RIPQ: Advanced Photo Caching on Flash for Facebook
0x00 引言
这篇Paper是关于Facebook利用Flash来作为图片Cache的方法。Facebook关于图片存储后段为Haystack 和 F4。利用Flash作为Cache可以有比内存大得多的存储空间,而RIPQ的出现是为了解决之前Facebook使用Flash作为Cache方法的一些问题。博客文章[1]是一个很好的总结。这篇Paper提出了一个RIPQ,即Restricted Insertion Priority Queue这样一个框架,用于在此基础上实现多种缓存算法,
... Our evaluation on Facebook’s photo trace shows that these algorithms running on RIPQ increase hit ratios up to ~20% over the current FIFO system, incur low overhead, and achieve high throughput.
0x01 发展过程
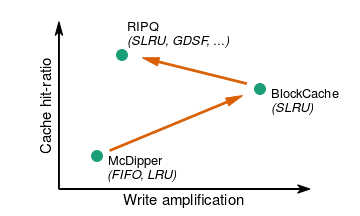
在开始的时候,出于内存作为图片缓存成本太高,容量太小的缺点。Facebook使用了一个基于SSD的McDipper来作为图片的缓存,使用FIFO的替换算法。在[1]中提到,在McDipper中虽然也实现了一个近似的LRU算法,但是能获取收益的提高很小,并没有实际使用。McDipper虽然写放大是最小的,但是同样的,缓存命中率也是最小的。此后Facebook有开发了BlockCache的算法,使用SLRU缓存替换算法,在缓存命中率上面得到了比较大的提高。BlockCache的基本思路就是将一个Block作为在Segmented LRU算法中数据操作的单位。在这里Block设置的大小为64MB。保存在SSD上面数据会在内存中保存一个索引的信息,记录对应的数据项在SSD上面对应的Block中的偏移信息。Segmented LRU在内存中维护了一个LRU信息的链表,链表中的节点对应一个block。
当缓存命中的时候,这个数据项所在的Block对应的节点会被移动到Segment更加靠前的位置(在内存中的链表中操作)。而处理Cache Miss时,新的数据会被写入到一个Buffer内,这个Buffer的大小就是一个Block的大小。一个Block Buffer写满之后,会被整体写入到SSD中。在空间不足的时候,BlockCache驱逐最后的一个Block快,之后的空间会被重新使用。在这里可以猜测McDipper中使用的方式应该很类似于Bitcask的方式,而此基础上实现FIFO的替换算法是很直观简单的,而使用LRU之类的算法就存在得不少的问题。而BlockCache则通过Block划分的时候优化了这些缺点。但是BlockCache也还是存在不少的缺点的。在[1]中主要提到了两点,
- BlockCache在很粗的粒度上面追踪数据的访问模式,如果一个Block中的少数几个数据项访问频繁,但是其余的部分访问很少。BlockCache会将这些“冷”一些数据当作热点数据来处理。减小Block的大小可以缓解这个问题,但是造成的负面影响就是造成了更大的写放大。
-
BlockCache的工作方式和SLRU的替换算法绑定在一起,不方便去实现其它算法。在Facebook的观察中,Greedy Dual Size Frequency (GDSF)算法能够实现更高的命中率。
### 0x02 RIPQ 基本思路
BlockCache的进一步进化就是这里的RIPQ。RIPQ是一个基于优先队列抽象的方式,提供以下基本的操作原语,
• insert(x, p): insert a new object x with priority value p.
• increase(x, p): increase the priority value of x to p.
• delete-min(): delete the object with the lowest priority.
