Design and Evaluation of Main Memory Hash Join Algorithms for Multi-core CPUs
0x00 引言
Hash Join是几个Join算法中被运用很多的一种,虽然到现在某著名的开源数据库都不支持Hash Join。Hash Join一般范围两个阶段,第一个阶段是建立Hash Table,用于在后面的阶段使用,第二个节点是探测阶段。当然可以存在可选的分区阶段。通过多种的优化措施的测试结果分析,简单的的方式反而更加好,
... a very simple hash join algorithm is very competitive to the other more complex methods. This simple join algorithm builds a shared hash table and does not partition the input relations. Its simplicity implies that it requires fewer parameter settings, thereby making it far easier for query optimizers and execution engines to use it in practice
0x01 基本思路
Paper假设Join在两个表中进行,分别计为S、R,且假设R中数据项小于S的数据项。这样在Hash Join操作的时候,一般就是选择R 建立一个Hash Table,在探测阶段,遍历S,并利用Join Key探测这个Hash Table。得出结果。
- Partition阶段,Partition目的是将数据范围更小的部分,最好能够适应CPU Cache的大小,这样能够减少CPU Cache Miss的次数,从而提高性能。分区中两个重要的考量就是分区的方式和分区的数量。Non-blocking algorithms,非阻塞式的分区表示值扫描一遍R,如果将R中的元组写入到分区的Hash Table中,由于多个线程同时操作这些数据,需要进行线程间的同步操作。在非阻塞式的分区中,有考虑了两种分区的方式,1.1 这种方式创建共享的p个分区,建立操作的时候多个线程同步操作这些分区的数据,这样的一个缺点是需要线程间的同步操作,1.2 另外的一种方式是独立分区,会创建p * n个分区,其中p是最终分区的数量,而n是线程的数据。这建立操作的第一阶段,每个线程只会操作自己具体的数据,在后面在将这些数据合并起来。这样的好处就避免了一些线程间的同步操作,但是缺点就是操作更加复杂,而且会增加一个合并的操作。2. 阻塞式分区,每个线程分配一部分数据,线程扫描这些数据,建立一个直方图的统计信息。操作完成之后统计每个分区的数量。这样的一个好处之后,可以分配每个分区中元组的数量,可以分配适合大小的内存空间,另外的一个就是可以指定线程处理特定分区,避免一些线程之间的同步操作。
- Build phase,如果之前有分区操作,则线程i处理R{i+0∗n} , R{i+1∗n} , R{i+2∗n}分区的数据,下一步就是为这些分区建立Hash Table。这里的Hash Table会选择一个合适的大小。如果没有分区,所有的线程操作同一个Hash Table。
- Probe phase,这里也没有太多特别的。如果之前没有分区操作,线程同时操作S表,如果有分区操作,线程i处理S{i+0∗n} , S{i+1∗n} , S{i+2∗n}分区的数据。
这样总结出4中Hash Join的策略,1. No partitioning join,最简单的方式,不分区处理,2. Shared partitioning join,使用非阻塞式分区方式,3. Independent partitioning join,使用独立分区方式,4. Radix partitioning join。
0x02 评估
Evaluation中不少的结论可以一看,主要有这样的几点,
- 在分区方式的实现中,分区的数量对性能的影响很多,最好的分区大小和CPU Cache的大小匹配;
- 在数据访问不均匀的操作中,不分区的方式比分区的方式可以有更加好的性能;
- 在探测阶段,不分区的方法Cache Miss的比例更大,影响了性能。而分区数量合适的时候Cache命中率会更加好。在SMT的环境下吗,Cache缺失带来的影响被降低;
