Shenango: Achieving High CPU Efficiency for Latency-sensitive Datacenter Workloads
0x00 引言
Shenango是Arachne这样的系统的继续优化,实际上都是网络栈Dataplane的一个优化。Shenango聚焦于实现高的CPU效率方面。为了实现高的CPU效率,Shenango会在一个很小的时间粒度-5us-内决策CPU核心的重新分配。实现高效的重新分配主要基于两点,1. 一个高兴的算法用于实现需要进行重新CPU核心分配,2. 一个IOKernel的特权组件,运行在指定的CPU核心之上,编排CPU核心,
Shenango achieves tail latency and throughput comparable to ZygOS, a state-of-the-art, kernel-bypass network stack, but can linearly trade latency-sensitive application throughput for batch processing application throughput, vastly increasing CPU efficiency.
0x01 基本思路
Shenango核心的重新分配的目的是为了给应用尽可能分配少的CPU核心,但是有不至于导致compute congestion的现象。类似的系统有之前的Arachne,Arachne是一个完全用户态的线程库。Arachne重新分配一个核心需要29us的时间。而IX要求更多的时间。之前的系统使用通常使用延迟、吞吐和核心利用率来估计应用需要CPU核心的数量。但是这些指标都不能在微妙的级别的interval内应用。Shenango同时考虑线程和packet来探测compute congestion的信号,另外引入一个congestion detection algorithm来探明一个应用是否能从分配更多的核心中受益。这个算法要求细粒度的,高频率的观察每个应用的线程和packet排队情况。所以这里Shenango引入了一个IOKernel,IOKernel指定一个核心运行的、忙轮询的进程,IOKernel运行在特权态。IOKernel通过忙轮询的方式在微秒级别的粒度观察观察每个应用的线程和packet排队情况。另外,
-
Shenango引入了一种packet steering机制。通过使用packet steering rules机制来快速实现核心的重新分配。
The result is that core reallocations complete in only 5.9 μs and require less than two microseconds of IOKernel compute time to orchestrate. These overheads support a core allocation rate that is fast enough to both adapt to shifts in load and quickly correct any mispredictions in our congestion detection algorithm. -
应用运行在一个runtime中,通过共享内存和IOKernel交互。每个runtime不被信任的,并提供线程、mutex和信号量之类的编程的基本工具。应用会链接Shenango的runtime。在应用启动的时候,runtime会创建多个内核线程(pthread),每个内核线程有一个本地的runqueue。应用的逻辑使用一些保存在这些runqueue中的轻量级的用户基本的线程来运行。不同核心之间的负载均衡通过任务窃取的方式来处理。这里与go runtime有些类似,不过没有IOKernel,用户态线程这里称之为uthread,而内核态线程称之为kthread。
0x02 IOKernel
IOKernel组件运行在一个指定的核心上面,主要的作用有两个,一个是决定一个应用需要分配多少的CPU核心,要分配的话分配那一个CPU核心;另外一个就是Bypass Kernel的方式处理所有的网络IO。它通过忙轮询的方式直接轮询NIC的接受队列,然后将收到的数据包。由于IOKernel既要处理CPU核心的分配,又要处理网络数据包的转发,所以CPU核心的分配必须处理得很快,否则会降低数据处理的性能。
- 每个应用会有guaranteed cores以及burstable cores。前者可以理解为固定分配的,不用担心被抢占,而后者是根据需要分配的。一个kthread在自己的本地的runqueue中没有工作可以做的时候,代表这个进程在这个时间段内不需要这么多的CPU核心。应用会主动让出kthread,并通知IO Kernel。IOKernel可以在任何时候抢占一个burstable核心。
- 在一个数据包达到一个应用的时候,如果没有被分配的核心,IO Kernel会立即分配一个。IOKernel使用congestion detection算法。这个计算基于两个元素,排队的线程和排队的ingress的数据包。任何一个队列中的item出现在连续的两个interval的时候,表明这个item至少排队了5us。对于发现可能处理拥塞状态的应用,IO Kernel会分配额外的核心。这些队列就使用ring buffer实现。在这之中通过头尾指针就可以其队列中表现出不同的interval。
- 在具体分配给那一个核心的时候,IOKernel主要考虑三个因素。1. Hyper-threading efficiency,IO Kernel趋向于将分配在同一个物理核心的HyperThread上面,因为这样的缓存局部性更好。2. CaChe Locality,如果一个应用的数据已经在一个CPU核心的L1/L2中,则IOKernel会倾向于将其分配到对应的核心上面,3. Latency,在可能的情况下,肯定是优先选择分配空闲核心而不是忙的核心。
IOKernel忙轮询NIC的收入包队列,和应用的出队列,IOKernel可以直接将数据包传递给对应的应用。Shenango中,每个runtime都会配置自己的IP地址和Mac地址。在一个新的数据包达到的时候,通过参看数据包中的Mac地址即可得知对应的runtime。IOKernel通过RSS的方式在这个runtime中的CPU核心之间选择,将数据包放入其 ingress packet queue。engress队列也使用,轮询的方式可能导致很多的CPU占用,由于IOKernel可知kthread的活跃情况,它只需要轮询活跃的那一部分即可。
