##Scalability of Write-ahead Logging on Multicore and Multisocket Hardware
0x00 引言
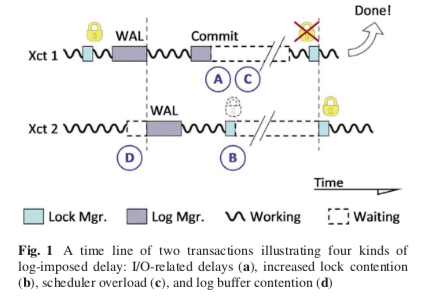
这篇Paper总结了不少Write-ahead Logging设计上面的优化思路。一般数据的WAL设计中,日志会按序写入到日志中,这样的操作中。这样的设计主要有几点影响性能的地方,如下图所示,1. IO相关的延迟,为了保证日志持久化带来的延迟,2. Log处理中锁带来的开销,写入日志数据的时候为了保存有序和日志中没有空洞使用了锁,由此带来的开销,3. 在等待IO完成的时候,工作线程会让出CPU,从而导致线程切换,由此带来的开销,4. Log-induced锁竞争带来的开销,为了提交一个事务,事务会一致持有锁到操作完成,包括日志持久化,由此带来的开销。这篇Paper在这合理提出多种策略来有些这些问题。
0x01 Early Lock Release
Early Lock Release的思路看起来挺简单的,但是在具体的数据库实现的时候会是一个很麻烦的事情。Early Lock Release的基本思路是在一个事务提交之前,就将其持有的锁释放。不过在这个事务提交之前,其执行的结果不能返回给客户端。另外,依赖于这个事务产生数据的其它事务会对这个事务形成一个依赖关系,同样地,在一个事务依赖的事务提交之前,这个事务也不能提交。在严格按序保存日志的系统中,实现这个简单一些,因为后面的事务的日志肯定不会早于前面事务的日志持久化。总而言之,Early Lock Release要满足两个条件,
- 每个依赖于其它事务的事务的日志必须不早于其依赖的事务的日志持久化;
- 一个被依赖的事务abort了,依赖于这个事务的其它事务也必须abort。
Early Lock Release带来的性能影响可以参看[1].
0x02 Flush Pipelining
由于持久化日志带来的延迟主要体现在两个方面,1. 实际等待IO完成的时间,2. 线程等待和解除等待的时候上下文切换带来的开销。前面的Early Lock Release是一种优化第一种延迟的方式,其它的一些方式比如组提交也是优化这些延迟的一种方式。Flush Pipelining是一种已经在一些MySQL版本中采用的优化方式,其基本思路就是工作线程在等待一个事务产生的日志持久化的时候,工作线程可以去继续执行其它的事务。这样的话,工作线程可以一直保持忙碌的状态,减少上下文切换。其基本的支持方式如下,
- 工作线程在发出IO请求的时候,不会等待起完成,当然也不能立即返回给客户端结果。工作线程这个时候就可以去执行其它的事务了。
- IO线程在受到工作线程的IO请求的时候,负责将相关的日志数据持久化。这里就可以使用一些组提交之类的优化方式。在IO操作完成的时候,通知对应的工作线程。工作线程在收到通知之后,继续处理这个事务接下来的事务,完成最终的提交,返回结果给客户端。
- 在提交了IO请求的事务abort之后,事务回滚也必须等到日志被持久化。
Flush Pipelining带来的性能影响可以参看[1].
0x03 Scalable Log Buffer Design
这里的优化也是MySQL 8.0种WAL优化的地方,不过两者思路有区别。ARIES风格的WAL都会一个LSN唯一标识一个日志项。同时这些日志项之间保持严格有序。这样的思路设计之下,基础版本的实现思路如下,
1. LSN generation and log buffer acquire. The thread must first claim the space it will eventually fill with the intended log record
2. Log record insertion.The thread copies the log record in the buffer space it has claimed.
3. Log buffer release. The transaction releases the buffer space, which allows the log manager to write the record to disk.