- 在分区的方式中,可以要处理一些负载均衡的问题。使用的方式是先完成操作的线程帮忙后完成的线程,这样加大了系统的复杂程度。
Paper中得出结论是不分区的方法更加好一些。这里的具体信息可以参看[2]。
Main-Memory Hash Joins on Multi-Core CPUs: Tuning to the Underlying Hardware
0x10 引言
这篇Paper是延续了上篇Paper的讨论。上篇Paper中任务,一般情况下不分区的Hash Join比分区的Hash Join方法要好。这里更加细致的比较了不同Hash Join方法的特点,将其分为两类,一类是对硬件不敏感的,Hash Join运行中参数的设置和硬件的关系不大。另外的是硬件敏感的,Hash Join方法运行的时候算法设置的参数会显著的影响到运行的性能。
0x11 基本思路
一般的硬件不敏感的Hash Join算法就是不分区的方法,基本的思路如下图所示。这类方式中,算法操作共享的数据结构,一些线程是在相同的数据集合上做相同的事情。这类型的方法,算法参数的设置对算法的性能影响不大。不过这里如何是并行的Hash Join的话,线程的数量对算法的性能还是会有比较明显的影响的,
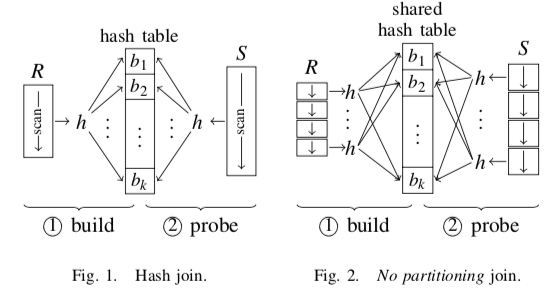
与前面相对的是硬件敏感的Hash Join算法,常见的是分区的方式。一般的分区的方法执行方式如下:1. 根据一个hash函数将R和S划分到若干个分区,这里的分区数量对性能的影响很大,在前面的论文中也提到了,主要要和CPU Cache的大小和TLB的的大小相对应。2. 在Build节点,使用另外一个hash函数在R上面建立分区数量的Hash Table。3. 第三部探测阶段,S中元组的Join Key根据第二个hash函数计算出hash值,在对应的Hash Table中探测即可。
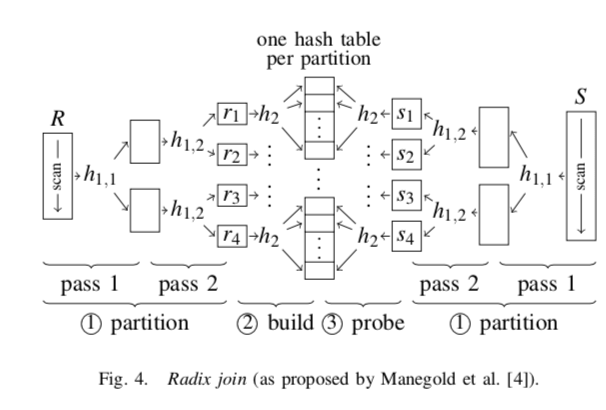
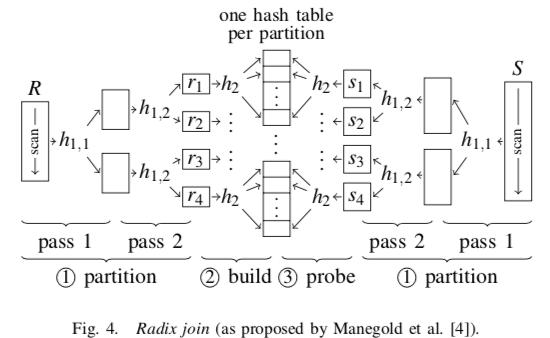
Radix Hash Join是另外的一种分区的思路。Hash Join Cache性能不好的原因就是Hash Table造成的随机内存访问。从而导致的结果就是Cache Miss率的上升。Partition的思路就是将Hash Table 减少到一个比较小的尺寸从而减少Cache Miss的比率。Radix Hash Join则从TLB的方面也优化了。一般的Partion方法中,Partition阶段,需要将不同的数据放入到不同的地方,这里相距可能比较远,从而导致TLB Miss的一些问题。Radix Join的思路是将Partition这里也放入到连续的空间中。这里分区是,根据Join Key的Bit值,将其划分为若干的分区。在必要的时候,可以划分多次达到一个比较理想的分区大小。从下图所示看来,这种策略即使在Partition的时候,数据也会更加连续。Radix Partition主要分为三步,1. 统计直方图,统计每个分区下吗的元组的数量,2. 计算前缀和,3. 根据前缀和回去在内存Partition块中的位置。这里会将数据放入到连续的内存块中,减少Cache Miss和TLB Miss。对元组位置进行调整。Radix Hash Join的思路和一般分区的Hash Join处理分区方式不一样之外,其它的执行方式基本相同。
0x12 评估
在不分区的Hash Join中,算法代价用如下的公式表示 \(cost = C_{put}\cdot | R| + C_{get} \cdot |S|.\) 在测试使用的数据集下面,这里测算这里的Build阶段划花费的时候应该在1/16以上,但是前面的Pape说只花了2%。这里发现主要是因为前面的Paper测试的时候对数据进行排序处理,降低了Cache Miss。在不进行排序的时候,花费时间增加了4倍。对于硬件敏感的Hash Join算法,这里还是的处理分区的数量对性能影响很大的结论。而且分区的方法负载均衡也会是一个问题。但是这里的出的结论不是非分区的方法一般比分区的方法好,而是对于硬件敏感的Hash Join方法而言,合适的参数设置会获到更加好的性能。在Paper中的测试中,表示参数设置合适的时候,Radix Join表现得更加好,而且拓展性也更加好。这里的具体信息可以参看[3].
