Clock-SI: Snapshot Isolation for Partitioned Data Stores Using Loosely Synchronized Clocks
0x00 引言
Clock-SI是为分区数据库设计的一种Snapshot Isolation的方法。Clock-SI作为一个非中心话的SI算法,主要要解决的事在分布式的环境下面时钟偏斜带来的问题,主要体现它的读协议和提交协议上面,
We show that Clock-SI has significant performance advantages. In particular, for short read-only transactions, Clock-SI improves latency and throughput by up to 50% over conventional SI. This performance improvement comes with higher availability as well.
0x01 基本思路
在Clock-SI中,SI的性质主要有3个要求来保证:1. 一个事务读取某条记录的时候,只能读取在这个事务的快照时间戳前面提交了的事务(abort没有提交以及之后提交的数据都不能读取),2. 提示提交的顺序有事务的提交时间戳决定的,3. 并发事务在更新相同的记录的时候,会造成写写冲突,继而导致这些事务要abort。在Clock-SI,主要要解决的问题有,
-
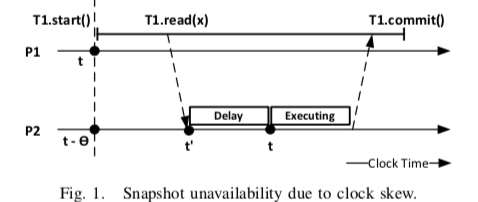
时钟偏斜导致的Snapshot不可用。在下面的图中分区P2的时钟比P1晚了一段时间。在P1试图读取P2上面的数据的时候,P2查看自己的时间为t‘,且这个时间小于P1的t。在P2中t’ 到 t的过程中就可能存在另外一个事务的修改操作,使得P2的时间t的时候数据已经被修改。不能满足SI上面的提到的要求。
-
待决的提交导致的Snashot不可能。第2中情况来自一个分区上面,下面中T1在T2的前面执行,但是迟迟不能提交,导致T2的操作无法正常进行,而且T2不知道T1最终师范能够成功,多久之后能够成功。

Read Protocol
Clock-SI为一个去中心化的方法,没有一个类似Oracle的时间戳授予的服务。它直接使用本地读取到的时间戳,
StartTransaction(transaction T)
// Clock-SI直接使用本地时钟,在需要的时候可以减去一个∆,
// 来保证读取的成功率or读取比较旧的数据
T.SnapshotTime ← GetClockTime() − ∆
T.State ← active
ReadDataItem(transaction T, data item oid)
if oid ∈ T.WriteSet return T.WriteSet[oid]
// check if delay needed due to pending commit
// 解决前面时钟的问题和Pending事务的问题就是开等待
if oid is updated by T′ ∧
T′.State = committing ∧
T.SnapshotTime > T′.CommitTime
then wait until T′.State = committed
if oid is updated by T′ ∧ T′.State = prepared ∧
T.SnapshotTime > T′.PrepareTime ∧
// Here T can obtain commit timestamp of T′
// from its originating partition by a RPC.
T.SnapshotTime > T′.CommitTime
then wait until T′.State = committed
return latest version of oid created before T.SnapshotTime
upon transaction T arriving from a remote partition
// check if delay needed due to clock skew
if T.SnapshotTime > GetClockTime()
then wait until T.SnapshotTime < GetClockTime()
Commit Protocol
Clock-SI中的提交协议区分了单个分区的提交和跨分区的提交。单个分区的处理比较简单,直接使用获取的本地时间戳执行提交操作即可。而跨分区的提交使用2PC的方法,选择的时间戳事在prepare步骤获取到的最大的时间戳。
CommitTransaction(transaction T)
if T updates a single partition then
LocalCommit(T)
else
DistributedCommit(T)
LocalCommit(transaction T)
if CertificationCheck(T) is successful
T.State ← committing
T.CommitTime ← GetClockTime()
log T.CommitTime and T.Writeset
T.State ← committed
// two-phase commit
DistributedCommit(transaction T)
for p in T.UpdatedPartitions
send prepare T to p
wait until receiving T prepared from participants
T.State ← committing
// choose transaction commit time
T.CommitTime ← max(all prepare timestamps)
log T.CommitTime and commit decision
T.State ← committed
for p in T.UpdatedPartitions
send commit T to p
upon receiving message prepare T
if CertificationCheck(T) is successful
log T.WriteSet and T’s coordinator ID
T.State ← prepared
T.PrepareTime ← GetClockTime()
send T prepared to T’s coordinator
upon receiving message commit T
log T.CommitTime
T.State ← committed
0x02 评估
这里的具体的信息可以参看[1],
A Critique of Snapshot Isolation
0x10 引言
这篇Paper提出了一个write-snapshot isolation(WSI)的思路,一个创新的观点在于MVCC中实现SI可以允许写写冲突,而是只会检测读写之间的冲突。这样不仅仅可以满足SI的要求。因为现在的一个在SI上实现SSI是通过处理读写冲突来实现的,这样WSI可以提供Serializability级别的隔离性。
0x11 基本思路
这篇Paper主要的创新就是证明了在MVCC中只处理读写冲突即可。以下图中的例子为例,在txn-o和txn-c’‘虽然都是写入了同一条的数据,但是没有冲突。txn-c‘’虽然覆盖了之前txn-o的写入的内容,但是可以看作是txn-o更新之后有被其它的事务更新了。只要这个过程中没有读这条记录的操作,也就是可以看作是没有发生Update Lost的情况。也就是说,这里检测读写冲突是必须的。比如txn-n和txn-c’存在冲突,因为txn-n读取的数据被txn-c‘修改了。Write-SI中的冲突出现与这样的两种情况:
- 读写空间上的重叠,这个即一个事务更新了另外一个事务读取的记录;
- 读写时间上的重叠,Ts(txni) < Tc(txnj) < Tc(txni)。即在txn-i的开始时间戳到提交时间戳这段时间内,txn-j提交了。这里意义上面时间重叠的定义有点细节。比如在下图中,txn-n和txn-c’‘虽然前者读取了后者修改的数据,但是由于txn-c’‘没有在txn-n的生命期内提交,这里就可以视为没有时间上的重叠。

具体的证明可以参看论文。 另外基于这样的WSI的这样一种思路,如何去实现就与具体的实现相关了。
foreach row r ∈ Rr do
if lastCommit(r) > Ts(txni) then
return abort;
end if
end for
Tc(txni) ← TimestampOracle.next();
foreach row r ∈Rw do
lastCommit(r) ← Tc(txni);
end for
return commit;
0x12 评估
这里的具体的信息可以参看[2],
参考
- Clock-SI: Snapshot Isolation for Partitioned Data Stores Using Loosely Synchronized Clocks, SRDS ‘13.
- A Critique of Snapshot Isolation, EuroSys ’12.
