Flashield: a Hybrid Key-value Cache that Controls Flash Write Amplification
0x00 引言
这篇Paper是关于在Flash上面实现Key-Value Cache时候写入放大的问题。它的主要的对比对象就是前面的RIPQ。 Flashield通过结合多种方式来优化写入放大的表现。Flashield将DRAM做3个方面的用途,1. 作为一个Filter来决定一个对象是否最终被写入到Flash上面,2. 保存对象的元数据,用于对象的查找和驱逐,3. 作为Flash的Cache层,
Compared to state-of-the-art systems that suffer a write amplification of 2.5× or more, Flashield maintains a median write amplification of 0.5× (since many filtered objects are never written to flash at all), without any loss of hit rate or throughput.
0x01 写入放大
Flashield在这里分析了Flash Based的Key-Cache Cache两个主要的写入放大的来源,
- Device-level Write Amplification,这里写入放大源自于SSD的内部结构。和HDD一样,SSD也是以Page为单位进行读写,而擦除操作以block为单位。写入对象的大小与Page大小以及擦出操作的单位Block之间的差异造成来设备层面的写入放大。特别在SSD内部的空间利用率达到一个比较高的水平的时候,这个变得更加严重。
- Cache-level Write Amplificatio,为了减少上面提到的写入放大以及更好地利用SSD的带宽。Flashield此类的系统一般都以Segment为单位进行写入。但是这个还是完全解决问题。Cache层面的写入放大来自于一个被驱逐的Segment中的对象被重新写入。
0x02 基本思路
总体而言,Flashield还是一个基于Bitcask模型的。Flashield使用Hash Table作为索引,且全部保存到内存中。但是Bitcask的模型特别适合的场景是Key不大,但是Value比较大的场景。比如Haystack使用的图片存储。如何作为一般的Key-Value Cache,可能的后果就是这个Hash Table索引会消耗比较多的内存。Flashield这里特别优化来索引的内存使用,可以做到每个对象使用不超过4bytes的内存。Flashield不会将key保存在内存中,而是作为数据的一部分保存到Flash上面。在没有Hash冲突的时候就可以之间使用查找到的位置信息获取到Key-Value数据。如果存在Hash冲突,则需要将可能的数据的Key做对比,依次查找符合条件的数据。另外,这里的Hash Table还使用了类似Cuckoo Hash中使用多个Hash函数的方法。在方式Hash冲突的时候,为了减少查找Flash的次数,这里和在很多LSM-Tree中的做法一样,也使用了一个Bloom Filter作为过滤,用于避免一些不必要的Flash数据获取。
内存角色
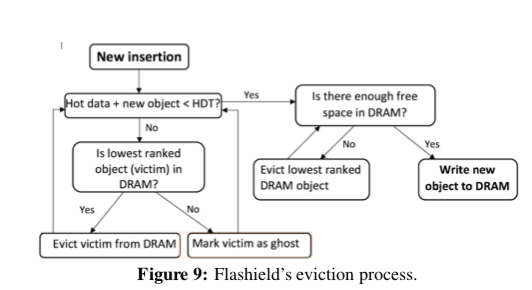
作为一个Cache的角色,Flashield最好只需要保存最有Cache价值的数据。Flashield这里引入了Flashiness的概念,作为一个对象被Cache价值的一个评价指标。一个高Cache价值的对象要满足两点条件,1. 一个对象在访问之后会在不远的将来访问n次(及以上),这里的n作为参数定义,2. 在将来的一段时间内不会被修改。这里Flashiness使用了SVM来作为分类器,将对象分为有价值写入Flash Cache的类别和没有价值作为Cache对象的部分。这里内存就作为一个Filte的角色,经过这个Filter过滤的有Cache价值的对象才会被保存到Flash上面。处理作为Filter之外,内存还是一个Cache层的角色,Cache对象中最热门的部分会被直接保存到内存之中。