Memory-Efficient Hash Joins
0x20 引言
这篇Paper将的是一种Hash Join的思路,主要的优化点在其中的Hash Table的实现。Hash Join中使用的Hash Table有这样的一些特点,一次建立完成之后就不会有更新的操作,而且在很多时候,这个Hash Table的大小是可以提前确认的。
0x21 基本思路
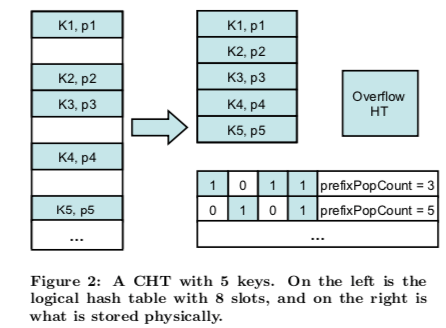
Concise Hash Tables是这篇Paper的核心之一,它是一种linear-probing hash table。不过可以实现[key, value]数组100%的占用率。 Concise Hash Table包含三个主要的组件,1. 一个bitmap用于标记在一个稀疏的bucket数组上面对应的bucket是否存在数据,但是这个数组是虚拟的,不会真多去建立。如果去建立这个数组的话,就和一般的linear-probing hash table没有区别了。2. 一个dense的(key, payload)的数组,用于实际保存前面虚拟数据中的数据。3. 一个overflow hash table。这个Hash Table的设计只能在建立的时候以一个数据集合完成构建,并不支持后面的添加和删除操作,这个特性在Hash Join算法中很有用。
-
这个bitmap使用64bit的整数数字,64bit中只有32bit为bitmap使用。另外的32bit作为一个前缀和的计算用。基本思路如下图所示。图中使用的是8bit的大小,而不是64bit,没有实际上的不同。
-
在这样的设计下面,查找操作就是先检查bitmap,如果bitmap没有设置就肯定不存在。如果设置了,则根据前缀和的信息找到在dense array中的位置。进行一个线性探测,查找释放存在对应的Key-Value。
bkt = hash(key) % |bitmap|; Check bkt’th bit of bitmap; if not set, the key is not present in the CHT else // Find # of ’1’ bits, up to bkt’th bit word = bitmapWords[bkt/32]; bitsUptoBkt = word.bitmap & ~((~0)>>(bkt%32)); // prefixPopCount: # of ’1’ bits in prior words pos = word.prefixPopCount + popCount(bitsUptoBkt); search in array for key, at positions pos, pos+1, .. pos+Threshold-1 if not found, search in OverflowHT
0x22 评估
这里的具体信息可以参看[4].
An Experimental Comparison of Thirteen Relational Equi-Joins in Main Memory
0x20 引言
这篇Paper可以看作是前面Paper的继续研究。在这篇paper中,作者比较了多种Equi-Join算法的实现,并提出了多种的优化手段,比如software-write combine buffers,多种Hash Table的实现,NUMA-awareness的数据放置和调度等。这篇Paper从更加详细的方面说明了前面两篇Paper提出的不同观点。这里将前面提到的Partition-based Hash Join计为PRB,No-partitioning Hash Joins计为NOP, m-way sort merge join即为MWAY。除了这种三种思路外,这里还使用了[4]中提出的一种方法,计为CHTJ。
0x21 基本思路
这里在前面提到的基本思路之上,还加上了另外的一些优化措施,总结如下,
基本的几个:
* PRB, Basic two-pass parallel radix join without software managed buffer and non-temporal streaming;
* NOP, No-partitioning hash join;