0x03 Runetime
Shenango的Runtime类似于一般的网络的API,这个和其它的kernel-bypass的网络栈强制使用和一般的API存在很多的区别不同。和library OS类似,runtime被链接在应用的地址空间之内。在runtime初始化之后,一般的syscall也是可以使用的,但是最好不要使用会Blocking的syscall。runtime会提供一个kernel-bypass的替代的版本。runtime在IOKernel动态分配的CPU核心上面进行调度操作。在runtime初始化的时候,它会注册若干的kthreads到IO Kernel和对应的共享内存的区域作为packet queue。在IOKernel分配一个新的核心的时候,它会唤醒一个对应rumtime的kthread,并绑定到指定CPU核心上面。这个的runtime的结构是每个thread一个队列,并加上work stealing机制来实现负载均衡。这个和GO的runtime类似。另外,runtime使用run-to-completion的机制,可以让一个uthread一直运行到它资源地让出CPU。这个机制加上借鉴了ZygOS中细粒度的work stealing的思路,显著地改善了尾延迟的表现,
When a uthread yields, any necessary register state is saved on the stack, allowing execution to resume later. When the yield is cooperative, we can save less register state because function call boundaries allow clobbering of some general purpose registers as well as all vector and floating point state
0x04 评估
这里的具体信息可以参看考[1],
Shinjuku: Preemptive Scheduling for μsecond-scale Tail Latency
0x10 引言
Shenango更像是在Arachne这样用户态线程为基础的架构上面的优化。而同样发表在NSDI ‘19上面的Shinjuku则是在IX这样基于硬件虚拟化这样的系统上面的优化。Shinjuku是一个单地址空间的操作系统,主要的研究点在于实现抢占式的调度,
Shinjuku provides significant tail latency and throughput improvements over IX and ZygOS for a wide range of workload scenarios. For the case of a RocksDB server processing both point and range queries, Shinjuku achieves up to 6.6× higher throughput and 88% lower tail latency.
0x11 基本架构
之前的ZygOS讨论了不同的调度方式对tail latency的影响。最好发现采用中性化的任务队列的 c-FCFS有着更好的负载均衡表现。这个调度方式刚好和前面的Shenango的每个线程/核心一个任务队列并辅之任务窃取机制相反。Shinjuku同样使用了中心话的任务队列,并支持抢占式的调度,所以将其称之为c-PRE方式。
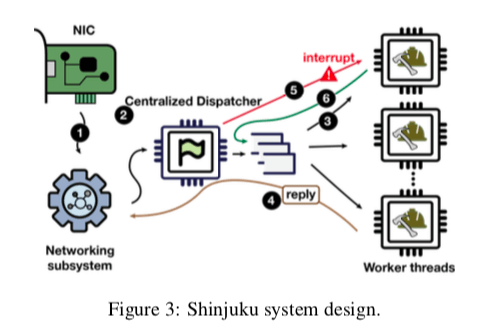
- Shinjuku的基本架构如下。进入的请求先被networking subsystem处理。这个网络子系统可以有指定的若干个核心实现,也可以使用像smartNIC的异构硬件来实现。当然,混合这些方式也是可以的。Shinjuku将未来子系统和调度分配的方式使得其容易组织起不同的网络协议。
- 之后,网络子系统将请求转给一个中心话的Dispatcher。这个Dispatcher将会将这些请求排队,并将这些请求转发给对用的Worker Threads。为了实现抢占式调度和重新调度,Dispatcher会生成一个context。将请求发送给Worker之后,Worker处理请求。Woker线程运行在一个指定的核心上面。在处理完成之后,回复的网络处理可以在网络子系统处理,也可以在Worker这里就处理。
- 对于抢占式的调度,Dispatcher通过时间戳来发送长时间运行的任务。需要进行抢占式调度的时候,Dispatcher会发送一个中断信号给对用的Worker线程。这个被抢占的请求会被重新排队。所以这里的抢占的效率和快速的上下文切换式Shinjuku设计的核心问题。
Fast Preemption
实现抢占最简单的方式是通过Linux Signal的方式,不过这种方式的缺点就是效率太低。直接使用inter-processor interrupts (IPIs)是一种比信号方式更快的思路。在x86处理器上面,IPI的实现通过Advanced Programmable Interrupt Controller (APIC)的方式。每个核心都有本地的APIC和一个IO APIC attach在系统的总线上面。可以通过写本地的APIC寄存器的方式将来实现传输中断信号。为了实现Shinjuku功能,这里拓展了Dune,使其支持虚拟化的本地APIC,
When a non-root thread on core A writes its virtual APIC to send interrupt number V to core B, this causes a VM exit to Dune running in root mode. Dune writes V to core B’s posted interrupt descriptor, and then uses the real APIC to send interrupt 242 to core B.
