Redundancy Does Not Imply Fault Tolerance: Analysis of Distributed Storage Reactions to Single Errors and Corruptions
0x00 引言
这是一篇很有意思的Paper,研究的是在分布式存储系统中,很常用的一个策略就是使用数据保存多份的情况。这篇Papers中使用了一个基于FUSE的用户空间的文件系统errfs来进行错误注入,发现了很多系统虽然使用了副本冗余来实现更高的可用性,但是在文件系统故障 or 存储介质出毛病的时候,这些系统不同程度的出现了各种毛病,
... We find that modern distributed systems do not consistently use redundancy to recover from file-system faults: a single file-system fault can cause catastrophic outcomes such as data loss, corruption, and unavailability.
0x01 背景 & 测试
这篇Paper讨论的背景就是文件系统可能存在的诸多的故障,这些故障可能是文件系统本身导致的,比如文件系统的Bug数量是Linux系统中Bug最多的部分之一。另外一个就是存储硬件也不是完全可靠的,一是它的固件可能存在Bug,另外就是存储介质本身也可能有这种的故障,比如bit位翻转之类的。Paper中将这些可能出现的问题分为了两类,1. Block Errors,这类故障时文件的某些数据块变得无法访问,2. Block Corruptions,这类型的故障的数据块可以访问,但是里面的数据不是期望中的数据。这些问题的原因是多样的,
-
在磁盘在访问一个数据块的时候,它可能遭遇到一些问题,比如ECC校验不通过,这个时候会向文件系统返回一个错误。文件系统在这种情况下可以察觉到这些错误。这些错误出现的频率可能并不低,
... A previous study of over 1 million disk drives over a period of 32 months has shown that 8.5% of near-line disks and about 1.9% of enterprise class disks developed one or more latent sector errors. More recent results show similar errors arise in flash-based SSDs. -
硬件如果没有一些机制 or 这些机制失效 or 硬件的固件出现Bug的情况下,就可能之间给文件系统返回错误的数据,这些错误的数据有可能就直接被返回给应用,
... in a study of 1.53 million disk drives over 41 months, showed that more than 400,000 blocks had checksum mismatches. Anecdotal evidence has shown the prevalence of storage errors and corruptions. -
一些情况下,文件系统在遇到底层的一些问题的时候,会直接将这些错误 or 错误的数据返回到应用,比如ext4文件系统。另外的一些系统比如BtrFS和ZFS,会将这些转化了一个错误信息。这些在这里都称之为 file-system faults。

为了更好的测试这些存储系统在出现这些故障的时候的表现,这里使用了错误注入的方式。这里注入的错误有以下的一些特点,1. 都是单个节点上面当个文件系统上面的单个Block的错误,2. 这里注入错误的地方只是应用层面的数据,而不会是文件系统的元数据。这里使用了作者开发的一个errfs以及一个测试工具errbench,
... errfs can inject two types of corruptions: corrupted with zeros or junk. For corruptions, errfs performs the read and changes the contents of the block that is marked for corruption,... errfs can inject three types of errors: EIO on reads (read errors), EIO on writes (write errors) or ENOSPC and EDQUOT on writes that require additional space (space errors).

