FlashKV: Accelerating KV Performance with Open-Channel SSDs
0x00 引言
这篇Paper是一篇关于在Open-Channel的SSD上面LevelDB优化的一篇文章。FlaskKV主要还是要解决这类存储系统在SSD上面运行的时候Log-on-Log的问题。另外一个就是利用好现在的一些SSD的并行性。FlashKV选择直接管理裸设备的方式,绕开操作系统的文件系统层和SSD固件上面的FTL层。在得知了硬件更多的细节的情况下,FlashKV引入Parallel Data Layout、Parallelism Compaction以及其它的一些方式提高了LevelDB在Open-Channel SSD上面的性能表现,
... FlashKV employs a parallel data layout to exploit the internal parallelism of the flash device, and optimizes the compaction, caching and I/O scheduling mechanisms specifically... improves system performance by 1.5× to 4.5× and decreases up to 50% write traffic under heavy write conditions, compared to LevelDB.
0x01 基本思路
FlashKV本质上还是一个LevelDB的修改的版本,所以基本的架构和LevelDB没有很大的区别,FlaskKV的基本架构如下图所示。它在LevelDB的基础之上引入了四个主要的优化来利用Open-Channel SSD提供的功能。这里FlashKV有一个假设,即假设这个SSD内部使用的DRAM是Battery-Backup DRAM,基本就是FlashKV不去触及突然掉电的时候SSD内部一些数据没有持久化的问题,SSD在掉电之后自己可以将这些数据持久化。
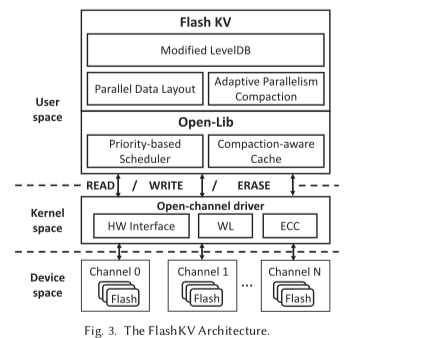
Parallel Data Layout
这个是FlashKV为利用好SSD中多个Channel之间的并行性引入的优化。在FlaskKV中,它将保存SST文件称之为数据文件,其它的文件称之为元数据文件,后者包含了Manifest和日志文件等。在FlaskKV中,分配和回收的粒度是SuperBlock。SuperBlock会跨越SSD中的Channels,如下图所示。而FlaskKV中的SST文件的大小会设置为SuoperBlock的大小。每一个SuperBlock使用一个唯一的ID来表示,代表了Channels内一组一定偏移量内的一组Blocks。FlaskKV这里要维护每一个SST文件到SuperBlock的映射关系。得益于LSM-Tree的设计,SST文件是只读的,FlashKV就可以安装日志式的方式写入到SuperBlock内,而且不用维护一般的SSD里面用FTL维护的逻辑Block/Page到物理Block/Page的映射关系。SST文件会有Block组成(这里的Block不是SSD中的Block),通过将这些Block分散到不同的Channel里面,FlashKV形成了它的Parallel Data Layout的设计。
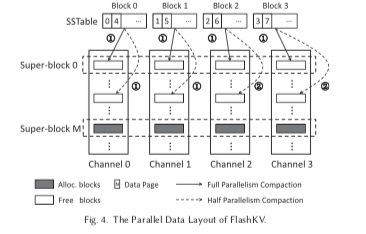
Adaptive Parallelism Compaction
这里的Adaptive Parallelism Compaction是为了解决SSD中读/写性能的差异带来的读/写之间相互影响的问题。比如一个写操作阻塞了同一个SSD Chip里面的读操作的时候,有与写的延迟在SSD中远大于读的操作,这个读的延迟会增大很多倍,而反之写的延迟增大得就比较小。这个问题在Compaction的时候最为明显。LSM-Tree中的Compaction是一个写密集的操作,为了尽可能的快速将Compaction操作完成,现在的很多LSM-Tree的设计都是“全力”去做Compaction。实际上这里采用的策略挺简单,就是在写密集的负载中使用全部的并发性去做Compaction,而在读密集的负载就适当减小这个Compaction操作的并发读,以减少读写之间相互影响。另外,这里FlaskKV使用了两倍于LevelDB的线程去做Compaction。在LevelDB中,在L0的文件达到了一个数量之后就会减慢写请求的操作(kL0_SlowdownWritesTrigger,默认8),到达另外一个阈值(kL0_StopWritesTrigger,默认为12)就会阻塞所有的写请求。LevelDB单线程去做Compaction的设计在一些情况会成为一个系统的瓶颈,这个优化也在另外的一些系统中被采用,
FlashKV adopts two threads to speed up the compaction, which has been proved to be effective and efficient in RocksDB and LOCS. Before compaction begins, the two threads select different SSTables, of which the keys are not overlapped. Then these two threads are able to perform compaction independently, without interfering with each other.
