FAWN: A Fast Array of Wimpy Nodes
0x00 引言
这篇Paper是SOSP ‘09的best paper。FAWN设计为一个使用Flash的存储系统,使用处理能力很弱的单个节点,所以称之为Wimpy Nodes。在FAWN的价格上面实现了一个称为FAWN-KV的KVS。除了提供高性能的表现外,它还实现了远比其它类似系统的高效率,
... Our evaluation demonstrates that FAWN clusters can handle roughly 350 key-value queries per Joule of energy—two orders of magnitude more than a disk-based system.
0x01 基本架构
emmm,在FAWN中使用的是500MHz的嵌入式的CPU,在21个节点的系统中,每个节点能够处理1300的QPS。这个性能看来不是很高。但是在能效方面FAWN表现突出。在总体的架构设计上面,FAWN还是一种类似于Dynamo的设计,
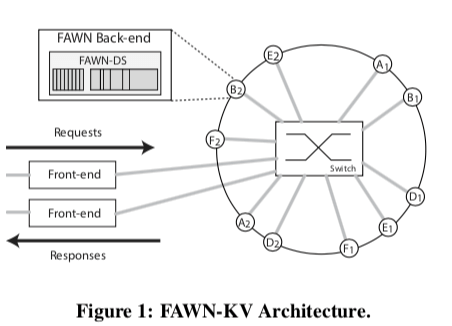
客户端直接请求的是系统的Front-end。这个Front-end将客户端的请求转发给正确的back-end的存储节点。后端的存储节点使用一致性hash来管理,形成一个逻辑上的环形结构。Key会被映射到这个环上面的某个位置。这里实际上和Dynamo的架构基本上是一样的。
The FAWN Data Store
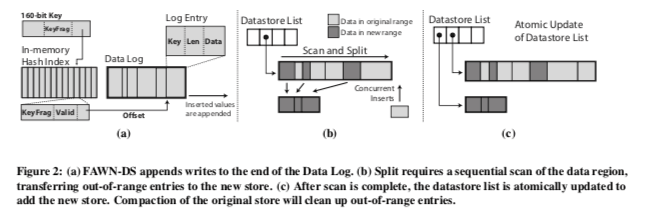
存储层这里FAWN就是一个log-structured的Key-Value Store。这里实际上也就是一个类似一个bitcask的存储模型。一个Hash索引保存在内存之中。数据以append-only的形式保存在Flash上面。这里使用一个160bit的值来作为key-value的可以(估计就是sha1),但是将这样的一整个key保存在内存中的话,内存使用效率会不高。所以这里只会保存key一部分的内容。如下图所示,FAWN这里使用key最低的i个bit作为内存中hash表的寻址。接下来的15bit和一个validbit,加上4byte的在flash上面的位置信息,作为Hash索引的Value。在查找一个key-value的时候,使用key的最低的k个bit在hash索引中查找,并比较KeyFrag,valid用于标记这个key-value是否已经被删除。这里对于可能存在的hash冲突,需要将所有的冲突的key-value都从flash上面取出来,比较完整的key,才能最终确定这个key是否存在,是哪一个?这里加上了一个KeyFrag的思路也被用在了后面的一些系统用,用于减少hash冲突的概率。
/* KEY = 0x93df7317294b99e3e049, 16 index bits */
INDEX = KEY & 0xffff; /* = 0xe049; */
KEYFRAG = (KEY >> 16) & 0x7fff; /* = 0x19e3; */
for i=0 to NUM_HASHE Sdo
bucket = hash[i](INDEX);
if bucket.valid && bucket.keyfrag==KEYFRAG && readKey(bucket.offset)==KEY
then return bucket;
end if
{Check next chain element...}
end for
return NOT FOUND;
对于这类环形的一致性hash设计,还要处理的一个问题就是节点的添加和移除的问题。在这个一致性hash的环形的上面,一个实际的节点会对应到多个的虚拟节点。这里的处理逻辑和一般的一致性hash处理的逻辑没有很大的不同。添加一个节点基本的处理过程如下,
- 新的虚拟节点的添加会使得一个key range进行分裂操作,一个分裂为两个;
- 新的虚拟节点获得R个ranges的副本,其中一个range的Primary为这个虚拟节点,其它的为一般的副本;
- Front-end将这个节点为集群中的新的成员;
- 有的其它的虚拟节点删除它们不再需要处理的key ranges。
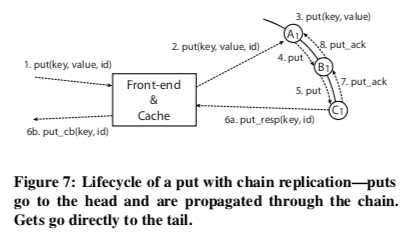
在复制的方式上面,FAWN-KV使用的是Chain Replication。通过key的hash确定到一致性has环上面的一个节点。这个节点会把数据复制到这个环后继的节点。如上图,如果是三副本,会被复制到后面的两个节点。
0x02 评估
这里的详细信息可以参看[1],