* CHTJ, Concise hash table join;
* MWAY, Multi-way sort merge join;
白盒测试中使用的一些变体:
* NOPA, Same as NOP except using an array as the hash table;
* PRO, One-pass parallel radix join with software managed buffer and non-temporal streaming;
* PRL, Same as PRO except using linear probing hashing instead of bucket chaining;
* PRA, Same as PRO except using arrays as hash tables;
优化版本的Parallel Radix Join:
* CPRL, Chunked parallel radix join with software managed buffer and non-temporal streaming;
* CPRA, Same as CPRL except using arrays as hash tables;
* PROiS, PRO with improved scheduling;
* PRLiS, Same as PROiS except using linear probing hashing instead of bucket chaining;
* PRAiS, PRA with improved scheduling;
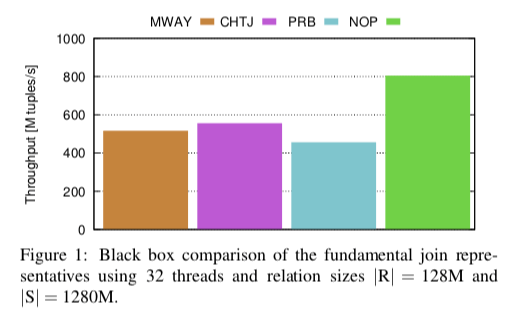
一个基本的黑盒测试结果如下图所示,emmm,好像还是简单的Hash Join性能最高,
- 这里第一个考虑的优化是NUMA-aware的分区方式,在原来的Radix Hash Join的实现中。在第三个的探测阶段中,会发生的一个情况就是一个Socket上面的数据会经常地访问另外Socket的内存。在NUMA上面,访问另外的Socket上面的内存延迟会高上很多。这个会影响到算法的性能。这里提出的一个优化算法是探测阶段在每个Socket局部进行,基本的思路如下图所示。原来Radix Hash Join算法的第二部合并全局的直方图统计被去掉,然后直接进行第3步。这里为了实现只在具体的内存中操作,将探测的数据加载到每个Socket上面。如此的优化使得性能提升月20%。
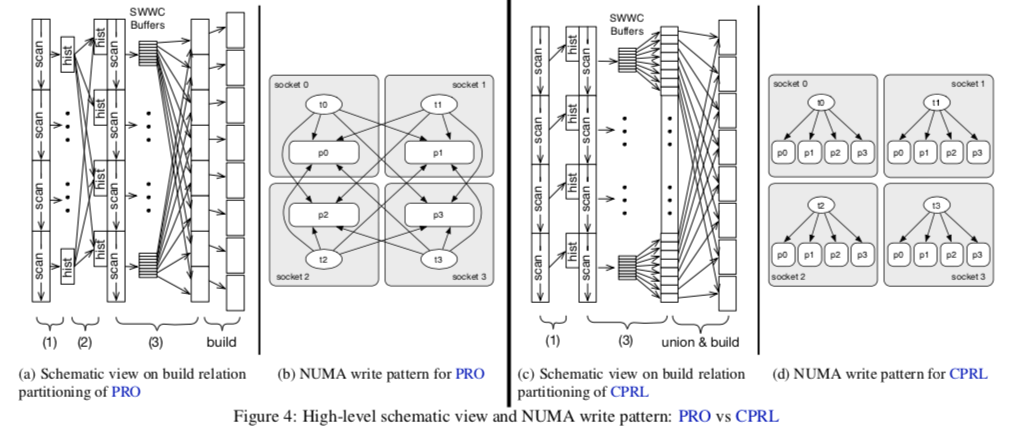
- 另外的一个优化是NUMA-aware Scheduling。这里优化的一个问题就是前面的实现中出现的一种情况是在分区操作完成之后,后面的任务被放入到一个 LIFO-task queue,实际上就是一个stack中被分配给线程运行。这里出现的一个情况就是分配到同一个Socket的任务在queue中安排到了一起,这样分配给第一个Socket的任务开始工作的时候,其它的Socket的CPU是空闲的。这里的一个优化措施就是重新组织任务分配的方式,让所有的资源能在最快的时间都被利用起来。
- 这里还提到的一个优化就是使用更大的Page Size。一个常见的TLB优化。没有什么特别的。至于使用不同的Hash Table实现的,也没有太多特别的东西。
更多的性能比较和得出的结论也看上去没什么意思,¯_(ツ)_/¯。
0x22 评估
这里的具体信息可以参看[1].
参考
- An Experimental Comparison of Thirteen Relational Equi-Joins in Main Memory, SIGMOD ‘16.
- Design and Evaluation of Main Memory Hash Join Algorithms for Multi-core CPUs, SIGMOD ‘11.
- Main-Memory Hash Joins on Multi-Core CPUs: Tuning to the Underlying Hardware, ICDE ‘13.
- Memory-Efficient Hash Joins, VLDB ‘14.