| Preemption Mechanism | Sender Cost | Receiver Cost | Total Latency |
|---|---|---|---|
| Linux Signal | 2084 | 2523 | 4950 |
| Vanilla IPI | 2081 | 2662 | 4219 |
| IPI Sender-only Exit | 2081 | 1212 | 2768 |
| IPI Receiver-only Exit | 298 | 2662 | 3433 |
| IPI No Exits | 298 | 1212 | 1993 |
-
当一个给特权态运行的线程通过写APIC像一个核心B发送中断数据V的时候,它会导致VM推出到Dune中,这个组件运行特权态,Dune会写入V到核心B的posted interrupt descriptor,然后使用实际的APIC发送242中断到核心B。这个动作导致B也发生VM exit到Dune中,之后进程中断处理,将中断数V转移到非特权态的应用中。
-
这里会造成两次的VM exit,所以看起来性能不是很好。为了优化这个问题,这里通过posted interrupts功能避免接收段的VM exit,发现不少的提升,
To enable posted interrupts, Dune on B configures its hardware-defined VM control structure (VMCS) to recognize interrupt 242 as the special posted interrupt notification vector. B also registers its posted interrupt descriptor with the VMCS.为了优化发送端的VM exit,这里选择信任Shinjuku dispatcher的方式,使得其可以直接访问非虚拟化的APIC。Shinjuku通过使用extended page table (EPT)的方式将其它核心的posted interrupt descriptors和本地的APIC’s registers映射到Shinjuku dispatcher物理地址空间中。这个性能提升也很明显。
Low-overhead Context Switch
这里也讨论了进行上下文切换方式的优化。最直接的方式就是使用swapcontext,这个在ucontext库中。但是发现这个函数的开销比较高。通过移除 signal mask,很显著的降低了操作的开销,主要是因为移除了这个操作需要的syscall操作。不过这个造成的一个负面影响就是同一应用的任务都必须使用同一个signal mask。之后通过优化main worker context不实用浮点指令,避免FP的restore的save操作。
| Mechanism | Linux process | Dune process |
|---|---|---|
| swapcontext | 985 | 2290 |
| No signal mask | 140 | 140 |
| No FP-restore | 36 | 36 |
| No FP-save | 109 | 109 |
0x12 抢占式调度
Shinjuku使用的是一个c-FCFS类似的调度方式。这里只要讨论了两种子类型的调度方式,
-
Single queue (SQ)策略,在这种方式下面,请求没有优先级的区别,所有的请求都放入同一个队列中。通过时间戳来探知长时间运行的任务,在必要的时候进行抢占的处理。
-
Multi queue (MQ),另外一个策略就是多队列的方式,这个需要网络子系统可以进行不同类似请求的辨别。多队列的主要目的还是引入优先级,因为不同类型的请求对SLO的要求不同。通过将不同优先级的任务保存在不同的队列,
The dispatcher maintains one queue per request type. If only one queue has pending requests, this policy operates just like the single queue policy described above. If more than one queue is non empty, the dispatcher must select a queue to serve when a worker becomes idle or a request is preempted.
0x13 评估
这里的具体信息可以参看[2].
参考
- Shenango: Achieving High CPU Efficiency for Latency-sensitive Datacenter Workloads, NSDI ‘19.
- Shinjuku: Preemptive Scheduling for μsecond-scale Tail Latency, NSDI ‘19.
