BTrDB: Optimizing Storage System Design for Timeseries Processing
0x00 引言
这篇Paper是关于专门为存储时序数据设计的一个树形的数据结构。这里举的一个例子就是电网中一类传感器的例子,这种传感器产生12个以120hz为频率的一个数据信息。时间精度比较高又100ns。这样的数据一般这样的一些特点,一个检测的数据称之为时间线,这类数据的时间线比较稳定,而且生命周期很长。而且数据频率和时间精度很高,另外数据传输的过程中,数据乱序经常出现,
... demonstrating a throughput of 53 million inserted values per second and 119 million queried values per second on a four-node cluster. The system achieves a 2.9x compression ratio and satisfies statistical queries spanning a year of data in under 200ms, as demonstrated on a year-long production deployment storing 2.1 trillion data points.
0x01 基本结构
BTrDB中一个时间序列的值可以看作是一个时间戳到值的一个序列,这个序列在BTrDB中会排好序。每个时间序列由一个UUID标识。BtrDB是一个带版本信息的数据存储,
InsertValues(UUID, [(time, value)]), 添加数据。每次添加的时候会创建一个新版本的数据;
GetRange(UUID, StartTime, EndTime, Version) → (Version, [(Time, Value)]) 查询一个时间线的一个时间范围内的数据
GetLatestVersion(UUID) → Version 获取最新的版本信息
GetStatisticalRange(UUID, StartTime, EndTime, Version, Resolution) → (Version, [(Time, Min, Mean, Max, Count)]) 获取一个时间段内一个时间序列的一些统计信息
GetNearestValue(UUID, Time, Version, Direction) → (Version, (Time, Value)) 获取当前数据
ComputeDiff(UUID, FromVersion, ToVersion, Resolution) → [(StartTime, EndTime)] 比较不同版本数据的差异
DeleteRange(UUID, StartTime, EndTime) 删除数据
Flush(UUID) 保证持久化
BTrDB基本上是一个树形的结构,一棵树表示了一个逻辑的时间范围,这里以Unix Epoch为0点前后的−2^60ns 到 3∗2^60ns。在纳秒的分辨率下面,这个范围大约是1933到2079年。下吗是一个0 到 16ns范围树结构的一个实例,子节点表示的范围是父节点的一个子范围。节点中可能存在空洞。多版本的设计中,在添加新版本的数据的时候,通过创建新版本的一个节点来实现。树结构中的Link会带有版本信息,一个子节点的指针是null但是带有版本信息的表明这个版本的数据已经被删除。处理子节点的地址和版本信息之外,中间的节点还保存了一些子节点的时间范围、一些聚合统计信息,如min, mean, max 和 count,等。这里子节点实际上可以看作是一个更高精度的数据信息,在查询处理的时候,出现中间的一个节点的精度满足查询的精度要求,就可以不去查询下面节点的数据了。BTrDB中间节点使用2 × 8 × K大小的中间节点,K为分叉数,2 × 8为一个指针信息和一个版本信息,另外统计信息为4 × 8 × K ,记录了min, mean, max和count。
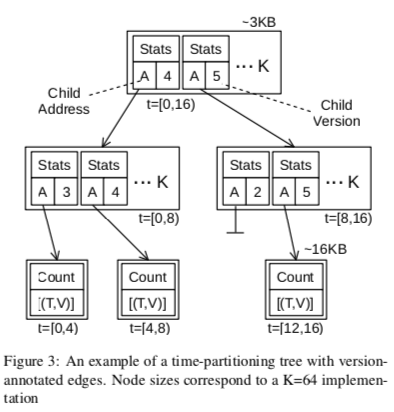
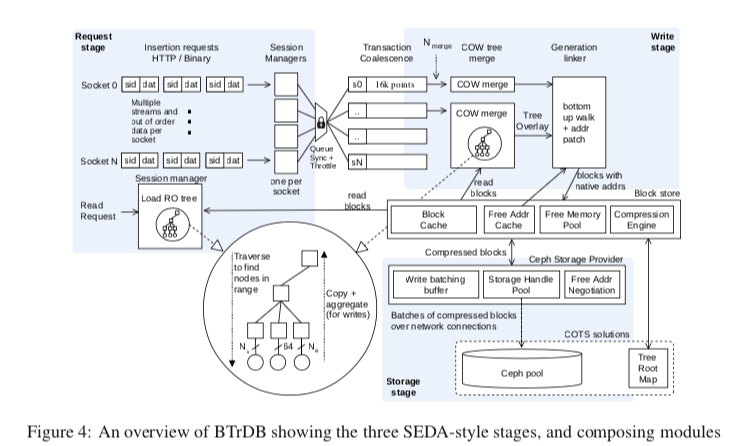
这样的设计下面可以看出来每个节点都是一个时间范围,其中root节点就代表了整颗树能够表示的范围。中间节点的子节点越多,子节点的精度就更大。而如果在指定的精度下面,节点越小,树的高度酒越大。在这样的结构中,添加操作就是根据时间,从root节点出发,一种找到对应的叶子节点,如果存在中间节点的对应的子节点没有创建,需要创建一个。在一个节点超过了预定义的大小的时候,需要进行分裂的操作。添加操作完成之后,在从底到上更新统计信息。在Request请求的部分,从多个Socket获取到的数据会根据UUID将其各类,然后被放到一个Buffer中,这里经过一个设定的时间后者是积累了一定量的数据之后进入到下一步操作。在COW阶段中需要用到的Block由下吗的Block Storage提供。这个Block Store类似于一个功能增强的Buffer Pool,处理Block Cache的功能之外,还包含数据压缩的功能。数据块压缩的时候使用常见的delta-delta压缩的方式。
0x02 评估
这里具体的信息可以参看[1].