0x02 测试结果
一般这些存储系统的使用者的期待的情况是即使在出现这些错误的情况下,这些系统也能从这些错误中回复。在很多的分布式存储系统中,这些数据都是保存多份的,所以理论上是有这个恢复的能力的。这里会观察在遇到这些故障之后节点本地的行为和对整个系统的影响。下面是Paper中一些系统的测试结果,
-
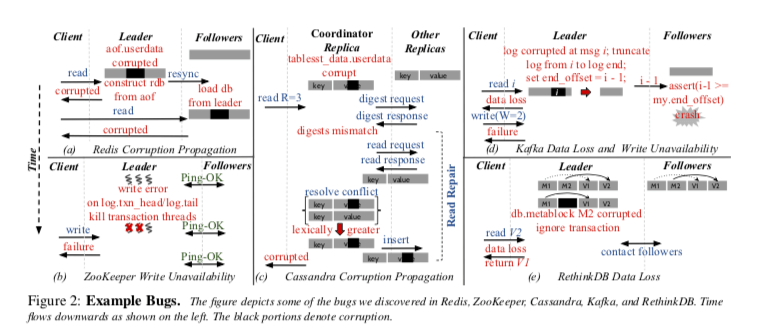
Redis,这个是表现地很差的一个系统。在AOF的模式中,Redis对保存的数据没有使用Checksum,也就是说它不能发现里面的一些数据错误。而这些数据错误会被发送到其它的从节点,从而造成一些Corruption的数据传播到整个系统。如果这些错误出现在AOF的元数据的部分,可能造成节点的Crash。如果发生在主节点上面,由于这些数据被发送到从节点的,也就可以导致其它的节点Crash。
-
Zookeeper,Zookeeper通过使用Checksum能够发现数据中存在的问题,不过发现直接简单地表现为节点的Crash。由于Zookeeper的机制可以容忍一些节点的Crash,它可以容忍这些错误。但是在一些写入错误的情况下,Zookeeper不能从中恢复,
... On write errors during log initialization, the error handling code tries to gracefully shutdown the node but kills only the transaction processing threads; the quorum thread remains alive (partial crash). Consequently, other nodes believe that the leader is healthy and do not elect a new leader. However, since the leader has partially crashed, it cannot propose any transactions, leading to an indefinite write unavailability. -
Cassandra,Cassandra的问题出现在即使使用了Checksum,能够发现出问题的数据。但是在出了问题的时候,使用的策略是从副本中选择timestamp上最新的版本。但是最新的不一定就是正确的。
-
Kafka,Kafka在读/写发生错误的情况,它的处理流程可能导致系统的不可用。
-
Paper中还测试总结了其它的一些分布式存储系统的行为。都或多或少的存在一些问题。
0x03 总结
这篇Paper给出的内容还是很有趣的。之前在网上看到过一篇关于Amazon的云服务没有使用Checksum来检查数据的准确性,从而造成过严重的问题。号称高可用的系统看来是不能假设文件系统 or 存储介质是这么“老实”的,存什么东西进去,就能原封不动的取出来。
Protocol-Aware Recovery for Consensus-Based Storage
0x10 引言
这篇Paper可以说是前面这篇Paper的后续,作者相同,这也是FAST ‘18的一篇Best Paper。如果说上面的Paper是提出问题,这篇Paper则是提出在replicated state machine (RSM)的系统中面对这些问题的解决方案,
... We demonstrate the efficacy of PAR through the design and implementation of corruption-tolerant replication (CTRL), a PAR mechanism specific to replicated state machine (RSM) systems. We experimentally show that the CTRL versions of two systems, LogCabin and ZooKeeper, safely recover from storage faults and provide high availability, while the unmodified versions can lose data or become unavailable.
0x11 存在的一些方法
Paper中这里先讨论了一下现在在RSM系统存在的一些从存储故障中恢复的方法,
-
NoDetection,这种方法就是简单的什么都不做,也就是基本上就是假设存储的介质和文件系统都是可靠的。这类系统显然是完全不可取的。
-
Crash,使用了Checksum,发现Checksum对不上的时候会导致节点Crash。一些情况下会对影响到系统的可用性。
-
Truncate,截断可能出问题的数据,系统进行运行。这样在一些情况下是有利用系统可用性。不过可能导致数据丢失的问题。
-
DeleteRebuild,删除出问题节点上面的所有数据,这个节点重新开始。同样的,这个可能导致数据丢失的问题。因为这个节点上面的一些正常的数据删除可能导致一些数据副本的数量没有达到半数以上。
-
MarkNonVoting,Google使用的一种方法,删除自己的数据,并标记自己没有投票的权利,
