page ID在一个Hash Table中查找。但是这样会带来一些开销,如果在把ID 和 Addr编码在同一个字段中,就可以解决这个问题。由于现在的指针和ID一般都不会使用全部的64的bit,使用其中的1个 or 几个作为flag即可。
0x12 三层Buffer设计
在前面管理NVM的方法之上,加上一般的SSD,形成了如下图所示的三层的Buffer结构。在这样的设计中,buffer管理在NVM和DRAM两层中完成。Page只会在DRAM中被访问,DRAM和NVM都是缓存SSD中Page的一部分。在驱逐内存中一个Page的时候,根据情况将其驱逐到SSD中 or NVM中。为了定位NVM中Page的位置,同样需要一个Page Table,这里可以将DRAM使用的Page Table和NVM使用的合为同一个,减少查询table的次数。
- 这里恢复机制就是一般的ARIES风格的WAL机制。但是NVM中的数据在重启的时候是可以重新使用的,这个加快了重启的速度,可以避免一部分的redo操作。也可以避免一开始的时候Buffer中完全没有数据。
- 一个Page在3层设计中处理的基本过程如下,新Page从SSD中Load的时候,加载完整的Page。因为SSD的特性没必要使用前面NVM的机制。这里刚开始也不会将其放入NVM中。当Page从DRAM中被驱逐出去的时候,可能会被选择保存到NVM中。内存中Page替换使用常见的clock替换算法。通过利用ARC缓存替换算法中的思路,来辨别”暖“的Page,如果被认为是”暖“的Page,则被保存到NVM中,否则驱逐到SSD中。NVM中保存的数据也使用clock算法来作为驱逐策略。
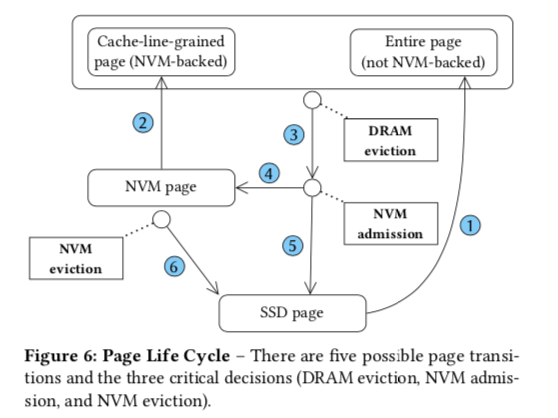
- 这里的page mapping table即负责Page ID到内存位置的映射,也使用Page ID到NVM位置的映射。在recovery的时候,这里会重建这个page mapping table。通过在restart的时候扫描所有的Page来重建。
0x13 评估
这里的具体信息可以参看[2].
参考
- Memory Management Techniques for Large-Scale Persistent-Main-Memory Systems, VLDB ‘17
- Managing Non-Volatile Memory in Database Systems, SIGMOD ‘18.