Confluo: Distributed Monitoring and Diagnosis Stack for High-speed Networks
0x10 引言
Confluo也是一种用于保存某些时序数据类型的存储系统,还包含分析诊断的功能。Confluo面向的是一些这样的场景:数据产生类型与一些监控数据,数据只会追加写入不会更新和删除。每个数据都是定长的,而且只需要保存着原子性,不会有其它事务性的要求。这里的核心的内容就是一个Atomic MultiLog结构,专门为这样的场景设计,
Our evaluation results show that, for packet sizes 128B or larger, Confluo executes thousands of triggers and tens of filters at line rate (for 10Gbps links) using a single core.
0x11 基本设计
ConFluo的基本架构如下图所示。在对外的API上,支持filter、aggregate和trigger等,如下所示。
setup_packet_capture(fExpression, sampleRatio), Capture packet headers matching filter fExpression at sampleRatio.
filterId = add_filter(fExpression)
aggId = add_aggregate(filterId, aFunction)
trigId = install_trigger(aggId,condition,period)
remove_filter(filterId), remove_aggregate(aggId),
uninstall_trigger(trigId)
add_index(attribute)
Iterator<Header> it = query(fExpression,tLo,tHi)
agg = aggregate(fExpression,aFunction,tLo,tHi)
remove_index(attribute)
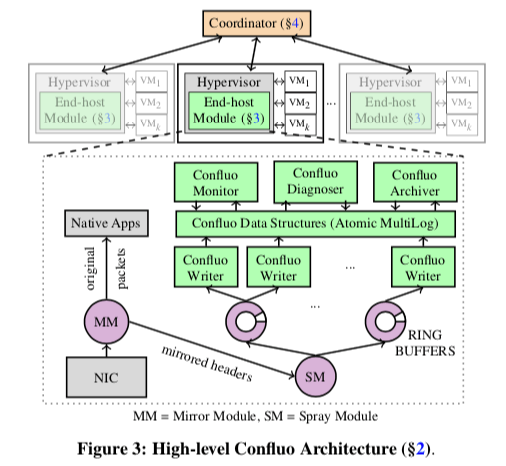
与这些接口相关的数据最终都会保存在Atomic MultiLog中。Atomic MultiLog的实现利用了现在的CPU提供的原子指令,如 AtomicLoad, AtomicStore, FetchAndAdd 和 CompareAndSwap。Atomic MultiLog另外的基础之一是Concurrent Logs。Concurrent Logs中常见的一种实现方式是维护一个writeTail,用于标记这个log的tail。在追加数据的时候,直接修改这个writetail一个需要的统计的量即可。在readTail的维护上面,也和这个writeTail的维护方式差不多。在单个的Concurrent Logs上面保证原子性相对来说比较简单,但这里使用了多个的Concurrent Logs,要保证在多个这样的结构上的原子性就困难一些。在Confluo中,有这样的一些Log,
-
HeaderLog,Paper中讨论的是网络数据的一些处理。这里的HeaderLog保存的是网络数据包的Header的原始数据。在这类数据中,但是定长的,结构固定。带有结构信息的话和一般的消息队列系统不一样,比如说Kafka。
-
IndexLog,这里的Index Log 为索引Header中的一些字段,比如IP Header中的srcIP, dstPort。这里使用 k-ary tree来作为索引结构,
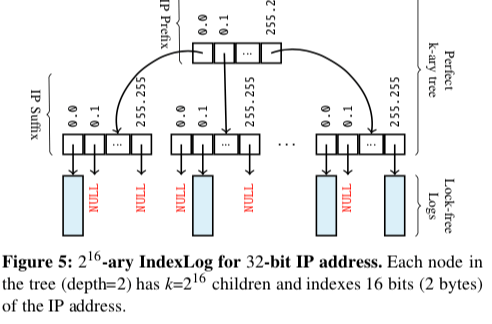
- FilterLog,是一个时间作为索引条件的结构,这里用于记录满足特定条件的记录位置的数据结构,如果满足srcIP==10.0.0.1 && dstPort==80。
- AggregateLog,和Index Log类似,不过要在k-ary tree的索引结构上面记录aggregates的值,比如aggregates。但是多个线程同时更新这些信息会导致加锁。这里的解决方式是thread-local的结构,只会在线程本地的结构上面修改这些信息。要查询这些信息的时候要将不同的线程的数据聚合在一起。
为了解决更新多个Log原子性和顺序的要求,这里使用HeaderLog作为 readTail 和 writeTail 作为全局的 readTail 和 writeTail,即globalReadTail 和 globalWriteTail。在更新操作的时候,使用FetchAndAdd更新globalWriteTail的值,在更新其它ring buffer的时候,再去更新对应的wrtieTail谢谢。在更完成全部的Log之后,在更新globalReadTail,这样写入的数据就对后面的查询可见了。其实也不是很难理解。emmmm,其它部分TOOD。
0x12 评估
这里的具体信息可以参看[2].
参考
- BTrDB: Optimizing Storage System Design for Timeseries Processing, FAST ‘16.
- Confluo: Distributed Monitoring and Diagnosis Stack for High-speed Networks, NSDI’19.
- Chronix: Long Term Storage and Retrieval Technology for Anomaly Detection in Operational Data, FAST ‘17.
