Rocksteady: Fast Migration for Low-latency In-memory Storage
0x00 引言
RAMCloud是有名的一个内存存储系统。围绕着RAMCloud的论文有很多。Rocksteady是关于如何实现RAMCloud快速数据迁移的,Arachne是使用在RAMCloud上的一个用户空间的线程库。Rocksteady是一种Zephyr风格的live migration方式,在RAMCloud的实现中,可以实现758MB/s的迁移速率,
Rocksteady migrates 758 MB/s between servers under high load while maintaining a median and 99.9th percentile latency of less than 40 and 250 μs, respectively, for concurrent operations without pauses, downtime, or risk to durability (compared to 6 and 45 μs during normal operation).
0x01 基本设计
为了实现高速地数据迁移和保持top999依然保持在一个很多的水平(只有几百微妙的水平),Rocksteady对迁移方式有着这样的节几点的思路,1. 不能是同步的重新复制,2. 立即的数据所有权的转移,3. 在源节点和目的节点都并行处理,4. 自适应的load 处理。Rocksteady使用完全异步的方式进行数据迁移。另外继承了RAMCloud中使用Kernel Bypass的网络栈和scatter/gather DMA等技术实现zero-copy。另外,Rocksteady还使用流水线以及自适应并行度的方式来实现更好的迁移效果。
- 总体来看,Rocksteady中的数据迁移有目的地驱动。在由于负载均衡导致的数据迁移中,源节点很可能已经处理比较高的负载的状态,这个时候给源节点更多的工作只会加重目前的负载不均衡。
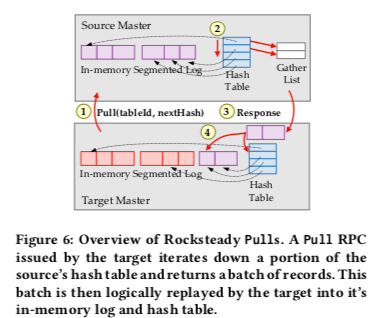
- 下图基本表示来Rocksteady Pull处理数据迁移的过程,目的简单以流水线的方式异步地使用Pull RPC从源节点拉去数据。源节点迭代式地批量的将数据回复给目的节点。这里为了实现zero copy,直接向传输层传递数据的地址的信息,而传输层直接使用地址获取数据,直接使用DMA传输。传输过来的数据会被记录到目的节点的log里面和保存到hash table里面。
- 为了初始化一个迁移操作,目的节点使用MigrateTablet RPC来启动迁移操作。这个操作会使得一个tablet的数据所有权转移到目的节点。关于这个部分数据的请求都将有目的节点来处理。对于写操作,目的节点就可以直接处理,而如果处理的是一个读操作,而且这部分的数据还没有同步过来,目的节点使用一个PriorityPull RPC直接将需要的数据拉去过来。由于在很多应用场景下面,数据访问都是不均匀的,这种方式能很好地使用这样的workload。
Task Scheduling, Parallelism, and QoS
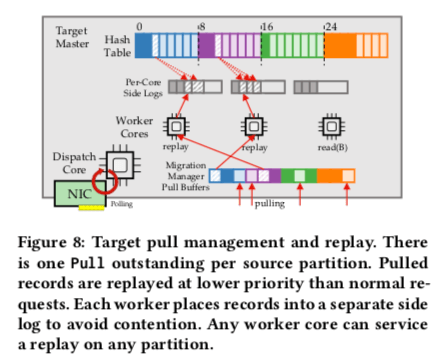
Rocksteady中Scheduling的目的是为了尽可能地让目的节点忙碌,但是又不能让源节点过载。在RAMCloud中,任务处理使用的是dispatch/worker模型,dispatch线程会轮询网络请求,在收到请求消息之后,将请求转发给一个空闲的worker现场,如果此时没有空闲的worker现场,在进入一个队列等待处理。排队的时候会有一个对应的优先级。
-
在数据迁移的时候,源节点的目的就是处理Pull和PriorityPull的RPC请求。Pull一个固定范围的设计不是一个很好的设计,因为这个范围内的数据有很多的不确定性。这里使用的是一次Pull固定大小的数据的做法。这个数据的大小要求不能太大占据太多了源节点worker现场太多的时间,也不能太小,以免太多的Pull RPC请求带来了更大的开销。使用固定大小数据的缺点就是不能很多并行处理,因为要等上一次迁移完成之后才知道下一次数据迁移来时的地方。
-
为了处理这个问题,目的节点逻辑上讲源节点对应的hash key space划分为一定数量的partition。发给不同的线程来处理。为来实现更好的SLA,Pull RPC请求一般会是一个比较低的优先级。源节点可以将其作为一个后台任务处理,以免影响到正常的请求。但是对于PriorityPulls,就会给一个比较高的优先级。
-
对于迁移数据中的源节点,它是无状态的。只会处理简单的Pull和PriorityPull请求,而不会理解数据迁移的情况。这部分的工作都交给目的节点来处理。在数据迁移开始的时候,源节点树木的Migration Manager讲数据划分为Partition。每个Partition分别处理。通过异步的Pull RPC来去数据,拉去到数据之后,将记录将给一个空闲的Worker。然后启动一个新的Pull请求。如果此时没有空闲的Worker,将暂停一下Pull RPC请求。
-
请求来的数据会被并行的reply到源节点的Hash Table。由于不同的Worker拉取的树属于不同的hash key space,并行reply的时候很少会产生contention。
-
除了将数据写入到目的节点的Hash Table。这里数据还会被写入到log。同样地,为了减少contention。Rocksteady使用per-core的side logs来写入日志记录数据。在迁移完成的时候,这些side log也被提交到main log中,直接只是通过添加一些元数据来进行提交到main log的操作,而不会直接去拷贝数据。
-
Rocksteady利用Modern NIC简而言之就是利用好NIC的scatter/gather DMA功能,