FlashKV使用一个最近时间窗口里面的读写操作的比例来确定是否为写密集,默认阈值为30%。这里早处理L0、L1的Compaction的时候总是利用Full Parallelism。另外的FlashKV的几个优化,
-
Compaction-Aware Cache,在原来的LevelDB中,IO的Cache使用了操作系统的Page Cache,这样做的优化是简单。但是这里的缺点就是不能很好地区分不同类型的写信息,比如客户端引起的写操作和Compaction引起的写操作。而这里的优化就把这两种类型的写操作区分开来,客户端的读的大小一般比较小,而Compaction一次读的比较大(这里设置为2MB)。对于客户端的读请求不使用预取,而后者采用。而且Compaction读出来的数据会被放到LRU链表中最快被驱逐的位置。
-
另外一个也和前面的一个类似。现在的实现是将客户端的IO请求的优先级和Compaction导致的IO请求的优先级设置为一样的。但是FlashKV认为这里应该将客户端的请求的优先级提高,所有这里将IO请求分为foreground requests 和 background requests两种类型。这里由于使用了Open-Channel SSD,可以定义自己的一些策略,
The scheduler is designed based on priority queue. It assigns foreground requests with higher priority than backgrounds. Within the same priority, the read requests are scheduled before write requests, due to the unbalanced read/write performance of flash devices.
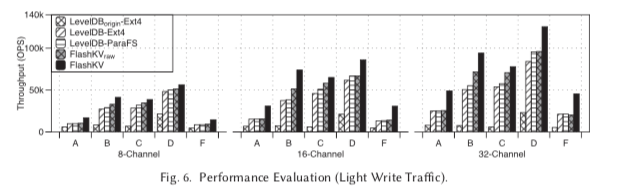
0x02 评估
这里的详细信息可以参看[1],
KAML: A Flexible, High-Performance Key-Value SSD
0x01 引言
这篇Paper将的也是SSD上面高性能的Key-Value Store的实现思路。与前面的利用Open-Channel来改进现在的一些KVS的系统的思路不同,KAML本质上更像是一个SSD,不过提供了Key-Value的一些功能。KAML与前面OSDI ‘14上面的Willow SSD有些类似。Willow的论文里面也讲了在可编程的SSD上面实现一个KVS。不过Willow是一些通用的可编程SSD的框架,而KAML是一个具体的用于KVS的一个SSD。
0x01 基本思路
KAML的基本结构如下图所示。在KAML中,Key的长度固定为8bytes,Value可以变长。这个在一般的Key-Value应用场景中可能会是一个比较大限制,但是在一些场景下面也是很有用的,比如图片存储、类似GFS中的文件Block的存储,使用Record ID的数据库也可以。 KAML实现一个Key-Value的SSD的核心思路就是实现一个新型的FTL结构,KAML直接将映射到具体的物理Page Number,消除了一般的KVS中文件系统,SSD内FTL等开销。同时KAML还是支持事务的,在KAML中实现事务的ACID特性,使用,
- KAML的Put操作多个Key-Value Pairs的原子添加和持久化。隔离性通过Cache层实现。而对于一致性,将其交给应用来实现,因为这个不同的应用对一致性的要求千差万别,放到应用层实现更加合理。
- KAML使用Record记录的锁,这里实现在Cache层。Cache也是KAML一个用于提高性能的一个机制,这里实际上就是利用一个Hashtable来实现。在一个事务提交的时候,KAML将对应的数据写入SSD。这里很像是数据库中的Buffer Pool。