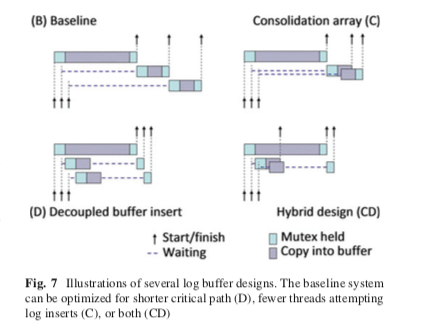
这里基本版本的设计使用了不少的锁来保证正确性,可以也影响了性能,这里常见的设计可以参看MySQL 8.0之前的设计。为了优化这里的性能,这里使用了两种优化策略,之后将这两种策略结合为第三种策略,
-
Consolidating buffer allocation,这种方式是优化将日志数据写入到Log Buffer的时候的优化策略。Log Buffer的分配是可以组合在一起分配的,这里就使用一组组分配的优化策略。在尝试分配Log Buffer的空间的时候,如果线程之间遇到竞争,这里不会直接竞争失败的等待成功的线程的方式。而是尝试将这些操作组合为一组的操作。这样的一些操作线程之中,只会有第一个线程来分配需要的空间,而最后一个离开的线程需要等待操作完成,然后释放资源。下图中的(C)表示来这种思路,一个线程在等待log mutex的时候,另外的两个线程的操作也到达了,这样的话这三个线程可以组合为一组的操作。接下来的操作的是它们可以并行进行,但是只需要第一个线程进行获取锁的操作即可。最后一个线程离开才释放也可以保证这组的操作是完成的,Log Buffer中间不会出现空洞,
... consolidation leaves significant wait times because only buffer fill operations within a group proceed in parallel; operations between groups are still serialized. Given enough threads in the system, at least one thread of each group is likely to insert a large log record, delaying later groups. -
Decoupling buffer fill and delegating release,这里的操作是为了优化下图(D)中的情况。前面操作的数据比较多,由于有序性和Log Buffer中不能出现空洞的要求,导致后面的数据必须等到前面的数据完成。为了优化这里,利用了前面的 Flush Pipelining。后面的操作完成之后,其Buffer资源释放被委托给前面的操作,而后面的线程就可以进行去进行其它操作,最终只需要等待IO操作完成的信号即可,
... threads which would normally have to wait for a predecessor instead attempt to mark their buffer as abandoned using an atomic compare-and-swap operation. Threads which succeed in abandoning their buffer before the predecessor notifies them are free to leave, forcing the predecessor to release all buffers that would have waited for it. -
Hybrid Log Buffer,这里就是将前面的两种方式结合到一起。
0x04 Log Buffer Design for NUMA
这一节是Paper中笔墨最多的一节。主要描述在NUMA缓解下面Log Buffer的设计。这里设计的基本出发点就是每个Socket上面设计一个Log,从而降低在所有的CPU都在同一个Log上面操作带来的开销。但是这样的设计有几个麻烦的问题要解决,1. 事务在一个log所在的CPU上面执行之后转移到另外一个log所在的CPU上面执行的时候需要追踪日志之间的依赖关系,在Commit的时候要将所有相关的日志持久化,这个在多个log上面的操作的时候带来不小的开销,2. LSN无法在这样的Distributed logging设计下面维护一个系统级别的日志顺序关系,3. 日志落盘的时候,写入的数据速率不一致,可能导致的日志空洞问题。为了解决第一个问题,这里的思路就是将一个事务固定在一个CPU上面运行,这样的好处就是不会有事务的迁移的问题。另外的问题就是一个Page相关的日志会发布在各个Log上面。LSN不能维护一个全局的顺序关系,这里就是提出了global sequence numbering (GSN)的概念,GSN基于Lamport clocks。基本的思路如下,
1. Every message is accompanied by its sender’s current timestamp
2. A receiving process updates its own timestamp to be at least as large as the one in the message.
3. Every meaningful action or message received is an “event” and increments the process timestamp.
为了处理多个日志速率不一致可能导致的空洞的问题。这里需要对一些externally visible event,如事务提交、脏页写入等操作时,对log进行同步操作。通过记录每个log的尾部位置在一个 log sync record中,这个记录会被写入到本地的log中。另外在Page读取的时候,要进行同步器timestamp的操作,避免一些读取到的Page被更新or太旧的问题。emmm,细节TODO。在日志写入的时候,也需要进行同步操作。Log synchronization的操作主要分为三步,
1. The thread records the current timestamp of every log and updates each log’s timestamp to be no smaller than its own.
2. The thread inserts a synchronization record — containing the recorded timestamps—into its own log
3. The thread requests the system to harden all logs up to its own timestamp, waiting for the I/O to complete before continuing.
0x05 评估
这里的具体信息可以参看[1]。Paper中对各个部分的优化带来的性能影响有比较好的总结。
参考
- Scalability of Write-ahead Logging on Multicore and Multisocket Hardware, VLDB ‘12.
- Aether: A Scalable Approach to Logging, VLDB ‘10.