NVMKV: A Scalable, Lightweight, FTL-aware Key-Value Store
0x10 引言
这篇Paper名字叫做NVMKV,但是实际上叫做FTL-KV可能更加合适一些。这篇Paper的核心内容就是如何基于FTL来实现一个Hash Table。这篇Paper和很多Key-Value核心思路之一的将随机写转化为顺序写的做法不同。NVMKV上的写入实际上还是很随机的。NVMKV的观点认为现在的SSD随机虚拟也很好,可以支撑很高的性能,
... NVMKV is a lightweight KV store that leverages native FTL capabilities such as sparse addressing, dynamic mapping, transactional persistence, and support for high-levels of lock free parallelism. Our evaluation of NVMKV demonstrates that it provides scalable, high-performance, and ACID compliant KV operations at close to raw device speeds.
0x11 基本思路
NVMKV的基本思路就是利用Key来计算出Hash值,直接找到对应的LBA,读取保存在Flash上面的Key-Value Pair。可能需要对Key做最终的对比以确定两个Key之间是否是精确相等的。未来更好地使用KVS的工作环境,不同于一般的SSD提供的density的地址空间,这里NVMKV引入了Sparse address spaces的概念。这里的Sparse address entries只会在第一次写入操作的时候才会实际地去分配。这样看起来这里和操作系统的虚拟内存空间类似。而这里的FTL就类似于操作系统中的Page Table。这里为了适应这样的设计,这里在FTL Primitive接口中引入了exists和ptrim接口,用于判断一个Sparse address entries是否已经分配了和删除一个分配了的Sparse address entries。这里还引入了一些支持ACID的事务性的接口。

基于FTL实现Hash Table这里就要处理常见的几个问题:如何处理Hash值和实际地址的映射关系,如何处理Hash冲突等,
- NVMKV中,Spare Space被分为了等大小的slot。每一个slot被用于保存一个Key-Value Pair。这个Spare地址空分为了Key BitRange (KBR)和Value Bit Range (VBR)两个部分,前一部分决定了一个地址空间可以保存的Key-Value Pair的数据,后面的VBR决定了KV Pair能够最大的大小。这个VBR实际上就类似于内存虚拟空间中的一个Page
- 在每一个VBR中,也就类似于内存空间中的Page,只会保存一个KV Pair。NVMKV直接使用Key的Hash值来寻址对于的VBR,根据FTL直接寻找到对应的物理位置。同样引入内存空间中按需分配的方式,这里只会在实际使用的时候分配空,比拼Spare Space带来的空间浪费。
- 这样的话一个必须要处理的问题就是Hash冲突的问题。这里NVM化了很大的篇幅说明Hash冲突的概率很小。但是在这么小只要存在这个可能都要有处理的机制。这里就是直接使用 polynomial probing的方式。
0x12 评估
这里的具体信息可以参看[3],
BlueCache: A Scalable Distributed Flash-based Key-value Store
0x20 引言
BlueCache也是一个基于Flash的KVS,同样它的KV的索引也是保存在内存里面的。BlueCache与其他的一些系统不同的地方在与它的结构更加模块化一些,基本的几个模块可以使用异构的硬件去实现。不仅仅能够提供简单的Key-Value的操作结构,还能通过一个Protocol Engine适配不同类型的接口,
... We show that BlueCache has 4.18X higher throughput and consumes 25X less power than a flash-backed KVS software implementation on x86 servers. We further show that BlueCache can outperform DRAM-based KVS when the latter has more than 7.4% misses for a read-intensive application.