一次缓存命中的时候,一个increase操作提高对应object的优先级。由于缓存缺失导致的新数据添加,使用insert借口来添加。Delete-min操作以为着将一个数据置于最低优先级,实际上用于驱除一个数据项。这里优先级的决定可以是多种因素,比如根据访问时间、访问频率等等的因素。常见的优先级队列使用绝对的优先级。除了绝对优先级,RIPQ还使用了一种相对的优先级,一个对象的优先级会被设置为[0,1]之间的一个数。0.2表示有20%的数据低于这个对象的优先级。
基本架构
RIPQ的基本架构如下面的图3。RIPQ的优先级队列抽象建立在一个内存中的IdexMap和一个Flash上面的一组Block组成。具体的一些数据结构如图4,除了主要的Index Map之外,RIPQ还包含了Queue Structure。RIPQ中的Queue Structure包含了多组的Section。Sections定义了队列中数据添加的位置,一个Block为一次写入到Flash上面的数据单元。相对优先级被划分为K个section,将[0,1]划分为K个部分,[1, p_k−1],…,(p_k, p_k−1],…,(p_1,0]。一个对象被添加的时候,会添加到这个对象优先级对应的Section的头部。这个操作也意味着隐式地将这个Section以及优先级更低的Section中的对象的优先级降低。这样,在RIPQ中,对象的优先级在没有提升优先级操作的时候,优先级会一直下降,直到最后被驱逐。这里的参数K是一个操作“准确性”和内存消耗之间一个取舍。在Paper中的选择的参数为K=8。在Block大小为256MB的时候,消耗大约2GB内存。
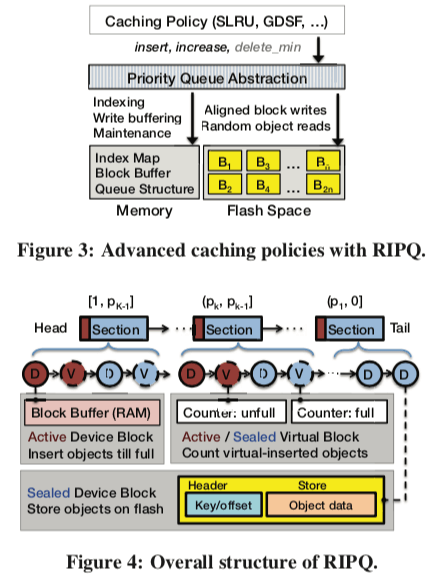
每一个Section只会包含一个Active的Block,只有它可以添加数据。其它的为Device or Vritual Block。在一个Block被写入到Flash上面的时候,转化为一个sealed device block。另外,对于一个对象优先级改变的情况,RIPQ使用Lazily更新的方式避免数据冗余。这里做饭就是使用Virtual Blocks追踪对象的移动情况。一个Section头部的active virtual block用于处理优先级增加的virtually-updated操作。这个Block同样会在active block写入Flash的时候转变为sealed状态。virtually-updated之后涉及到内存操作,主要就是Index Map结构中对象在Flash上面位置信息的更新,同时会改变对用Block的尺寸。在驱逐一个device block的时候,查看这个block里面的对象是否有优先级增加的操作。这里就是根据Index Map中的信息来处理。如果是,则需要重新添加这些对象对应的位置,同时会删除virtual object的信息。这样,RIPQ最多只需要保存一份的数据副本。通常情况下,virtual block是很小的,且保存在内存中,
Device blocks occupy a large buffer in RAM (active) or a large contiguous space on flash (sealed). In contrast, virtual blocks resides only in memory and are very small. Each virtual block includes only metadata, e.g., its unique ID, the count of objects in it, and the total byte
size of those objects.
0x03 实现
在Paper中主要讨论了两种缓存替换算法。Segmented-LRU和Greedy-Dual-Size-Frequency,
-
Segmented-LRU,SLRU的实现利用了RIPQ中Section的特点。这里缓存命中和驱逐就是对象在不同Section中的操作。它使用的是相对的优先级。分别在Cache Miss和Cache Hit的时候执行的操作: \(insert(x, \frac{1}{L}),\ icrease(x, \min(1, \frac{(1+\lceil p·L \rceil)}{L})). \\\)
-
Greedy-Dual-Size-Frequency,GDSF算法处理考虑对象的访问模式之外还会考虑对象的大小。在GDSF中的一个权衡就是 object-wise和byte-wise中命中率的权衡。它分别在Cache Miss和Cache Hit的时候执行的操作: \(insert(x, Lowest + \frac{c(x)}{s(x)}), increase(x, Lowest + c(x)\frac{\min(L, n(x))}{s(x)})\) 这里的c(x)为一个定义的一次缓存缺失的惩罚,s(x)为对象的大小。Lowest为目前最低优先级的大小。在Paper中提到GDSF算法能够实现更加好的效果。
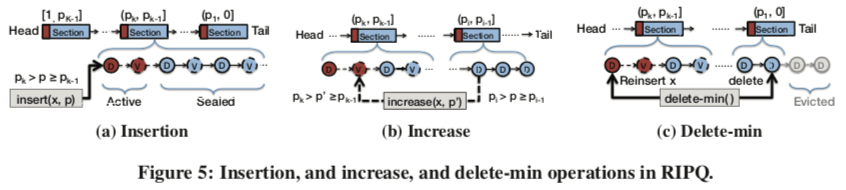
在RIPQ中,三个基本的接口实现的逻辑,
-
Insert(x, p),根据p的值找到对应的section,然后添加到对应section的active block中。如果这个block写满了,则将其刷入Flash;
-
Increase(x,p),RIPQ避免直接移动磁盘上面的数据。而是添加到对应section的active virtual block中。逻辑上面的数据移动。在内存中的Hash Table索引中,会记录一个对象的virtaul block的ID。这步的操作实际上就是索引中对应entry的virtual ID的修改。同时会更新对应section和block的大小等的信息。这步操作不会设计到Flash的操作。
-
Delete-min()。保存在Flash上面的Blockd的数据会有一个阈值,到达了这个阈值之后,RIPQ就会执行驱逐操作。这里要处理几个问题。第一个就是处理被移动到其它Block的数据的处理,这里要读取出来全部的Key,在内存中的索引中查找这个信息。如果是被移动的,则要数据统计到对应section的actove block中,即一个重新添加的操作。最后还要修改索引中的virtual block的信息,
These additional writes cause implementation write amplification, which is the byte-wise ratio of host-issued writes to those required to inserted cache misses. RIPQ can explicitly trade lower caching algorithm fidelity for lower write amplification by skipping materialization of the virtual objects whose priority is smaller than a given threshold, e.g., in the last 5% of the queue.