a faulty node deletes all its data on a fault and marks itself as a non-voting member; the node does not participate in elections until it observes one round of consensus and rebuilds its data from other nodes. By marking a faulty node as nonvoting, safety violations such as the one in Figure 2 are avoided.这种方法也存在另外的一个问题,就是删除了数据都是不一定删除了所有的状态,比如它做出的一些Promise。
-
Reconfigure,移除出问题的节点,用新的节点替换。这种情况可能导致一些可用性的问题,也不建议在实际的系统中使用。
-
Byzantine-fault-tolerant,理论上能够处理这些的情况,但是缺点在于BFT的成本太高了。
针对这些问题,这篇Paper提出了自己的方法CTRL(反正就是现在的都不行,得xx来解决,emmmmm)。
0x12 Corruption-Tolerant Replication
CTRL这里对RSM的系统存在这样的几点假设,1. Leader-based,系统中存在一个单个节点的Leader,2. Epochs,将时间划分为逻辑上的时间单元,称之为epoch,or 其它类似的意思的名字,3. Leader Completeness,一个节点不会给比它的数据更加旧的candidate节点投票。这里可以容忍下图表示的一些由存储系统导致的一些问题。CTRL从Log,Snapshots和Meatinfo三个方面入手,进行处理。

处理这类问题的第一步就是发现这些问题。这里有这样的几种方式,1. 通过存储系统操作返回的错误值,2. 通过Checksum发现数据以及Corrupted。另外,文件系统导致的一些问题,比如丢失和无法打开文件、文件数据缺失等,可以通过文件系统的一些操作可以得知。在发现已经发生错误的情况下,这里通过⟨epoch, index⟩定位Log中具体出现错误的位置,同样地在另外的部分也可以有类似的方法定位出问题的数据,比如Snapshots中使用⟨snap-index, chunk#⟩。这里还有另外的一个问题要处理,就是区分Crash导致的问题,还是Corruption导致的问题。比如在Checksum不对的情况下,可能是节点Crash导致数据写入一部分从来导致的,也可能是数据Corruption导致的。在现在很多的RSM的系统中,把这两种行为合并为一种,都认为是Crash导致的。如果对这些数据做丢弃的处理,如果真的是Crash导致的,则丢弃也不会导致什么问题,但是如果是Corruption导致的,则可能导致数据丢失(丢弃之后这个数据的副本数量到不了一半以上的数量)。这里一个区分的策略是使用Commit的信息,但是仍然存在一些难以区分的问题,这里的解决方式是如果不能区分就当做Corruption处理,不会影响正确性。
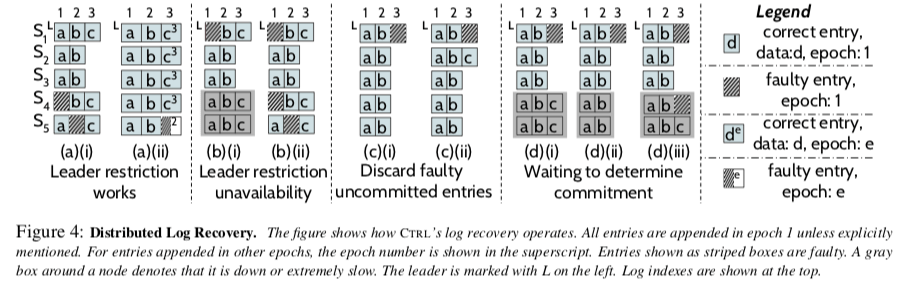
如果限制存在错误记录成为Leader,则处理的方式比较简单,Follower这里的问题数据直接从Leader中恢复即可。而这样的限制可能导致在一些情况下系统不可用,比如上图中b的情况,
... The system will be unavailable in cases such as the ones shown in (b): a leader cannot be elected because the logs of the alive nodes are either faulty or lagging. Note that even a single storage fault can cause an unavailability as shown in (b)(i).
为了消除这种限制,这里引入了Ledaer修复自己Log的方法。这里要处理的一个问题就是确定一个Log记录是否已经提交。这里实际上就是采用询问Follwer的方法,如果半数以上的节点报告没有这个记录,则认为没有提交,这个记录就可以安全地抛弃。在提交的情况下,Leader就可以从Follwer中恢复。但是一些情况下,这个判断也不是那么容易,比如上图中d的前面,s1位Leader的时候,询问其它节点,但是s4和s5不能及时回复(已经down了 or 慢了),这样就需要等待。另外一些极其特殊的情况,比如d(iii)出现来了两个节点的复制,会导致不可用。Leader的恢复是难点,基本的协议总结如下: Leader询问Follwer,可能出现三种回复,
- have,存在⟨epoch:e, index:i⟩的记录,且这个log没有出现存储故障;
- dontHave,没有⟨epoch:e, index:i⟩的记录;
- haveFaulty,存在⟨epoch:e, index:i⟩的记录,但是出现了故障。
针对这几种情况,Leader的做法:1. 修复即可,2. 如果半数以上说没有,则丢弃这个记录,3. 等待情况1 or 2发生。另外的Snapshots,Meteinfo和Log的恢复没有很多不同的地方。从这里也可以看出了,实现一个能够应对这种情况的正确的Paxos之类的算法是很困难的。
0x13 评估
这里的详细信息可以参看[2].
参考
- Redundancy Does Not Imply Fault Tolerance: Analysis of Distributed Storage Reactions to Single Errors and Corruptions, FAST ‘17.
- Protocol-Aware Recovery for Consensus-Based Storage, FAST ‘18.