0x21 基本架构
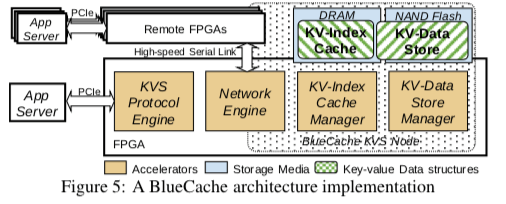
BlueCache是一个抽象化、高度模块化的架构,主要分为下图中的几个部分,
- KVS Protocol Engine,它是一个可以“拔插”的组件。另外它是直接连接在应用服务器上面的PCIe接口上面,将应用的请求转发到对应的KVS服务器。这个KVS Protocol Engine可以使用批量处理的方式来提高系统的性能。Protocol Engin通过一个Network Engin和BluuCache Network连接。
- 在KVS的节点上面,同样是一个Network Engine连接到Bluecache Network。这个节点最基本的两个模块就KV-Index Cache和KV-Data Store。一般KV-Index就是保存在内存之中,而数据保存在Flash中。另外在必要的时候,一部分的数据也可以保存在内存中,一次来提高处理的速度。
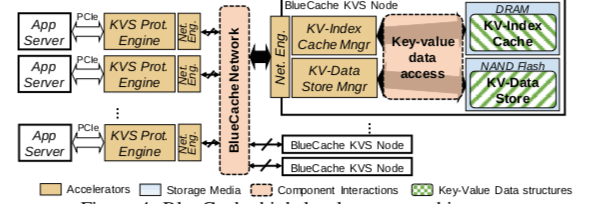
使用异构的硬件来加速也是BlueCache设计的一个特点。BlueCache使用FPGA来实现很对组件的功能,如下图所示。
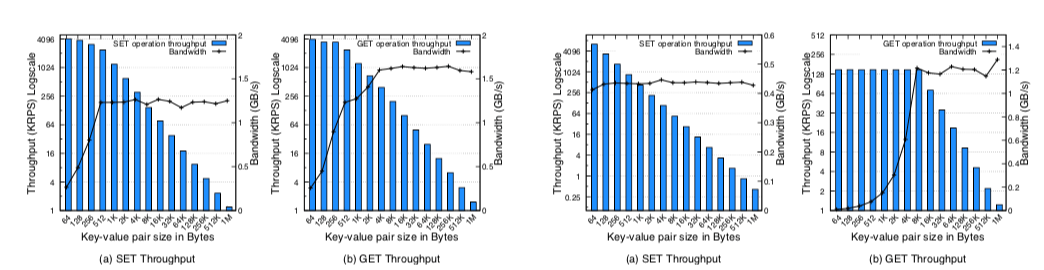
0x22 评估
这里详细的信息可以参看[4],
参考
- FAWN: A Fast Array of Wimpy Nodes, SOSP ‘09.
- Using Vector Interfaces to Deliver Millions of IOPS from a Networked Key-value Storage Server, SoCC ‘12.
- NVMKV: A Scalable, Lightweight, FTL-aware Key-Value Store, ATC ‘15.
- BlueCache: A Scalable Distributed Flash-based Key-value Store, VLDB ‘16.