it uses scatter/gather DMA when supported by the transport and the NIC to transfer records from the source without intervening copies. Rocksteady’s implementation always operates on references to the records rather than making copies to avoid all unnecessary overhead.这种优化最好去看看源代码了解了解是如何实现的。
Priority Pulls是另外一个重要的部分。与前面的Pull请求不同,Priority Pull请求会指定要来去的Key的Hash。为了避免同步的Priority Pull带来的Worker线程stall和上下文切换。但是异步地处理方式有不能立即拉取回数据。这里的解决方式两个,一个是使用异步的方式,但是发出异步的请求之后,立即就回复客户端,要求客户端一会儿之后重试。第二个优化措施就是Priority Pull的批量处理。在一个Priority Pull在处理中的时候,目的节点将这个时间段内需要通过Priority Pull拉取的数据组织起来,这个过程中还可以对key进行去重的操作。另外 在传输过程中源节点故障or目的节点故障都是比较难处理的问题。在数据迁移过程中,可能导致的一个问题就是源节点和目的节点双方都没有所有的数据。为了避免将数据在源节点和目的节点都复制一遍,这里利用了RAMCloud的快速恢复机制,这里就是另外一篇论文了。Migration Manager会注册一个源节点对于目的节点的log的依赖。由于这里可以和数据所有权转移操作一起进行,这个并不会带来额外的开销,
The dependency is recorded in the coordinator’s tablet metadata for the source, and it consists of two integers: one indicating which master’s log it depends on (the target’s), and another indicating the offset into the log where the dependency starts.
在数据迁移完成之后,这个依赖回去去除。
0x02 评估
这里的具体信息可以参看[1].
Arachne: Core-Aware Thread Management
0x10 引言
这Paper是关于一个用户级线程库的一个实现,在RAMCloud这样的系统,需要处理大量的请求,但是每个请求处理的时候都很短。通过在RAMCloud中添加这样一个用户级的线程库,实现了很大的一个性能提升。
... Adding Arachne to the RAMCloud storage system increased its write throughput by more than 2.5x. The Arachne threading library is optimized to minimize cache misses; it can initiate a new user thread on a different core (with load balancing) in 320 ns.
0x11 基本架构
Arachne的核心思路是动态分配一个应用需要的CPU核心的数量,从而实现CPU利用率的最大化。Arachne在运行自己的用户态线程的时候,特别针对缓存等做了优化,提升性能。Arachne的基本架构如下,Arachne主要由三个组件组成,核心的一个是Core Arbiter,运行在一个单独的用户进程中,一个Arachne Library会被链接到每个应用中,应用可以通过其和Core Arbiter教会。另外的两个组件,一个是Arachne Runtime,用于提高应用运行需要的一些条件,另外的一个是Core Policy,不同的应用可以设置不同的Core Policy。Arachne Runtime创建若干的Kernel Thrads来运行User Threads,这个Runtime会提供项pthread库一样的一些基本编程工具,比如用户线程的创建和消耗、互斥量、信号量等,这些操作都实现在用户态,会比利用内核提供的工具实现的性能更快。Core Policy决定了一个应用需要多少的CPU核心,决定哪些用户线程在哪些核心上面运行。
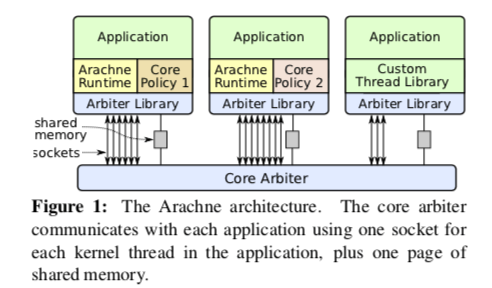
- 在Arache中,使用内核线程作为CPU核心的一个代理。子啊创建一个内核线程之后,会绑定到一个CPU核心上面。当Arbtier分配一个CPU核心的时候,就解锁绑定在一个CPU核心上面的内核线程,将其分配个对应的应用来使用。用户线程在其上面运行的时候,Arache Runtime不会抢占这个线程的运行,用户线程得主动使用yield来让出CPU的使用,这样其它的用户线程才可以在这个核心上面运行。
- Arache中的Core Arbiter是使得Arache和其它的用户态线程可以不同的一个明星特征。它主要实现三个功能,一个是完全在用户态实现多核心的管理,第二个是处理和不使用Arachne应用的共处,第三个是合作处理核心管理的一些测量。它将CPU和分配Managed核心和Unmanaged核心。Managed核心运行由Arache创建的内核线程,Unmanaged有Linux来管理,有没有使用Arache的应用来使用,也包括了Arbiter自身。