- KAML的事务通过严格的两阶段锁来实现。事务管理器维护一个事务的列表。每个事务处理一个记录的时候要求先获取到这个记录的锁,在事务的提交的时候写入到SSD中,事务Abort的话直接丢弃这些数据。
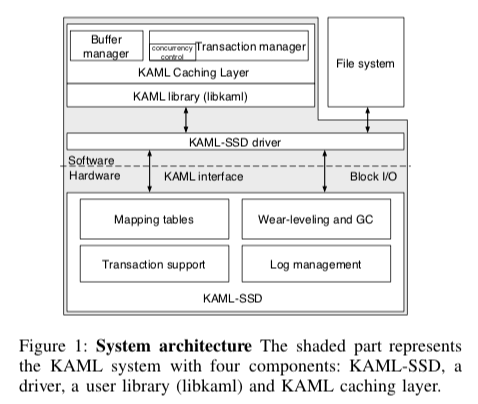
KAML核心就是这里的FTL的设计。这里和一般的SSD存储在很大的不同,主要来源于一个Page可能对用到多个Key-Value Pairs,也可能一个Key-Value对应到多个Pages。这里FTL的具体实现Paper好像没有细讲,只有关于利用Namespace来降低SSD的SRAM占用,只有正在被使用的Namespace里面的Mapping Table才会被加载。Paper中使用的Page的大小为8KB,加上256bytes的带外的数据,KAML将8KB分为64个固定大小的Chunk,哪一个Chunk被使用了有带外数据里面的一个bitmap指明。由于SSD写入的最小粒度为一个Page,这里利用内存先Buffer住一些写入数据,在合并到一个Page里面写入是提高性能和空间利用率的关键。
0x12 评估
这里的具体信息可以参看[1]。这个起来很有趣,直接用裸设备实现KVS。
An Efficient Design and Implementation of LSM-Tree based Key-Value Store on Open-Channel SSD
0x20 引言
这篇Paper比前面的FlashKV更早的利用Open Channel SSD优化KVS的一篇文章。优化的目标也是LevelDB,环境也是Open-Channel SSD。这里的系统称之为LOCS,主要从如何利用SSD内部的并行性、优化WAL以及流量调度等方面优化,
... Compared with the scenario where a stock LevelDB runs on a conventional SSD, the throughput of storage system can be improved by more than 4× after applying all proposed optimization techniques.
0x21 基本思路
LOCS的基本架构如下图,它本质上也是一个LevelDB的优化版本。这里一个最大的区别就是在LevelDB和存储层之间家如了一个IO请求调度层。这里很容易可以看出LOCS和FlashKV利用SSD内部并行性思路上面的区别,在LOCS上的思路类似计算机科学中很多的任务分发的模式,LevelDB上层产生的IO请求会被分发到调度层的多个队列,这写队列会对应都SSD中的Channel,类似于一个Server的角色。
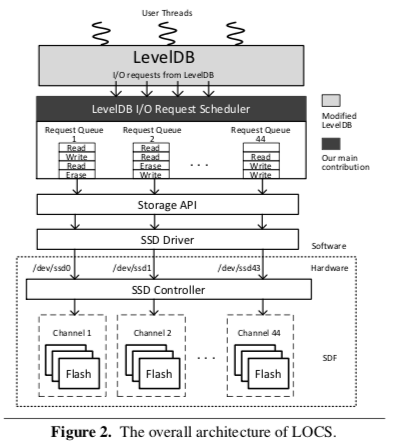
LOCS这里的第一个优化和前面的FlashKV类似,都是优化了kL0 CompactionTrigger,kL0 SlowdownWritesTrigger和kL0 StopWritesTrigger三个参数的设置。第一个就是调大了这里参数的设置。另外一个就是增加了后台Compaction线程的数量,LevelDB的线程数量是为HDD的环境设计的,而LOCS面向的Open-Channel SSD有更大的并行性,
... Additionally, we do not need to block write requests until all Level 0 SSTables are compacted. Instead, we modify LevelDB to make sure that it will accept user write requests again when the number of Level 0 SSTables is less than the half of kL0 CompactionTrigger.