缓存替换
Flashield使用CLOCK缓存替换算法。CLOCK算法的好处就是可以避免使用链表实现LRU的链表和维护链表中对象顺序的开销。如下图所示,Clock的信息会被作为Hash Entry的一部分保存下来。另外还会记录使用的Hash函数的ID,这里最多可以使用16个。另外一个就是Segment Number,这里会结合Hash函数ID来定位对象在Flash上面的位置。Ghost bit用于标记一个对象是否已经被删除。与Bitcask记录offset不同,这里是使用Hash函数计算出来的值作为偏移寻址。
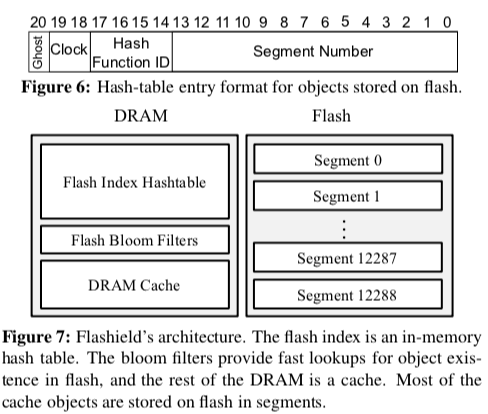
Flashield删除Segment也是使用一种FIFO的方式,在此过程中,被标记为Ghost的对象会被直接删除,热点数据会被重新添加。这里同样采用了RIPQ优化热点数据比较多的Segment的思路,
0x03 评估
这里的具体信息可以参看[1].
##Cascade Mapping: Optimizing Memory Efficiency for Flash-based Key-value Caching
0x10 引言
这篇Paper是这篇SoCC上面一篇在类似Bitcask模型下面索引内存占用优化的一篇文章。在类似于Bitcask的模型中,数据以日志式的方式顺序写入到磁盘上面,而索引则全部保存到内存中。上面的Flashield这篇Paper也设计它的优化内存使用的思路,而Cascade Mapping这里则提出了一种不同的思路,Cascade Mapping的基本idea式利用索引的索引的思路,
... we can achieve nearly identical performance as the conventional all-in-memory scheme, while using only a fraction (10%) of the required memory. Alternatively, this approach allows us to build a 10 times larger flash cache with the same amount of memory, which in turn increases the hit ratio by up to 8.2 times and the throughput by up to 125 times.
0x11 基本思路
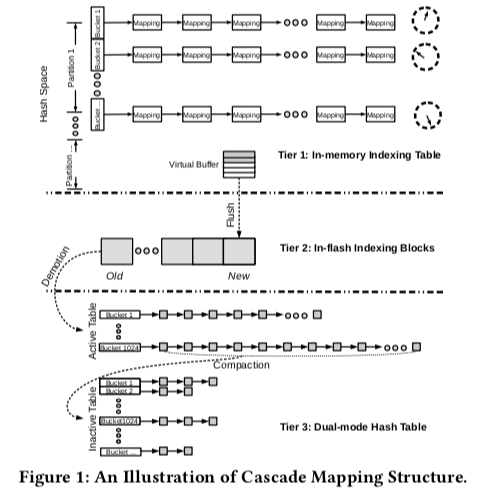
Cascade Mapping的基本思路就是使用多层的思路。在Paper中使用了3层,当然使用更多也是可以的,不过再多也没用很大的意义。Cascade Mapping的基本思路和很多文件系统中数据块保存到inode中的思路比较相似。在Cascade Mapping中,
- Tier 1: An In-memory Indexing Table,这一层和一般的内存中的索引没有很大的区别。在Cascade Mapping这里只用于保存最热点数据的索引。这里可以使用一些缓存替换算法来实现这里尽可能地保存的就是最热门部分的数据。
- Tier 2: A Direct Indexing in Flash,第2层用于保存“暖”数据,这里可以理解为将第一层的数据保存到了SSD上面。这里以Block为单元组织数据,按照FIFO的顺序组织。在这里查找数据的时候,先通过hash值确定可能存在的partition,然后使用并行请求的方式值查找。
- Tier 3: A Dual-mode Linked Hash Table,这里如下图,这里可以立即为2层中用于查找SSD上面的数据又被保存到了此篇上面,造成来一种2级的间接。这里同样也引入了Compaction操作来合并一些索引数据。这里还另外采用了一些优化手段来加快查找[2]。第2层的引入在很多时候还是很有用的,在增加层级意义不大了。
0x12 评估
这里的具体信息可以参看[2].