- 在Arbiter启动的时候,它为Unmanaged核心创建一个cpuset,并将所有的核心放在上面,并将已经存在的线程分配给这个cpuset。此外,同样会创建一个Managed cpuset,但是初始的时候不会在其上面分配线程。分配核心的时候,Arbiter通过将一个核心有Unmanaged移动到Managed的cpuset来实现,并分配一个Arache创建的内核线程,当这个核心不被使用的时候,归还到Unmanaged的cpuset。
0x12 Runtime 和 Core Policyes
运行时设计这里Arache特别强调了在Cache方面的优化。为了降低Cache Miss,Arachne讲每个线程的上下文都绑定到一个特定的核心上面。每个用户线程在创建的时候,会被赋予一个Context,这个线程只会在这个Context绑定的CPU核心上面运行。绝大部分的线程整个生命周期内都只会在一个CPU核心上面运行,只有在显式地迁移的时候,才会发生转移,这些操作发生的概率比较小,比如Arbiter回收CPU核心的时候。在一个用户线程完成执行的时候,对应的Context仍然绑定在CPU上面,这样下次重用这个Context的时候,Context的内容有更大的可能仍然存储在Cache中。
-
为了创建一个用户线程,Arachne runtime必须为其选择一个CPU核心,并且为其分配一个Context。这些操作都有可能导致Cache Miss。在选择一个CPU核心的时候,处理的方式是“power of two choices”的方式,这个方式也是负载均衡中常用的方式。随机选择两个核心,并读取他们的maskAndCount字段的值,这个值有56bit bitmask,保存最近使用的Context ID信息,以及8bit的a count of the number of ones in the mask。选择其中活跃线程数据较少的一个,maskAndCount用于加速分配Context。在分配了Context之后,将线程top-level的方法的地址可参数拷贝到Context中,然后设置一个字段标记其可以运行。
Arachne uses a single cache line to hold all of this information. This limits argument lists to 6 one- word parameters on machines with 64-byte cache lines; larger parameter lists must be passed by reference, which will result in additional cache misses. -
Thread scheduling,常见的线程调度方式时使用一个 or 多个运行队列的方式。但是这些队列的操作,加上如任务窃取之类的负载均衡方式,可能会导致比较多的Cache Miss。这里Arache不实用任务队列的方式。Arachne dispatcher会重复地扫描所有线程的Context,知道可以找一个绑定在一个CPU核心上面,且可以运行的线程为止。这种方式更加有效率有这样的几个原因,1. 在一个时间点,分配给一个核心的线程数量时比较少的,也就意味着扫描可以快速完成,2. 另外的一个原因是利用读取state字段的Cache Miss扫描更多的线程,
the cost of scanning the active thread contexts is largely hidden by an unavoidable cache miss on the scheduling state variable. ... 100 or more cycles elapse between when the previous value of the variable is invalidated in the dispatcher’s cache and the new value can be fetched; a large number of thread contexts can be scanned during this time. -
为了将修改线程的state字段优化为无锁的,这里使用一个64bit的wakeupTime表示状态。当这个值小于处理器的cycle counter,则表明其是可以运行的。当发生写出切换的时候,这个wakeupTime值会被设置为max。唤醒线程则就是将wakeupTime设置为0,表明其处于可以运行的状态。
Arachne的Core Policyes机制主要是为分配核心的使用。默认的策略支持两种线程类型,一种是exclusive,运行在单独的核心上面,为特殊的线程准备,比如长时间轮询的线程。另外一种是normal,多个一般的线程运行在上面。在考虑需要添加核心的时候,主要考虑的是load factor,超过一定的阈值之后Arachne会尝试为其多分配核心,减少CPU核心的时候,基于的考虑是utilization,策略所有核心综合的利用率,如果低于一定的阈值,则考虑减少分配的核心,
... the load factor for scaling up, the interval over which statistics are averaged for core estimation, and the hysteresis factor for scaling down. The default core policy currently uses a load factor threshold of 1.5, an averaging interval of 50 ms, and a hysteresis factor of 9% utilization.
0x13 评估
这里的具体信息可以参看[2].
参考
- Rocksteady: Fast Migration for Low-latency In-memory Storage, SOSP ‘17.
- Arachne: Core-Aware Thread Management, OSDI ‘18.