在WAL这里, LOCS引入了NVM。日志先写入到NVM中,Memtable持久化之后就可以直接丢弃。这里实际需要的NVM的空间其实是很小的。
调度和分发策略
Paper的主要部分就是这一节。这里主要就是上图中这些IO请求调度和分发的优化。LOCS先尝试使用节点的RR的方法策略,这里以2MB的粒度方法这些请求,这个大小于LevelDB的SST文件的设置直接相关。这样做的优点就是节点,不过这样简单的方法缺点也比较明显,容易导致负载不均衡的问题,影响到并行性的发挥。于是这里引入了Least Weighted-Queue-Length Write分发策略,每次将请求添加到Weight最少的里面,Weight的计算方式: \(\\ Length_{weight} = \sum_{1}^{N}W_i \cdot Size_i\) N代表了请求的数量,W代表了权重,Size代表了每个请求的尺寸。W取决于请求的延迟。写入操作和擦除操作的Size是确定的,但是读操作的Size会根据请求变化。
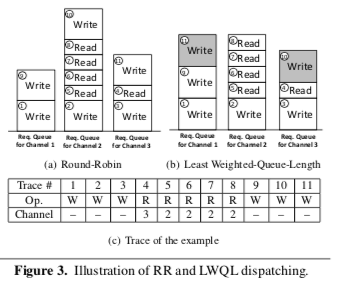
这里分发任务还要考虑的一个就是Compaction操作。FlashKV和LOCS一样区分了不同原因导致的请求。这里LOCS区分了有Memtable Dump尝试的写入请求和Compaction产生的请求。对于后者,其请求的模式是比较容易预测的。这里考虑到Compaction操作过程中读-写的循环操作,如果在同一个Channel里面的话前一轮的Compaction操作会影响到后一轮的操作。所以LOCS这里会安排相邻的Key范围的SST文件尽量不会保存到同一一个Channel里面。基本的算法如下,
1. 在Manifest文件中记录每一个SST文件所属的Channel。Manifest文件还会记录组成一个Level的所有的SST文件,包含Key范围的信息。
2. 每次由Compaction产生的SST文件,先找到安装前面的Dispa算法选出的Channel,如果这个Channel里面有超过(>=)4个Key有重叠的下层的SST文件,则跳过这个Channel,
3. 重复操作,直到找到为止(这里应该要处理没有完全合适的情况).
LOCS另外的一个优化就是Block的擦除的操作。擦除操作的延迟在SSD的操作中是很高的,LOCS中主要在Compaction操作中产生。由于擦除操作带来的高延迟的问题,可能造成队列的不平衡,这里的处理方式是推迟擦除操作,直到这里有足够多的写操作,
... This is because the write requests can help balance the queue length... In LOCS, we set up a threshold T-Hw for the ratio of write requests. The erase requests are scheduled when the ratio of write requests reaches the threshold. Note that the erase requests are forced to be scheduled when the percentage of free blocks are lower than a threshold.
0x22 评估
这里的详细信息可以参看[3].
参考
- FlashKV: Accelerating KV Performance with Open-Channel SSDs, TECS ‘17.
- KAML: A Flexible, High-Performance Key-Value SSD, HPCA ‘17.
- An Efficient Design and Implementation of LSM-Tree based Key-Value Store on Open-Channel SSD, EuroSys ‘14.
