Pay Migration Tax to Homeland: Anchor-based Scalable Reference Counting for Multicores
0x00 引言
计数器在一些基于应用技术对象/内存回收的场景中是一个很常用的结构,这篇Paper讨论的是Linux Kernel中refcount的计数器算法的优化。这里提出的PaygGo总体上来说,还是Paper[3]中提出的RefCache的优化。这里认为,计数器的主要的4个方面的overhead为Counting overhead、Query overhead、Space overhead和Time overhead,即从更新、读取、空间和时间上面分析一个计数器算法的好坏程度,
PAYGO, a reference counting technique that combines per-core hash of local reference counters with an anchor counter. PAYGO imposes the restriction that decrement must be performed on the original local counter where the act of increment has occurred so that reclaiming zero-valued local counters can be done immediately.
0x01 RefCache
Query overhead最优化的情况是单独的一个原子整数,比如atomic_long,Space overhead和Time overhead对于这样的方式也是最优的,但是简单的原子整数操作的Counting overhead是最大的。另外的一个思路是每个CPU核心一个计算器,这样的设计上,Counting overhead是最优的,但是Query overhead和Space overhead方面则差一些。
- 在RefCache中,每个Counter有一个全局的计算器,和原子整数的计数器类似,另外每个核心保存了一个固定大小的本地计数器。在增加和减少计数器的时候,都是先在本地进行操作,这样本地保存的是delta的数据即变化的数据。这些数据会周期性地更新到全局的计数器。这样计数器实际的值就是全局计数器加上所有的local计数器的值,这里会假设一个计数器变为0之后,值会维持为0,实际上一般的逻辑也会是这样。
- 这里的全局计数器的更新基于epoch的策略,来则Scalable Communication Rules中的延迟操作。这里的计数器为引用计数设计,正确逻辑的情况下计数值到达0之后,就不会再去更新了。如果要确定一个计数器目前的值为0,之前的操作按照任何的顺序操作都是相同的结构,也就是这些操作时满足交换律的。
在基本的引用计数之外,RefCache还添加了Weak Ref的支持。RefCache伪代码如下,RefCache也是一种利用per-core hash的方式。PayGo也沿用了per-corehash的思路。
inc(obj):
if local cache[hash(obj)].obj != obj:
evict(local cache[hash(obj)])
local cache[hash(obj)] ← ⟨obj, 0⟩
local cache[hash(obj)].delta += 1
tryget(weakref):
do:
⟨obj, dying⟩ ← weakref
while weakref.cmpxchng(⟨obj, dying⟩, ⟨obj, false⟩) fails
if obj is not null:
inc(obj)
return obj
flush():
evict all non-zero local cache entries and clear cache update the current epoch
evict(obj, delta):
with obj locked:
obj.refcnt ← obj.refcnt + delta
if obj.refcnt = 0:
if obj is not on any review queue:
obj.dirty ← false
obj.weakref.dying ← true
add ⟨obj, epoch⟩ to the local review queue
else:
obj.dirty ← true
review():
for each ⟨obj, objepoch⟩ in local review queue:
if epoch < objepoch + 2: continue
with obj locked:
remove obj from the review queue
if obj.refcnt != 0:
obj.weakref.dying ← false
else if obj.dirty or obj.weakref.cmpxchng(⟨obj, true⟩, ⟨null, false⟩) fails:
obj.dirty ← false
obj.weakref.dying ← true
add ⟨obj, epoch⟩ to the local review queue
else:
free obj
0x02 基本思路
RefCache设计中的一个问题就是一个线程的递增和递减操作可能在不同的核心上操作。所以也确定一个计数值为0比较麻烦,PayGO这里的优化思路时引入一个anchoring。在REF操作的时候,PayGo总是会访问local reference cache,而且使用非原子操作的方式更新,这样这个进程/线程会逻辑上将操作时候的CPU核心作为Homeland,Core ID会记录在task struct中。在UNREF操作的时候,根据这个进程/线程是否发生了迁移而决定如何执行UNREF操作。如果没有迁移,直接使用非原子操作的方式执行操作,如何已经迁移了,则使用原子性的方式更新原来核心上的reference cache的anchor counter。而下表标记为na的操作不会发生。
| 类型 | local ref | local unref | achor ref | achor unref |
|---|---|---|---|---|
| Homeland | no | no | na | na |
| Foreign land | na | na | na | yes |
PayGo的整体结构如下图。
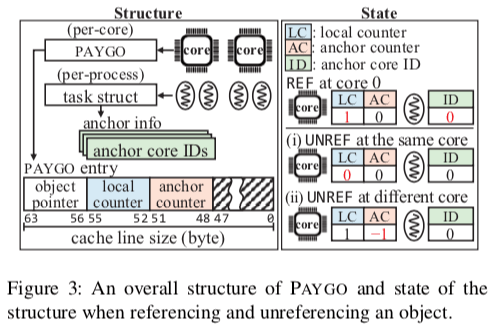
在查询一个计数器值的时候,这里要注意的是read-all的时候不能保证操作看到的是操作开始时候的一个snapshot,可能read-all操作到半途中的时候,状态被更新,这里使用一个添加一个flag的方式,在ref操作的时候也要处理这个flag。
// REF operation
rcu_read_lock();
while (rcu_pagep = radix_tree_lookup_slot()) {
if (!(page = radix_tree_deref_slot(rcu_pagep))
break;
preempt_disable();
this_cpu->hash[H(page)]->local_counter++;
add_anchor_info(current_task, page, this_cpu);
preempt_enable();
if (get_flag(page) || is_object_removed(page)) {
UNREF(page);
continue;
}
}
rcu_read_unlock();
// UNREF operation
//(migrated to other core)
preempt_disable();
anchor = find_last_anchor(current_task, page);
if (anchor.cpu == this_cpu)
this_cpu->hash[H(page)]->local_counter--;
else
atomic_dec(&anchor.cpu-> hash[H(page)]->anchor_counter);
delete_anchor_info(current_task, anchor);
preempt_enable()
// READ-ALL operation (reclaimer)
// ..