DIDACache: A Deep Integration of Device and Application for Flash Based Key-Value Caching
0x20 引言
DIDACache可以看作就是Fatcache利用OpenChannel SSD的一个优化版本。DIDACache这里主要讨论优化了三个问题,1. Redundant mapping,在SSD中使用FTL保存逻辑Block到物理Block的映射关系,而同样的,Key-Value系统也会保存一个Key到保存位置的一个映射信息。如何利用Open Channel之类的机制,可以优化这里的Redundant mappin,2. Double garbage collection,同样地在SSD硬件层面和Key-Value系统层面都会存在GC操作,3. Over-overprovisioning,就是预留一部分的Flash空间(OPS)用于保持SSD在一些情况下的性能表现,比如GC的时候。
DIDACache, based on the Open-Channel SSD platform. Our experiments on real hardware show that we can significantly increase the throughput by 35.5%, reduce the latency by 23.6%, and remove unnecessary erase operations by 28%.
0x21 基本设计
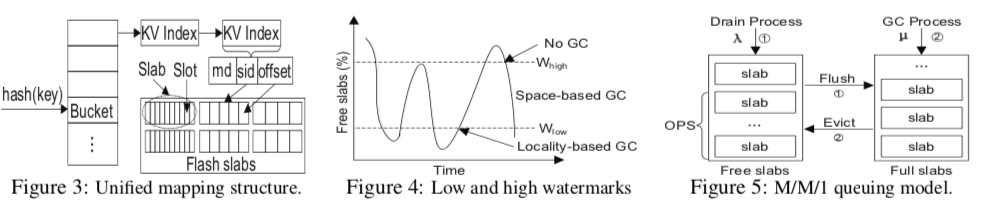
DIDACache基本上还是沿用了Fatcache的总体设计,有以下几个主要的部分,1. Slab Manager,使用slab的方式管理Flash的空间,2. unified direct mapping,记录Key-Value到物理位置的信息,3. 一个integrated GC模块用于垃圾回收,4. OPS management用于动态使用OPS空间的大小。
- Slab Management,Slab和Fatcache基本一致,也没有什么特别的地方。这里会直接将slab映射到物理的flash block。不同尺寸的slab固定地映射到一些置顶的flash blocks。这里可以使用,1. Per-channel映射,2. Cross- channel映射。后者理论上可以实现更好的带宽表现。前者更加简单。而DIDACache使用前者。和常见的方法一样,这里也是会将数据先保存在内存中,积累到一定的数据之后,作为一个整体写入到Flash上面。
- Unified Direct Mapping用于解决double mapping的问题,这里使用SHA-1hash值作为key的代表,一个Hash Entry为<md,sid, offset>格式,即SHA-1 hash值加上slab id加上便宜信息,这样就可以直接得到Key Value的物理地址。
- Garbage Collection,DIDACache的GC与数据驱逐关联到一起。驱逐数据这里有两种基本的策略,1. 基于空间的策略,选择过期数据最多的slab进行驱逐,2. 基于局部性的策略,就是利用LRU的思路进行数据驱逐。这里同时使用了这两种方法,在系统不同的运行状态选择执行,在下面的图中有表现。
- Over-Provisioning Space Management。这里定义了两个值,W-hight和W-low,用于标记系统利用率的阈值状态。这里基本的思路也有两种,第一种的基本思路是基于反馈,系统目前压力的情况。如果系统压力大的时候,提供W-low,会导致系统更快速回收数据,从而预留出更多的OPS空间,反之同理。另外一种方法是基于排队理论[3].
0x22 评估
这里的具体信息可以参看[3],
参考
- Flashield: a Hybrid Key-value Cache that Controls Flash Write Amplification, NSDI ‘19.
- Cascade Mapping: Optimizing Memory Efficiency for Flash-based Key-value Caching, SoCC ‘18.
- DIDACache: A Deep Integration of Device and Application for Flash Based Key-Value Caching, FAST ‘17.