在RIPQ的内部操作的实现中,Facebook还讨论了其它的几点内容,
-
Section的合并和分裂的操作,在一个section太大or太小的时候,RIPQ会分别对section做分裂和合并的操作。RIPQ中一个参数α决定了section的平均大小。一个section的对象数据or以byte计的大小超过了2α,即理想平均的两倍时候,执行分裂的操作,同样地小于α/2的时候执行合并的操作。同样地,这里也不会去移动flash上面的数据,
No data is moved on flash for a split or merge. Splitting a section creates a new active device block with a write buffer and a new active virtual block. Merging two sections combines their two active device blocks: the write buffer of one is copied into the write buffer of the other. -
支持绝对优先级,使用用一个histogram统计信息,这个histogram有一组的bin组成。这个bin根据它们相应的大小进行合并和分裂的操作,bin的数据可以远大于section的数量。
0x04 SIPQ 和 优化
SIPQ是RIPQ对内存有限缓存的一种变体,SIPQ即Single Insertion Priority Queue (SIPQ)。SIPQ将Flash的存储空间当作是一个缓存写入的空间。SIPQ之会顺序写入数据。同时在内存中维持一个对象key的优先级数据。这里只会保存key,由于在内存有限的环境中节约内存。和RIPQ一样,这里也会有重新添加操作造成的写入放大的问题。SIPQ这里为了缓解写入放大的问题,SIPQ只会在内存中保存一部分被Cache对象的key。重新添加操作的时候只会考虑这些Key对应的对象。
优化
在Paper[2]之外,Facebook还在一片Blog文章中提到了RIPQ的另外的几个优化。在RIPQ在生产环境中使用发现,数据的局部性使得RIPQ的写入放大得到缓解。但是这样也带来了另外的负面影响。热点数据的频繁访问时得这些数据都集中在少数几个连续的Blocks中,这里将这些Block称之为Hot Block。当驱逐一个热点Block时,RIPQ的工作方式会导致大量的数据重新添加操作。这样会导致一个性能的明显降低。这里使用几种方法来优化这个问题,
- 当驱除一个Block的时候,如果这个Block中重新添加的数据大于一个比例,比如0.6。就选择直接将这个Block移动到链表的头部,而不是执行驱逐操作。对于一些特别热点的数据块而言,它会执行从头到尾,有移动到头的重复操作。
- 然后RIPQ又使用了一种指数重新添加操作的方式(选择一个系数,比如0.5),这里有个就是和上个优化方式分配使用,当这个重新添加系统达到一个比例阈值的时候,选择一个靠近尾部的重新添加比例小于一个值的Block进行驱除操作,比如0.1。
通过这些优化算法,RIPQ获得了更加稳定的性能,避免了一些性能上的“毛刺”。
0x05 评估
这里的详细信息可以参看[2].
Demystifying Cache Policies for Photo Stores at Scale: A Tencent Case Study
0x10 引言
这篇Paper中感觉就是一个核心的idea,就是一种预取的机制
we propose to incorporate a prefetcher in the cache stack... . Evaluation results show that with appropriate prefetching we improve the cache hit ratio by up to 7.4%, while reducing the average access latency by 6.9% at a marginal cost of 4.14% backend network traffic compared to the original system that performs no prefetching.
0x11 Case Study
在QQPhoto中上传的图片会被保存为多种的分辨率,而且不同分辨率的照片有着不同的访问模型。访问设备多为移动设备。低分辨率的访问频率一般而言会高于高分辨率的。下图中不同分辨率的图片访问频率的差别给预取提供了参考。
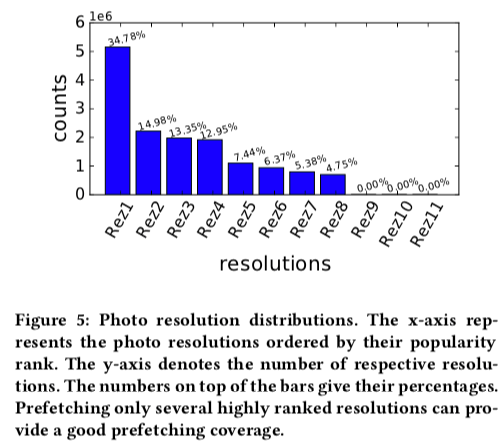
另外,QQPhoto会周期性的预取数据。在一个周期内上传的数据,会根据访问情况预取这个周期内上传图片最频繁访问的分辨率版本。
0x12 评估
这里的具体信息可以参看[3].
参考
- https://research.fb.com/the-evolution-of-advanced-caching-in-the-facebook-cdn/, Facebook Blog.
- RIPQ: Advanced Photo Caching on Flash for Facebook, FAST ‘15.
- Demystifying Cache Policies for Photo Stores at Scale: A Tencent Case Study, ICS ‘18.