set_flag(page);
if (read_all(page)) {
clear_flag(page);
return fail;
}
delete_object(page);
clear_flag(page);
0x02 评估
这里的具体信息可以参看[1].
An Analysis of Linux Scalability to Many Cores
0x10 引言
这篇Paper不仅仅是关于一个Counter优化的Paper。在这篇Paper中总结了不少Linux Kernel中使用的在多核环境下面的性能优化手段,其中的一个就是Sloppy Counter,用于优化多核环境下面的计数的问题。另外的一个是Per-core data structures,在Linux Kernel中,这个方式也被用于实现一些per-core的计数器,比如Per-CPU reference counts。
0x11 Sloppy Counter
未来提高计数器的性能,将不同线程/核心操作计数器的数据结构拆分开是基本的思路。这里Sloppy Counter也不例外,Sloppy Counter的结构和前面的RefCache和类似。Sloppy Counter也由一个中心的计数器和每个核心游泳的几个本地的spare references组成。
- 当一个核心准备去增加一个值,大小为V的时候,首先去尝试去通过将本地的per-core的couter递减V,来请求一个spare reference。如果本地的计数器的值不小于这个V,请求成功。否则得去中心计数器请求。请求中心计数器就是直接递增中心计数器的值,加V。
- 同样地在需要减少一个值,大小为V的时候。释放本地的spare references,增加本地计数器的值。如果本地计数器的值超过一定的阈值,则也会进行释放spare references的操作,会改变本地和全局的计数器的值。
可以看出这里的思路是想办法将增加、减少的操作都在本地完成,只有本地的值无法满足操作的要求的时候才去请求全局的计数。
0x12 Per-core data structures
Per-core data structures也是Linux中常用的数据结构,比如在io uring的代码中就有使用。每个核心一个计数器,在计算总和的时候将这些值相加会比前面的这些方法更好一些,在很多的情况下是一种很好解决的方案。percpu_ref有两种模式,一种就是普通的atomic_long模式,另外一种就是每个CPU核心一个计数器,在添加的时候几添加到本地的CPU上面this_cpu_add (*percpu_count, nr);。
struct io_ring_ctx {
struct {
struct percpu_ref refs;
} ____cacheline_aligned_in_smp;
// ...
}
//
// --------------
//
168 /**
169 * percpu_ref_get_many - increment a percpu refcount
170 * @ref: percpu_ref to get
171 * @nr: number of references to get
172 *
173 * Analogous to atomic_long_add().
174 *
175 * This function is safe to call as long as @ref is between init and exit.
176 */
177 static inline void percpu_ref_get_many(struct percpu_ref *ref, unsigned long nr)
178 {
179 unsigned long __percpu *percpu_count;
180
181 rcu_read_lock_sched();
182
183 if (__ref_is_percpu(ref, &percpu_count))
184 this_cpu_add(*percpu_count, nr);
185 else
186 atomic_long_add(nr, &ref->count);
187
188 rcu_read_unlock_sched();
189 }
0x13 评估
这里的具体信息可以参看[2].
Java Long Adder
0x21 基本思路
Java Long Adder也是为优化AtomicLong在多核环境下面计数问题提出的。其基本的思路也是将计数分散到多核sub计数器上面。不过标准库中的实现一般都非常注意通用性,Long Adder在实现的时候会根据目前的冲突情况选择这个sub计数器的数量,在冲突很少的时候,就会是哟个交代呢的Atomic Long,而在冲突更多的时候,它会自动的拓展sub计数器的数量。其基本的add方法如下。如果as为null的时候,表示这个之前的冲突比较好,直接使用Strip64中的base的值作为计数即可,这个就是一个整形值。如果,不为null or 操作Base由于冲突失败,则尝试操作Cell,这里会判断这些数据的是否为空(null or empty),在必要的时候添加sub计数器。longAccumulate是一个比较复杂的方法,其基本作用就是在合适的时候对cell数组进行扩容操作。
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
而求和操作就是将cells和base的值相加,
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
0x22 评估
这里可以搜索网上的相关信息。
参考
- Pay Migration Tax to Homeland: Anchor-based Scalable Reference Counting for Multicores, FAST ‘19.
- An Analysis of Linux Scalability to Many Cores, OSDI ‘10.
- RadixVM: Scalable address spaces for multithreaded applications, eurosys ‘13.
- SNZI: Scalable nonzero indicators. PODC ‘07.
- http://hg.openjdk.java.net/jdk8/jdk8/jdk/file/7b4721e4edb4/src/share/classes/java/util/concurrent/atomic/LongAdder.java
